

- Fink简介
- 简单入门
- Flink安装部署
- Standalone模式
- Yarn模式
- Kubernetes部署
- Flink运行架构
- 运行时四大组件
- 任务提交流程
- 任务调度原理
- Flink流处理API
- 执行环境(Environment)
- 数据源(Source)
- 转换算子(Transform)
- Fink支持的数据类型
- 自定义函数(UDF,User-Defined Function)
- 数据输出(Sink)
- Flink Window API
- 窗口分类
- 窗口分配器(Window assigner)
- 窗口函数(Window function)
- Flink时间语义与Watermark(水印)
- 时间语义
- Watermark
- ProcessFunction API(底层API)
- Flink状态管理&容错机制(State & Fault Tolerance)
- flink中的State
- Queryable State
- Flink检查点(Checkpointing)
- Flink的状态一致性
- Table API 和 Flink SQL
- 总结
Fink简介
- flink起源和设计理念
- 快速,灵活
- 具体定位:Apache Flink是一个框架和分布式处理引擎,用于对有界和无界数据流进行有状态计算。flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
- flink的应用
- 典型应用场景:事件驱动型,分析处理型,数据管道型(ETL)
- 流式数据处理的发展和演变
- flink的特性总结
- 低延迟和高吞吐,精确一次性语义保证,API灵活,时间语义,状态编程
简单入门
- 安装nc:https://eternallybored.org/misc/netcat/ ,下载解压,配置到环境变量path,cmd使用
nc -lp port即可,使用nc -Lp port当文本流关闭时重新监听。linux自带nc,使用nc -lk port - 批处理WordCount:获取环境、获取批数据、操作数据
- 流处理WordCount:获取环境、获取流数据、操作数据、提交执行(会阻塞)
- 设置并行度
ParameterTool.fromArgs(args)从args获取参数- 设置共享组,默认default,同一个共享组的使用同一个slot,后一步没有设置则使用与前一个相同的共享组。
任务需要的slot是所有不同共享组的最大并行度的和
其他:
- flink底层使用的akka是使用scala写的,所以需要依赖scala,除了java,也提供了scala的api
- pom,核心依赖最好使用provided的scope,如果要在本机运行,在运行配置中,
modify optioins选项要勾选Include dependencies with "Provided" scope
org.apache.flink
flink-java
1.10.1
org.apache.flink
flink-streaming-java_2.12
1.10.1
官网下载:https://flink.apache.org/downloads.html#all-stable-releases
- binaries是安装包,里面有些是带hadoop的,带有hadoop的依赖支持(yarn模式),后续版本如果需要hadoop支持可单独下载,将jar包放入flink的lib下,也可以自己编译指定hadoop版本的依赖,编译过程参考链接
- flink-conf.yaml配置
jobmanager.rpc.address: localhost # jobmanager的通信地址
jobmanager.rpc.port: 6123 # jobmanager的通信端口
jobmanager.heap.size: 1024m # jobmanager堆大小
taskmanager.memory.process.size: 1728m # taskManager的处理内存,包括jvm元空间和堆外内存
taskmanager.memory.flink.size: 1280m # flink内存,它不包括jvm元空间和堆外内存,不建议同时使用这个和上面的这个
taskmanager.numberOfTaskSlots: 1 # 一个TaskManager可以并行执行的数量
parallelism.default: 1 # 程序的默认并行度
- 其他配置
- conf/master,指定jobManager地址和端口,默认localhost:8081,是jobManager的进程
- conf/slaves,指定taskmanager的地址,默认是localhost,表示当前主机启动一个jobmanager一个TaskManager
Standalone模式
- 解压缩flink-1.10.1-bin-scala_2.12 .tgz
- 修改flink-conf.yaml文件(jobmanager地址)
- 修改slaves为其他节点(master节点默认为localhost:8081,slaves节点是taskmanage节点),注意所有节点配置要一致
./start-cluster.sh启动集群,./stop-cluster.sh停止集群- 提交任务:配置优先级
代码 > 提交 > flink-conf.yaml - 前端提交,默认master的配置localhost:8081端口
- 命令行提交
