// onnx转换头文件
include "NvOnnxParser.h"
using namespace nvonnxparser;
using namespace std;
#define CHECK(status) \ do\ {\ auto ret = (status);\ if (ret != 0)\ {\ std::cerr << "Cuda failure: " << ret << std::endl;\ abort();\ }\ } while (0)struct Detection { //center_x center_y w h float bbox[4]; float conf; // bbox_conf * cls_conf int class_id; int index;};
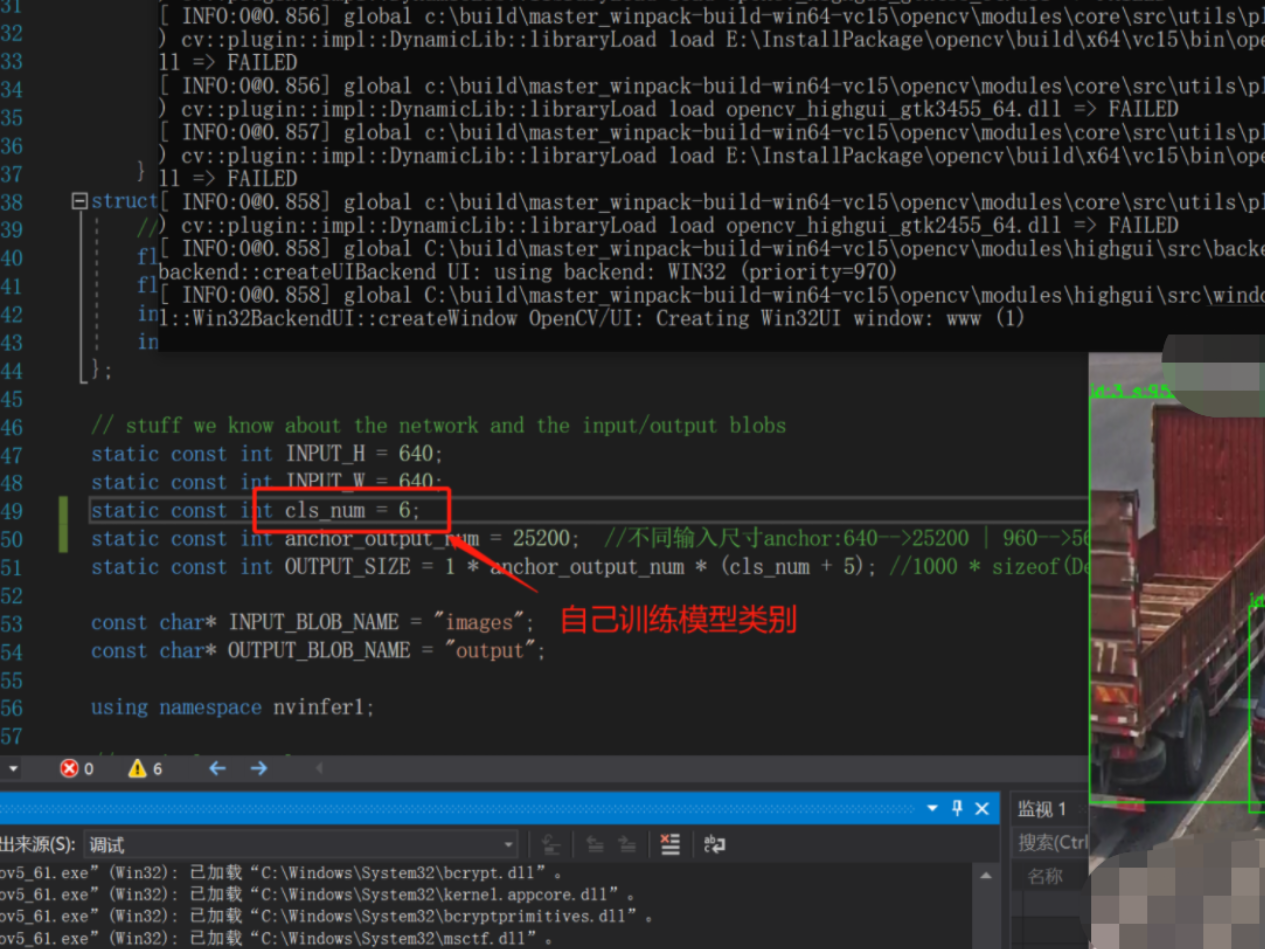
// stuff we know about the network and the input/output blobsstatic const int INPUT_H = 640;static const int INPUT_W = 640;static const int cls_num = 80;static const int anchor_output_num = 25200; //不同输入尺寸anchor:640-->25200 | 960-->56700static const int OUTPUT_SIZE = 1 anchor_output_num (cls_num+5); //1000 * sizeof(Detection) / sizeof(float) + 1;
const char INPUT_BLOB_NAME = "images";const char OUTPUT_BLOB_NAME = "output";
using namespace nvinfer1;
//static Logger gLogger;
//构建Loggerclass Logger : public ILogger{ void log(Severity severity, const char* msg) noexcept override { // suppress info-level messages if (severity <= Severity::kWARNING) std::cout << msg << std::endl; }} gLogger;
// Creat the engine using only the API and not any parser.ICudaEngine createEngine(unsigned int maxBatchSize, IBuilder builder, IBuilderConfig config){ const char onnx_path = "./best.onnx";
INetworkDefinition</span>* network = builder->createNetworkV2(<span>1U</span>); <span>//</span><span>此处重点1U为OU就有问题</span>
IParser parser = createParser(network, gLogger);
parser->parseFromFile(onnx_path, static_cast(ILogger::Severity::kWARNING));
//解析有错误将返回
for (int32_t i = 0; i < parser->getNbErrors(); ++i) { std::cout << parser->getError(i)->desc() << std::endl; }
std::cout << "successfully parse the onnx model" << std::endl;
</span><span>//</span><span> Build engine</span>
builder-><span>setMaxBatchSize(maxBatchSize);
