

2. 注意力机制的正式引入
前边我们通过机器翻译任务介绍了Attention机制的整体计算。但是还有点小尾巴没有展开,就是那个注意力打分函数的计算,现在我们将来讨论这个事情。但在讲这个函数之前,我们先来对上边的Attention机制的计算做个总结,图2详细地描述了Attention机制的计算原理。
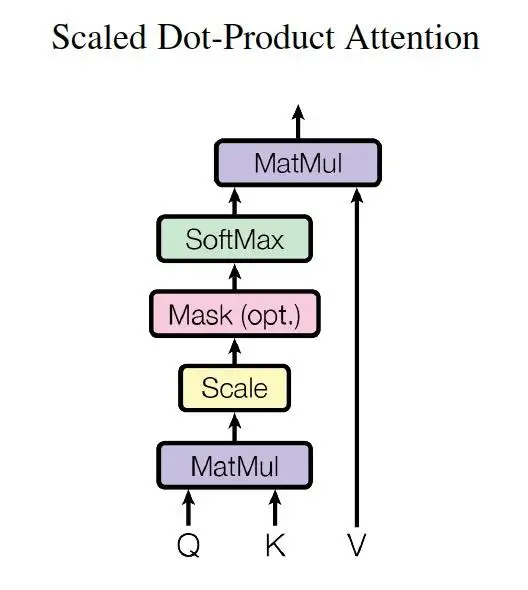

图2 Attention机制图
假设现在我们要对一组输入 H =[h 1 ,h 2 ,h 3 ,…,h n ]H=[h1,h2,h3,…,hn]使用Attention机制计算重要的内容,这里往往需要一个查询向量 q q(这个向量往往和你做的任务有关,比如机器翻译中用到的那个 q 2 q2 ) ,然后通过一个打分函数计算查询向量 q q 和每个输入 h i hi 之间的相关性,得出一个分数。接下来使用softmax对这些分数进行归一化,归一化后的结果便是查询向量 q q在各个输入 h i hi上的注意力分布 a =[a 1 ,a 2 ,a 3 ,…,a n ]a=[a1,a2,a3,…,an],其中每一项数值和原始的输入H =[h 1 ,h 2 ,h 3 ,…,h n ]H=[h1,h2,h3,…,hn]一一对应。以 a i ai 为例,相关计算公式如下:
[{a_i} = softmax(s({h_i},q)) = \frac{{exp(s({h_i},q))}}{{\sum\limits_{j = 1}^n e xp(s({h_j},q))}}]
最后根据这些注意力分布可以去有选择性的从输入信息 H H 中提取信息,这里比较常用的信息提取方式,是一种”软性”的信息提取(图2展示的就是一种”软性”注意力),即根据注意力分布对输入信息进行加权求和,最终的这个结果 c o n t e x t context 体现了模型当前应该关注的内容:
[context = \sum\limits_{i = 1}^n {{a_i}} \cdot {h_i}]
现在我们来解决之前一直没有展开的小尾巴-打分函数,它可以使用以下几种方式来计算:
- 加性模型: [s(h,q) = {v^T}tanh(Wh + Uq)]
- 点积模型: [s(h,q) = {h^T}q]
- 缩放点积模型: [s(h,q) = \frac{{{h^T}q}}{{\sqrt D }}]
- 双线性模型: [s(h,q) = {h^T}Wq]
以上公式中的参数 W W、U U和v v均是可学习的参数矩阵或向量,D D为输入向量的维度。下边我们来分析一下这些分数计算方式的差别。
加性模型引入了可学习的参数,将查询向量 q q 和原始输入向量 h h 映射到不同的向量空间后进行计算打分,显然相较于加性模型,点积模型具有更好的计算效率。
另外,当输入向量的维度比较高的时候,点积模型通常有比较大的方差,从而导致Softmax函数的梯度会比较小。因此缩放点积模型通过除以一个平方根项来平滑分数数值,也相当于平滑最终的注意力分布,缓解这个问题。
最后,双线性模型可以重塑为 [s({h_i},q) = {h^T}Wq = {h^T}({U^T}V)q = {(Uh)^T}(Vq)]
,即分别对查询向量 q q 和原始输入向量 h h进行线性变换之后,再计算点积。相比点积模型,双线性模型在计算相似度时引入了非对称性。
Original: https://www.cnblogs.com/beyoncewxm/p/16625206.html
Author: xiaomin_beyonce
Title: 经典注意力机制
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/566437/
转载文章受原作者版权保护。转载请注明原作者出处!