flink run -c MainClass -p 2 xxx.jar --host localhost --port 7777(-c主类名,-p是并行度,后面跟自己的命令行参数) - flink命令
flink list # 查看运行的job
flink list -a # 列出所有job,包括取消的
flink cancel jobId # 取消job
缺点:当有任务的并行度大于现有可用的slot时,job提交会一直卡在create,直到有足够的slot
Yarn模式
要求flink是有hadoop支持的版本,Hadoop环境在2.2以上,并且集群中有HDFS服务。flink1.7之前自带Hadoop的jar包,之后需要自行下载,放入lib目录下
— session-Cluster模式
需要先启动flink集群,然后再提交作业,接着会向yarn申请一块空间,资源保持不变。如果资源满了下一个作业就无法提交,只能等到yarn中的某些作业执行完,释放了资源,下个作业才会正常提交。所有作业共享Dispatcher和ResourceManager,共享资源,适合规模小执行时间短的作业。
(类似standalone模式,资源固定,所有作业共享同一个集群的资源,flink集群常驻在yarn集群)
在yarn中初始化一个flink集群,开辟指定的资源,以后提交任务都向这里提交,这个flink集群会常驻在yarn集群,除非手动停止。
使用:
- 启动Hadoop集群
- 启动yarn-session
yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
-n(–container) taskmanager的数量(在现在的版本上不起作用,不直接指定TaskManager的数量,也可以使用yarn的所有资源了)
-s(–slots)每个taskmanager的slot的数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,优势可以多一些taskmanager,做冗余
-jm JobManager的内存,MB
-tm 每个taskmanager的内存,MB
-nm yarn的appName,yarn的ui上的名字
-d 后台执行 - 提交任务与Standalone模式相同(使用flink run),启动yarn-session后默认向yarn-session提交,之后在yarn8088上即可查看
- 取消启动的yarn-session
yarn application --kill application_xxxx,那么就删除了创建的flink集群,删除flink job的话还是在8081端口或使用flink cancel
— Per-Job-Cluster模式
一个Job会对应一个集群,每提交一个作业会根据自身的情况,都会单独向yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享Dispatcher和ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
使用:
- 启动Hadoop集群
- 直接使用集群模式提交job
fink run -m yarn-cluster -c mainClass jar包 命令行参数
Kubernetes部署
flink在最近的版本中支持了k8s部署模式。
使用:
- 搭建k8s集群,启动
- 配置各组件的yaml文件(在k8s上构建flink session cluster,需要将flink集群的组件对应的docker镜像分别在k8s上启动,包括jobmanager、taskmanager、jobmanagerservice三个镜像服务,每个镜像服务都可以从中央镜像仓库获取)
- 启动Flink Session Cluster,启动对应的服务
kubectl create -f jobmanager-service.yaml启动jobmanager-service服务
kubectl create -f jobmanager-deployment.yaml启动jobmanager-deployment服务
kubectl create -f taskmanager-deployment.yaml启动taskmanager-deployment服务 - 访问Flink UI界面
集群启动后,就可以通过JobManagerServicers中配置的 WebUI 端口,用浏览器输入以下 url 来访问 Flink UI 页面了http://{JobManager Host:Port}:Port}/api/v1/namespaces/default/services/flink-jobmanager:ui/proxy
运行时四大组件
— JobManager
- JobManager控制flinkJob执行的主进程,一个flinkJob被一个JobManager控制
- JobManager会先接收到要执行的应用程序, 这个应用程序包括:JobGraph、logical dataflow graph、打包了所有的类库和其它资源的JAR包
- JobManager会把JobGraph转换成一个物理层面的执行图Execution Graph,包含所有可以并发执行的任务
- JobManager会向ResourceManager请求执行任务必要的资源(TaskManager上的slot)。一旦获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。在运行过程中,JobManager会负责所有需要中央协调的操作,比如说checkpoints的协调