config</span>->setMaxWorkspaceSize(<span>1</span> << <span>20</span><span>);
</span><span>//</span><span>config->setFlag(nvinfer1::BuilderFlag::kFP16); </span><span>//</span><span> 设置精度计算
</span><span>//</span><span>config->setFlag(nvinfer1::BuilderFlag::kINT8);</span>
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *<span>config);
std::cout </span><< <span>"</span><span>successfully convert onnx to engine!!! </span><span>"</span> <<<span> std::endl;
</span><span>//</span><span>销毁</span>
network-><span>destroy();
parser</span>-><span>destroy();
</span><span>return</span><span> engine;
}
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream)
{
</span><span>//</span><span> Create builder</span>
IBuilder* builder =<span> createInferBuilder(gLogger);
IBuilderConfig</span>* config = builder-><span>createBuilderConfig();
</span><span>//</span><span> Create model to populate the network, then set the outputs and create an engine</span>
ICudaEngine* engine =<span> createEngine(maxBatchSize, builder, config);
assert(engine </span>!=<span> nullptr);
</span><span>//</span><span> Serialize the engine</span>
(*modelStream) = engine-><span>serialize();
</span><span>//</span><span> Close everything down</span>
engine-><span>destroy();
builder</span>-><span>destroy();
config</span>-><span>destroy();
}
void doInference(IExecutionContext& context, float input, float output, int batchSize)
{
const ICudaEngine& engine = context.getEngine();
// Pointers to input and output device buffers to pass to engine.
</span><span>//</span><span> Engine requires exactly IEngine::getNbBindings() number of buffers.</span>
assert(engine.getNbBindings() == <span>2</span><span>);
</span><span>void</span>* buffers[<span>2</span><span>];
</span><span>//</span><span> In order to bind the buffers, we need to know the names of the input and output tensors.
