

STATA是一个数据统计软件,正如它的名字一样,STATA=statistic+data。STATA软件的功能和matlab类似,也可以用代码实现数据的统计与可视化。但几乎只能进行整行整列的数据处理,且每次只能加载处理一个数据矩阵,灵活性和全面性比不过matlab。那我为什么要用STATA呢?这是因为我选修了这门课,水一下学分。当然,相比matlab,它在数据处理方面,也有一些方便之处。下面记录STATA的一些常用的处理、统计、可视化方法。
基本命令
STATA命令的语法大部分是这样的:命令(空格)待处理的数据名(逗号)可选的一些参数。
读取软件自带数据集 sysuse
首先读取STATA自带的样例数据:
sysuse auto, clear
其中sysuse是一个命令,auto是汽车数据集的名称,clear是在读取数据之前先清空内存中已读取的数据。之后可以在变量窗口看到读取的变量。实际上这里的变量就是excel列表中的列标,每个变量代表一个列标。然后每个列标都有它对应的属性,属性定义了每列数据的类型和一些信息等。如下图:


浏览数据集 br
用br命令(等同于browse,STATA要弄一个简写让你更方便一些,然而让初学者很烦,可读性很差,弄巧成拙)可以查看所读取的表格:
br
如下图所示:

获取数据基本统计信息 sum codebook tabstat
summarize可以看表格的一些统计信息、codebook则是对表格的各列进行统计。它们后面可以跟着列名,则只显示这几列的信息,否则显示所有列:
summarize price mpg
codebook rep78
如下图所示:

tabstat可计算某种统计值,统计值种类比sum和codebook多,当做print来用吧:
tabstat price, by(rep78) stat(std max min)
以上显示车价格,在rep78的各个条件下的标准差、最大值和最小值。想要其他统计值,用help查看简写方法╮(╯▽╰)╭。
变量生成与替换 gen egen
gen和egen用于生成变量,gen是一对一生成,egen是一对多生成(比如max()值会赋值到每一行上)。如:
gen test1 = 2*price
egen test2 = max(price)
replace用于变量的替换,如:
replace test1 = test2 in 1/10
将test1的前10行数据替换为test2。其中的in在很多其他对行进行操作的命令中也可以使用。
另外要注意的是,不像matlab,STATA中的操作不能直接使用,必须要进行赋值,也就是用gen等命令生成某列,否则会报错。
基于某列取值下的分析 by
如果想在某列的各个不同的取值下,对其它列进行分析,可以用by,用法如下:
by foreign, sort: sum price
表示在foreign的各个取值下,获取price一些基本统计信息(sum就是summarize)。其中,如果by后面的变量没有排序,则必须要加sort,会先对其进行排序,否则会出错(默认排序不就行了?)。
如果想在某列特定取值下进行分析,可以用if:
sum price if foreign == 0
安装外部命令
STATA的命令是很分散的,不像python、matlab把相似的命令、处理方法都打包在一块儿。所以有些外部命令没得用,只能一个一个安装。用help查询相关命令,然后进行安装:
help graph3d
统计命令
下面的命令使用软件自带的auto数据集。
数量统计tabulate
统计某列或某两列中不同取值的数量,用法就是后面跟着一个或两个变量:
tabulate mpg
tabulate mpg rep78
两个以上变量会报错。
相关性分析correlate
correlate分析变量的相关性,可以输入多个变量,用法如下:
correlate mpg price rep78