总结:一个flinkJob由一个JobManager控制,接收job,转换为执行图,然后向RM申请资源,申请到后分发执行图到资源所在的TM,并负责运行过程中flinkJob的中央协调
— TaskManager
- TaskManager是Flink中的工作进程,通常在集群中每个节点有一个TaskManager,每TaskManager有若干个slot,slot的数量就是TaskManager能够执行的任务数量
- TaskManager启动后, 会向ResourceManager注册它的slot,收到ResourceManager的指令后,TaskManager就会将一个或者多个slot提供给JobManager调用。JobManager就可以向slot分配任务来执行了
- 在执行过程中,TaskManager可以跟其它运行同一flinkJob的TaskManager交换数据
总结:TaskManager实际执行flinkJob,每个TaskManager有若干个slot,启动后就向ResourceManager注册,ResourceManager将有空闲slot的TaskManager分配给jobmanager后,jobmanager就会分发任务到taskmanager,taskmanager之间可以交换数据(同一flinkJob的上下游)
— ResourceManager
- 主要负责管理TaskManager的slot,slot是Flink中定义的计算资源单元
- Flink为不同的环境和资源管理工具提供了不同的ResourceManager,比如YARN 、Mesos 、K8s以及 standalone部署
- 当JobManager申请slot资源时,ResourceManager会将有空闲slot的TaskManager分配给JobManager 。如果ResourceManager没有足够的slot来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器(特定环境下的ResourceManager去执行)
- 另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源
总结:管理TaskManager的slot,接收jobmanager申请资源的请求,分配taskmanager给jobmanager,向资源平台申请资源,终止空闲的TaskManager
— Dispacher
- 可以跨作业运行,为应用提交提供了REST接口
- 当一个应用被提交执行时,Dispatcher就会启动并将应用移交给一个JobManager,由于是REST接口,所以 Dispatcher可以作为集群的一个HTTP接入点,这样就能够不受防火墙阻挡
- Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息
- Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式
总结:负责接收提交的应用程序,将flinkJob移交给一个Jobmanager,并提供webUI监控job的执行情况
任务提交流程
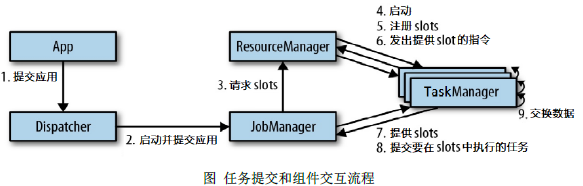

- 1,2,提交flinkJob后,首先交给Dispatcher,Dispatcher启动一个Jobmanager(地址在flink-conf.yaml里面配置),并将flinkJob提交给jobmanager
- 3,然后jobmanager向ResourceManager申请slot资源,ResourceManager向平台申请资源(如果是standalone模式或yarn-session模型,TaskManager是启动好的,这里的ResourceManager可以是flink集群自己的,也可以是yarn或其他资源管理器)
- 4,5,6,TaskManager启动并向ResourceManager注册自己的slot,ResourceManager向TaskManager发起提供slot的指令
- 7,8,9,TaskManager就可以与jobmanager通信提供自己空闲的slot,jobmanager之后将任务分发到指定的TaskManager上进行执行,并且不同TaskManager可以进行通信
yarn模式任务提交流程
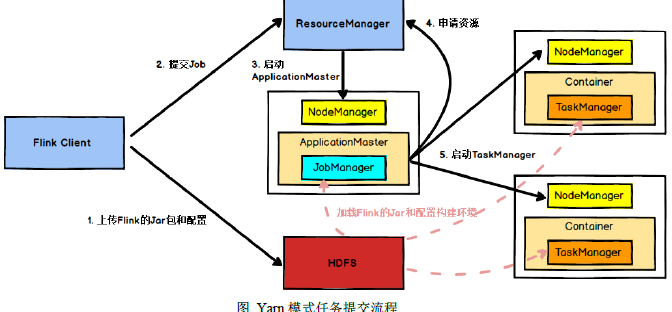
- 1,2,flink client提交任务给yarn的ResourceManager
- 3,4,RM在某个nodemanager启动applicationmaster,applicationmaster启动jobmanager,jobmanager向flink的RM申请slot,flink的RM通知applicationmaster,applicationmaster向yarn的RM申请资源,RM分配container后,由applicationmaster通知节点的NM启动TaskManager
- 5,TaskManager启动后向flink的RM注册,flink的RM下发分配slot的指令,TaskManager与jobmanager通信,提供slot
任务调度原理
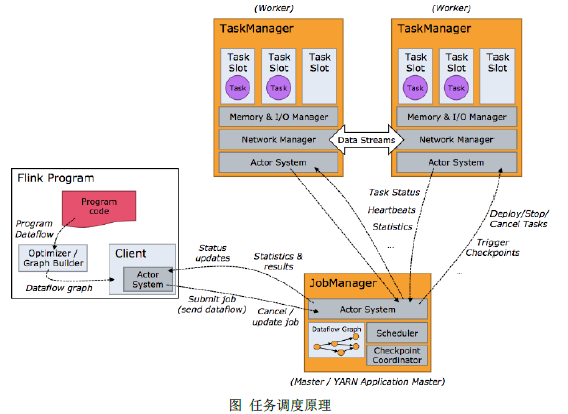
flink代码可以是一个数据流图,提交给jobmanager后,jobmanager转化为DAG执行图,并将执行图在TaskManager的slot上执行,那么一个flinkJob需要几个slot执行?一个flinkJob有几个task?