</span><span>//</span><span> Note that indices are guaranteed to be less than IEngine::getNbBindings()</span>
<span>const</span> <span>int</span> inputIndex =<span> engine.getBindingIndex(INPUT_BLOB_NAME);
</span><span>const</span> <span>int</span> outputIndex =<span> engine.getBindingIndex(OUTPUT_BLOB_NAME);
</span><span>//</span><span>const int inputIndex = 0;
</span><span>//</span><span>const int outputIndex = 1;
</span><span>//</span><span> Create GPU buffers on device</span>
cudaMalloc(&buffers[inputIndex], batchSize * <span>3</span> * INPUT_H * INPUT_W * <span>sizeof</span>(<span>float</span><span>));
cudaMalloc(</span>&buffers[outputIndex], batchSize * OUTPUT_SIZE * <span>sizeof</span>(<span>float</span><span>));
</span><span>//</span><span> Create stream</span>
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream));
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CHECK(cudaMemcpyAsync(buffers[inputIndex], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CHECK(cudaMemcpyAsync(output, buffers[outputIndex], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
// Release stream and buffers
cudaStreamDestroy(stream);
CHECK(cudaFree(buffers[inputIndex]));
CHECK(cudaFree(buffers[outputIndex]));
}
int get_trtengine() {
IHostMemory</span>*<span> modelStream{ nullptr };
APIToModel(</span><span>1</span>, &<span>modelStream);
assert(modelStream </span>!=<span> nullptr);
std::ofstream p(</span><span>"</span><span>./best.engine</span><span>"</span><span>, std::ios::binary);
</span><span>if</span> (!<span>p)
{
std::cerr </span><< <span>"</span><span>could not open plan output file</span><span>"</span> <<<span> std::endl;
</span><span>return</span> -<span>1</span><span>;
}
p.write(reinterpret_cast</span><<span>const</span> <span>char</span>*>(modelStream->data()), modelStream-><span>size());
modelStream</span>-><span>destroy();
</span><span>return</span> <span>0</span><span>;
}
//加工图片变成拥有batch的输入, tensorrt输入需要的格式,为一个维度
void ProcessImage(cv::Mat image, float input_data[]) {
//只处理一张图片,总之结果为一维[batch3INPUT_W*INPUT_H]
//以下代码为投机取巧了
cv::resize(image, image, cv::Size(INPUT_W, INPUT_H), 0, 0, cv::INTER_LINEAR);
std::vector<:mat> InputImage;
InputImage.push_back(image);
</span><span>int</span> ImgCount =<span> InputImage.size();
</span><span>//</span><span>float input_data[BatchSize * 3 * INPUT_H * INPUT_W];</span>
<span>for</span> (<span>int</span> b = <span>0</span>; b < ImgCount; b++<span>) {
cv::Mat img </span>=<span> InputImage.at(b);
</span><span>int</span> w =<span> img.cols;
</span><span>int</span> h =<span> img.rows;
</span><span>int</span> i = <span>0</span><span>;
</span><span>for</span> (<span>int</span> row = <span>0</span>; row < h; ++<span>row) {
uchar</span>* uc_pixel = img.data + row *<span> img.step;
</span><span>for</span> (<span>int</span> col = <span>0</span>; col < INPUT_W; ++<span>col) {
input_data[b </span>* <span>3</span> * INPUT_H * INPUT_W + i] = (<span>float</span>)uc_pixel[<span>2</span>] / <span>255.0</span><span>;