二维可视化twoway
twoway进行二维可视化,后面每个括号内都能画一个相应的可视化图。如下所示:
twoway (scatter length mpg) (lfit length mpg)
表示以length为y轴,mpg为x轴,绘制散点图和拟合一元一次方程。可视化结果如下:
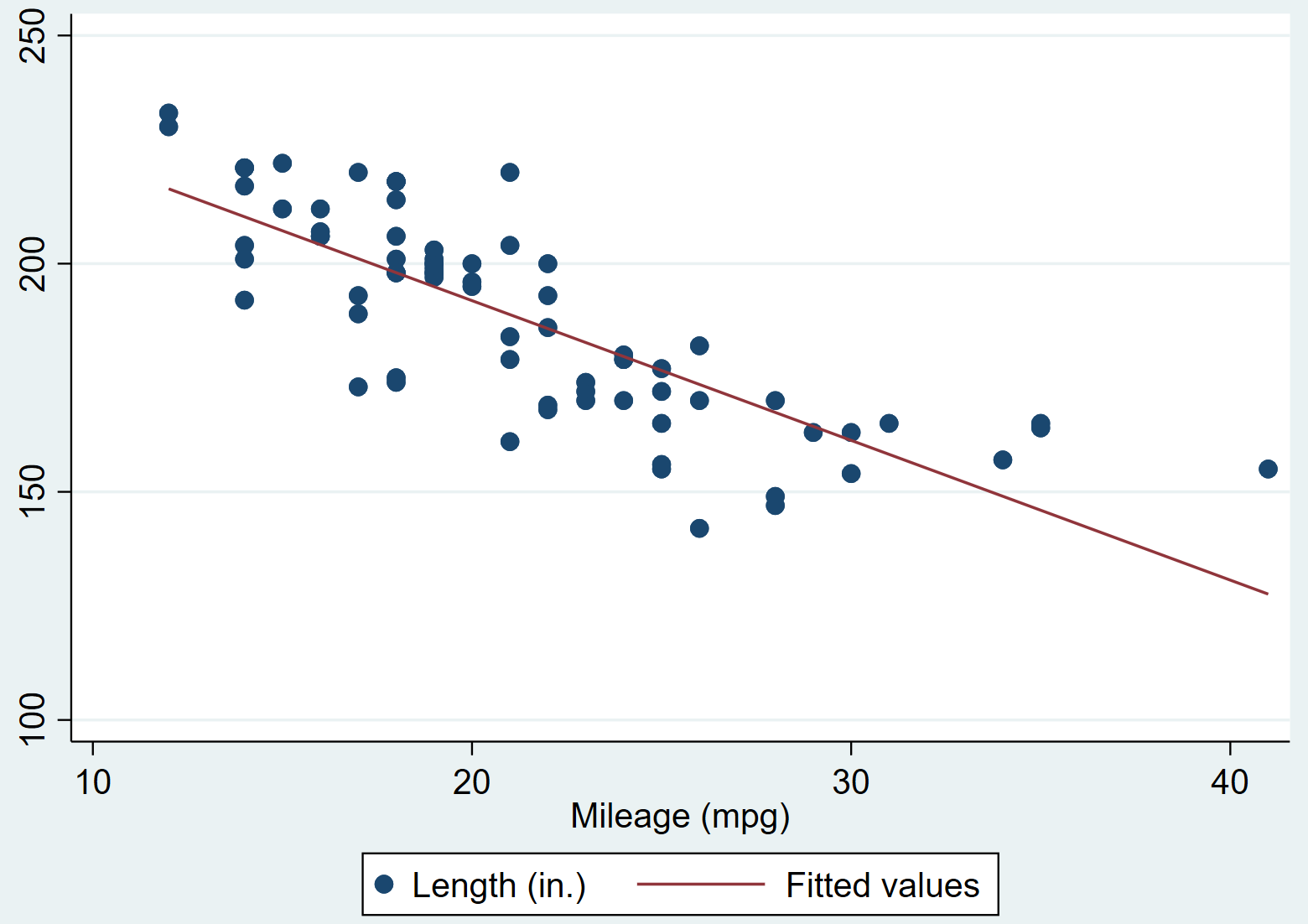
再加by可以在某个变量的各个取值下分别进行可视化:
twoway (scatter length weight) (lfit length weight), by(foreign)

回归regress
基本用法
使用几列数据对某列数据进行线性回归。比如,使用mpg、rep78、length作为因变量,对price进行回归,用法如下:
regress price mpg rep78 length
结果:

我们可以进行一个测试,创建test变量为price、mpg、weight的线性和,然后进行回归:
gen test = price*2+mpg*3+weight*456+789
regress test price mpg weight
结果:
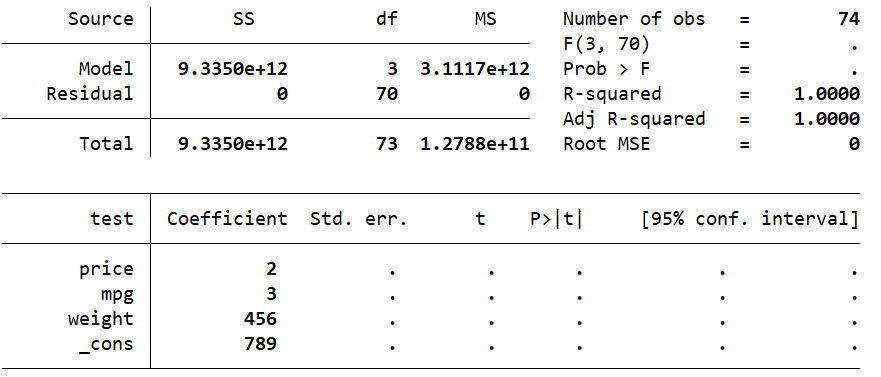
可以看出线性回归得到的系数与创建的一模一样。之后还可以使用predict创建回归值和回归偏差:
predict test_hat
predict test_res, res
结果如下:

二次以上的回归方式
如果想进行二次回归,可以先创建因变量的平方,然后使用一次、二次变量作为因变量进行回归:
gen weight2 = weight^2
regress mpg weight weight2 foreign
predict mpg_hat
sort weight
twoway (scatter mpg weight) (line mpg_hat weight), by(foreign)
分别按国内外汽车进行了车重和油耗的二次关系的统计,结果如下:

Original: https://www.cnblogs.com/qizhou/p/16712549.html
Author: 颀周
Title: STATA数据统计软件学习记录
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/565898/
转载文章受原作者版权保护。转载请注明原作者出处!