input_data[b </span>* <span>3</span> * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (<span>float</span>)uc_pixel[<span>1</span>] / <span>255.0</span><span>;
input_data[b </span>* <span>3</span> * INPUT_H * INPUT_W + i + <span>2</span> * INPUT_H * INPUT_W] = (<span>float</span>)uc_pixel[<span>0</span>] / <span>255.0</span><span>;
uc_pixel </span>+= <span>3</span><span>;
</span>++<span>i;
}
}
}
}
//******* NMS code *******//
/
struct Detection {
//center_x center_y w h
float bbox[4];
float conf; // bbox_conf * cls_conf
int class_id;
int index;
};
/
struct Bbox {
int x;
int y;
int w;
int h;
};
float iou(Bbox box1, Bbox box2) {
</span><span>int</span> x1 =<span> max(box1.x, box2.x);
</span><span>int</span> y1 =<span> max(box1.y, box2.y);
</span><span>int</span> x2 = min(box1.x + box1.w, box2.x +<span> box2.w);
</span><span>int</span> y2 = min(box1.y + box1.h, box2.y +<span> box2.h);
</span><span>int</span> w = max(<span>0</span>, x2 -<span> x1);
</span><span>int</span> h = max(<span>0</span>, y2 -<span> y1);
</span><span>float</span> over_area = w *<span> h;
</span><span>return</span> over_area / (box1.w * box1.h + box2.w * box2.h -<span> over_area);
}
int get_max_index(vector pre_detection) {
//获得最佳置信度的值,并返回对应的索引值
int index;
float conf;
if (pre_detection.size() > 0) {
index = 0;
conf = pre_detection.at(0).conf;
for (int i = 0; i < pre_detection.size(); i++) {
if (conf < pre_detection.at(i).conf) {
index = i;
conf = pre_detection.at(i).conf;
}
}
return index;
}
else {
return -1;
}
}
bool judge_in_lst(int index, vector<int> index_lst) {
//若index在列表index_lst中则返回true,否则返回false
if (index_lst.size() > 0) {
for (int i = 0; i < index_lst.size(); i++) {
if (index == index_lst.at(i)) {
return true;
}
}
}
return false;
}
vector<int> nms(vector pre_detection, float iou_thr)
{
/*
返回需保存box的pre_detection对应位置索引值
</span><span>*/</span>
<span>int</span><span> index;
vector</span><detection><span> pre_detection_new;
</span><span>//</span><span>Detection det_best;</span>
Bbox box_best, box;
float iou_value;
vector<int> keep_index;
vector<int> del_index;
bool keep_bool;
bool del_bool;
</span><span>if</span> (pre_detection.size() > <span>0</span><span>) {
pre_detection_new.clear();
</span><span>//</span><span> 循环将预测结果建立索引</span>
<span>for</span> (<span>int</span> i = <span>0</span>; i < pre_detection.size(); i++<span>) {
pre_detection.at(i).index </span>=<span> i;
pre_detection_new.push_back(pre_detection.at(i));
}
</span><span>//</span><span>循环便利获得保留box位置索引-相对输入pre_detection位置</span>
<span>while</span> (pre_detection_new.size() > <span>0</span><span>) {
index </span>=<span> get_max_index(pre_detection_new);
</span><span>if</span> (index >= <span>0</span><span>) {
keep_index.push_back(pre_detection_new.at(index).index); </span><span>//</span><span>保留索引位置
</span><span>//</span><span> 更新最佳保留box</span>
box_best.x = pre_detection_new.at(index).bbox[<span>0</span><span>];
box_best.y </span>= pre_detection_new.at(index).bbox[<span>1</span><span>];
box_best.w </span>= pre_detection_new.at(index).bbox[<span>2</span><span>];
box_best.h </span>= pre_detection_new.at(index).bbox[<span>3</span><span>];
</span><span>for</span> (<span>int</span> j = <span>0</span>; j < pre_detection.size(); j++<span>) {
keep_bool </span>=<span> judge_in_lst(pre_detection.at(j).index, keep_index);
del_bool </span>=<span> judge_in_lst(pre_detection.at(j).index, del_index);
</span><span>if</span> ((!keep_bool) && (!del_bool)) { <span>//</span><span>不在keep_index与del_index才计算iou</span>
box.x = pre_detection.at(j).bbox[<span>0</span><span>];
box.y </span>= pre_detection.at(j).bbox[<span>1</span><span>];
box.w </span>= pre_detection.at(j).bbox[<span>2</span><span>];
box.h </span>= pre_detection.at(j).bbox[<span>3</span><span>];
iou_value </span>=<span> iou(box_best, box);
</span><span>if</span> (iou_value ><span> iou_thr) {
del_index.push_back(j); </span><span>//</span><span>记录大于阈值将删除对应的位置</span>
}
}
}
</span><span>//</span><span>更新pre_detection_new</span>
pre_detection_new.clear();
for (int j = 0; j < pre_detection.size(); j++) {
keep_bool = judge_in_lst(pre_detection.at(j).index, keep_index);
del_bool = judge_in_lst(pre_detection.at(j).index, del_index);
if ((!keep_bool) && (!del_bool)) {
pre_detection_new.push_back(pre_detection.at(j));
}
}
}
}
}
del_index.clear();
del_index.shrink_to_fit();
pre_detection_new.clear();
pre_detection_new.shrink_to_fit();
</span><span>return</span><span> keep_index;
}
vector postprocess(float prob, float conf_thr = 0.2, float nms_thr = 0.4) {
/
#####################此函数处理一张图预测结果#########################
prob为[x y w h score multi-pre] 如80类-->(1,anchor_num,85)
</span><span>*/</span><span>
vector</span><detection><span> pre_results;
vector</span><<span>int</span>><span> nms_keep_index;
vector</span><detection><span> results;
</span><span>bool</span><span> keep_bool;
Detection pre_res;
</span><span>float</span><span> conf;
</span><span>int</span><span> tmp_idx;
</span><span>float</span><span> tmp_cls_score;
</span><span>for</span> (<span>int</span> i = <span>0</span>; i < anchor_output_num; i++<span>) {
tmp_idx </span>= i * (cls_num + <span>5</span><span>);
pre_res.bbox[</span><span>0</span>] = prob[tmp_idx + <span>0</span><span>];
pre_res.bbox[</span><span>1</span>] = prob[tmp_idx + <span>1</span><span>];
pre_res.bbox[</span><span>2</span>] = prob[tmp_idx + <span>2</span><span>];
pre_res.bbox[</span><span>3</span>] = prob[tmp_idx + <span>3</span><span>];
conf </span>= prob[tmp_idx + <span>4</span>]; <span>//</span><span>是为目标的置信度</span>
tmp_cls_score = prob[tmp_idx + <span>5</span>] *<span> conf;
pre_res.class_id </span>= <span>0</span><span>;
pre_res.conf </span>= <span>0</span><span>;
</span><span>for</span> (<span>int</span> j = <span>1</span>; j < cls_num; j++<span>) {
tmp_idx </span>= i * (cls_num + <span>5</span>) + <span>5</span> + j; <span>//</span><span>获得对应类别索引</span>
<span>if</span> (tmp_cls_score < prob[tmp_idx] *<span> conf)
{
tmp_cls_score </span>= prob[tmp_idx] *<span> conf;
pre_res.class_id </span>=<span> j;
pre_res.conf </span>=<span> tmp_cls_score;
}
}
</span><span>if</span> (conf >=<span> conf_thr) {
pre_results.push_back(pre_res);
}
}
</span><span>//</span><span>使用nms</span>
nms_keep_index=<span>nms(pre_results,nms_thr);
</span><span>for</span> (<span>int</span> i = <span>0</span>; i < pre_results.size(); i++<span>) {
keep_bool </span>=<span> judge_in_lst(i, nms_keep_index);
</span><span>if</span><span> (keep_bool) {
results.push_back(pre_results.at(i));
}
}
pre_results.clear();
pre_results.shrink_to_fit();
nms_keep_index.clear();
nms_keep_index.shrink_to_fit();
</span><span>return</span><span> results;
}
cv::Mat draw_rect(cv::Mat image, vector results) {
/*
image 为图像
struct Detection {
float bbox[4]; //center_x center_y w h
float conf; // 置信度
int class_id; //类别id
int index; //可忽略
};
</span><span>*/</span>
<span>float</span><span> x;
</span><span>float</span><span> y;
</span><span>float</span><span> y_tmp;
</span><span>float</span><span> w;
</span><span>float</span><span> h;
</span><span>string</span><span> info;
cv::Rect rect;
</span><span>for</span> (<span>int</span> i = <span>0</span>; i < results.size(); i++<span>) {
x </span>= results.at(i).bbox[<span>0</span><span>];
y</span>= results.at(i).bbox[<span>1</span><span>];
w</span>= results.at(i).bbox[<span>2</span><span>];
h</span>=results.at(i).bbox[<span>3</span><span>];
x </span>= (<span>int</span>)(x - w / <span>2</span><span>);
y </span>= (<span>int</span>)(y - h / <span>2</span><span>);
w </span>= (<span>int</span><span>)w;
h </span>= (<span>int</span><span>)h;
info </span>= <span>"</span><span>id:</span><span>"</span><span>;
info.append(to_string(results.at(i).class_id));
info.append(</span><span>"</span><span> s:</span><span>"</span><span>);
info.append( to_string((</span><span>int</span>)(results.at(i).conf*<span>100</span><span>) ) );
info.append(</span><span>"</span><span>%</span><span>"</span><span>);
rect</span>=<span> cv::Rect(x, y, w, h);
cv::rectangle(image, rect, cv::Scalar(</span><span>0</span>, <span>255</span>, <span>0</span>), <span>1</span>, <span>1</span>, <span>0</span>);<span>//</span><span>矩形的两个顶点,两个顶点都包括在矩形内部</span>
cv::putText(image, info, cv::Point(x, y), cv::FONT_HERSHEY_SIMPLEX, <span>0.4</span>, cv::Scalar(<span>0</span>, <span>255</span>, <span>0</span>), <span>0.4</span>, <span>1</span>, <span>false</span><span>);
}
</span><span>return</span><span> image;
}
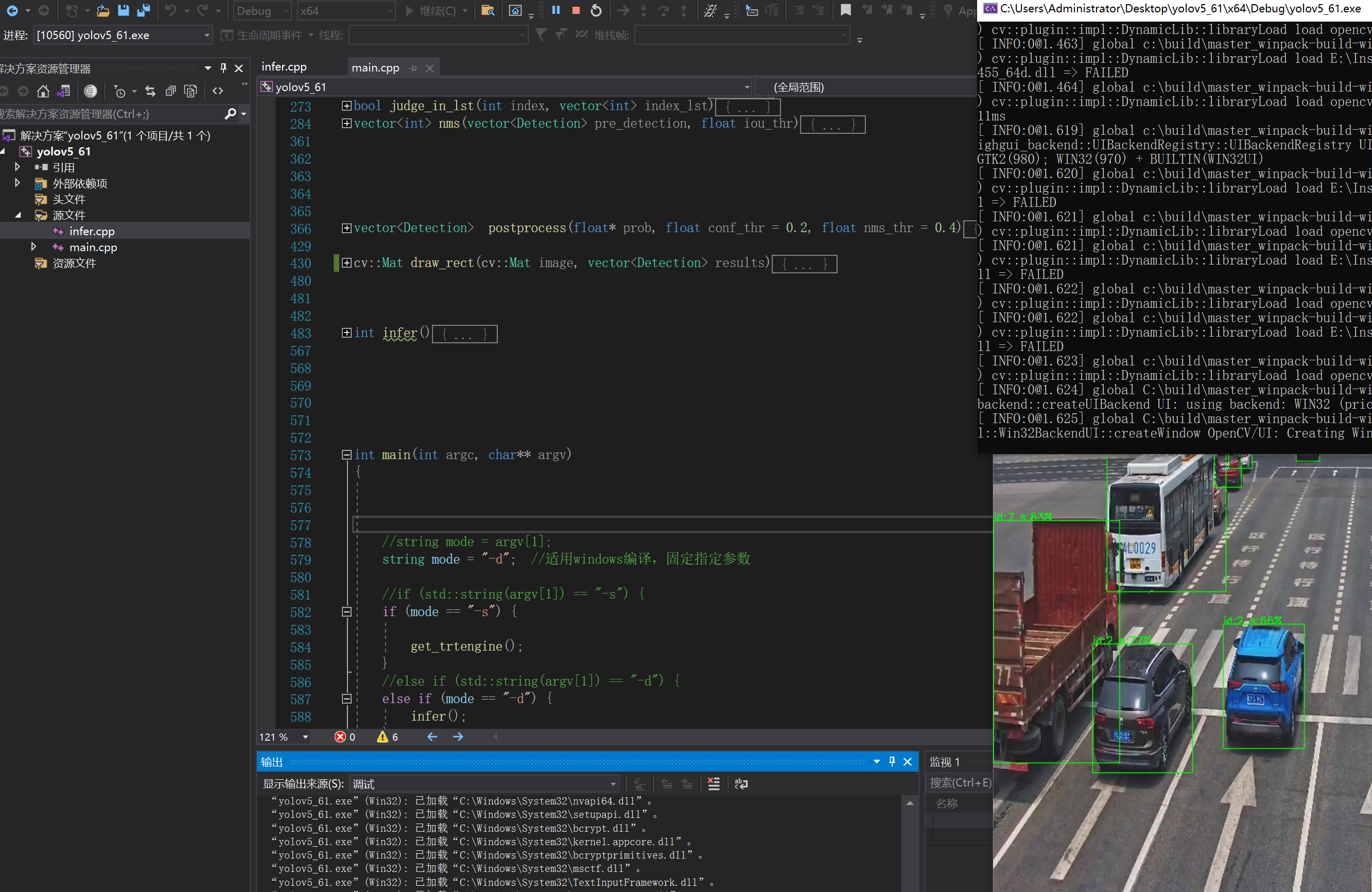
int infer() {
</span><span>//</span><span>加载engine引擎</span>
<span>char</span>*<span> trtModelStream{ nullptr };
size_t size{ </span><span>0</span><span> };
std::ifstream file(</span><span>"</span><span>./best.engine</span><span>"</span><span>, std::ios::binary);
</span><span>if</span><span> (file.good()) {
file.seekg(</span><span>0</span><span>, file.end);
size </span>=<span> file.tellg();
file.seekg(</span><span>0</span><span>, file.beg);
trtModelStream </span>= <span>new</span> <span>char</span><span>[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
}
</span><span>//</span><span>反序列为engine,创建context</span>
IRuntime runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine engine = runtime->deserializeCudaEngine(trtModelStream, size, nullptr);
assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
</span><span>//</span><span>*********************推理-循环推理*********************</span><span>//
<span>float</span> time_read_img = <span>0.0</span><span>;
</span><span>float</span> time_infer = <span>0.0</span><span>;
</span><span>float</span><span> prob[OUTPUT_SIZE];
vector</span><detection><span> results;
</span><span>for</span> (<span>int</span> i = <span>0</span>; i < <span>1000</span>; i++<span>) {
</span><span>//</span><span> 处理图片为固定输出</span>
auto start = std::chrono::system_clock::now(); //时间函数
std::string path = "./7.jpg";
std::cout << "img_path=" << path << endl;
static float data[3 * INPUT_H * INPUT_W];
cv::Mat img = cv::imread(path);
ProcessImage(img, data);
auto end </span>=<span> std::chrono::system_clock::now();
time_read_img </span>= std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() +<span> time_read_img;
</span><span>//</span><span>Run inference</span>
start = std::chrono::system_clock::now(); <span>//</span><span>时间函数</span>
doInference(*context, data, prob, <span>1</span><span>);
end </span>=<span> std::chrono::system_clock::now();
time_infer </span>= std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() +<span> time_infer;
std::cout </span><< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << <span>"</span><span>ms</span><span>"</span> <<<span> std::endl;
</span><span>//</span><span>输出后处理
</span><span>//</span><span>std::cout <<"prob="<<prob>
results.clear();
results=postprocess(prob, 0.3, 0.4);
cv::resize(img, img, cv::Size(INPUT_W, INPUT_H), </span><span>0</span>, <span>0</span><span>, cv::INTER_LINEAR);
img</span>=<span>draw_rect(img,results);
cv::imshow(</span><span>"</span><span>www</span><span>"</span><span>, img);
cv::waitKey(</span><span>0</span><span>);
cout </span><< <span>"</span><span>ok</span><span>"</span> <<<span> endl;
}
std::cout </span><< <span>"</span><span>C++ 2engine</span><span>"</span> << <span>"</span><span>mean read img time =</span><span>"</span> << time_read_img / <span>1000</span> << <span>"</span><span>ms\t</span><span>"</span> << <span>"</span><span>mean infer img time =</span><span>"</span> << time_infer / <span>1000</span> << <span>"</span><span>ms</span><span>"</span> <<<span> std::endl;
</span><span>//</span><span> Destroy the engine</span>
context-><span>destroy();
engine</span>-><span>destroy();
runtime</span>-><span>destroy();
</span><span>return</span> <span>0</span><span>;
}
int main(int argc, char** argv)
{
</span><span>//</span><span>string mode = argv[1];</span>
<span>string</span> mode = <span>"</span><span>-d</span><span>"</span>; <span>//</span><span>适用windows编译,固定指定参数
</span><span>//</span><span>if (std::string(argv[1]) == "-s") {</span>
<span>if</span> (mode == <span>"</span><span>-s</span><span>"</span><span>) {
get_trtengine();
}
</span><span>//</span><span>else if (std::string(argv[1]) == "-d") {</span>
<span>else</span> <span>if</span> (mode == <span>"</span><span>-d</span><span>"</span><span>) {
infer();
}
</span><span>else</span><span> {
</span><span>return</span> -<span>1</span><span>;
}
</span><span>return</span> <span>0</span><span>;
}