- 并行度(Parallelism):一个特定算子的子任务的个数称为并行度,一般情况下,所有算子中最大的并行度就是stream的并行度
- taskmanager与slot:
- 一个taskManager是一个jvm进程,它可能会在独立的线程上执行一个或多个子任务
- TaskManager通过slot来控制能接收多少task,一个TaskManager至少有一个slot
- 默认情况下,flink是允许子任务共享slot的(不同的任务放在同一个slot,一个slot上运行多个线程,抢占同一个slot的资源),即使它们是不同任务的子任务,这样的结果是,一个slot可以保存作业的整个管道。可以设置slot共享组,在同一个共享组内的任务可以共享slot,不同组内的任务一定会占用不同的slot。默认有一个default共享组,后面的任务如果没有设置默认与前一个相同。
需要的slot是所有组的最大并行度的和 - slot是静态的概念,指TaskManager具有的并发的能力
- 程序与数据流(DataFlow):
- 所有的flink任务都是由三部分组成的,source,transformation,sink。source负责读取数据源,transformation利用各种算子进行加工,sink负责输出
- 在运行时,flink上运行的程序会被映射成逻辑数据流,每一个流以一个或多个source开始,以一个或多个sink结束,类似于任意的有向无环图(DAG),大部分情况下,程序中的转换运算与数据流中的算子是一一对应关系(没合并,这里的算子指的是DAG中的一个节点)
- 执行图(ExecutionGraph)
- flink中的执行图分为四层:streamGraph -> jobGraph -> ExecutionGraph -> 物理执行图
- streamGraph:调用api生成的图,表示程序的拓扑结构
- jobGraph:streamGraph经过优化形成jobGraph(8081页面上那个就是),将jobGraph提交给jobmanager。主要优化为将符合条件的节点合并在一起作为一个节点(一个节点就是一个task,但是并不是一个task就需要一个slot,可以多个task使用一个slot
- ExecutionGraph:jobmanager根据jobGraph生成ExecutionGraph,ExecutionGraph是jobGraph的并行化版本,是调度层最核心的数据结构
- 物理执行图:jobmanager根据ExecutionGraph对job进行调度后,在各个TaskManager上部署task形成的图,并不是一个具体的物理结构
- 数据传输形式:
- 一个程序中,不同的算子可能具有不同的并行度,算子之间传输数据可以是one-to-one(forwarding)也可以是redistributing,具体是哪一种取决于算子的种类,比如keyBy就是基于hash的redistributing,比如map/flatMap/filter都是one-to-one
- redistributing,流的分区发生改变,数据会被发送到不同的子任务进行计算,比如keyBy按hash,broadcast随机分区、rebalance轮询,类似spark的shuffle过程
- 任务链(Operator Chain)
- flink采用了一种称为任务链的优化技术,可以在特定条件下减少本地通信的开销,为了满足任务链的要求,两个或多个算子之间的并行度必须相同,并通过本地转发的方式进行连接,相同并行度的one-to-one操作可以合并在一起形成一个任务链(slot共享组也必须相同,否则都不在同一个slot了,可以单个算子关闭任务链disableChaining,也可以关闭一半,使用startNewChain,也可以全局关闭env.disableOperatorChaining)
一个flinkJob一般分为四个步骤:获取环境,添加source,数据转换,添加sink。
在flink1.12版本之前,批处理与流处理api不同,后续版本实现了流批一体。
执行环境(Environment)
自动根据提交、运行方式获取环境(一般使用这个)
ExecutionEnvironment.getExecutionEnvironment(); //批处理环境
StreamExecutionEnvironment.getExecutionEnvironment(); //流处理环境
获取本地环境
ExecutionEnvironment.createLocalEnvironment();
StreamExecutionEnvironment.createLocalEnvironment();
获取远程环境(未测试成功)
ExecutionEnvironment.createRemoteEnvironment("jobmanager-host", 6123, "path/jar");
StreamExecutionEnvironment.createRemoteEnvironment("jobmanager-host", 6123, "path/jar");
数据源(Source)
在执行环境上可以添加数据源,返回一个DataStreamSource(继承SingleOutputStreamOperator,DataStream)
- 集合/元素
- 文件
- kafka
- 自定义
转换算子(Transform)
- 基本转换:map/flatMap/filter,参数为基本函数和rich版本函数
- map,一个流转换为另外一个流,一对一输出,类型可以改变
- flatMap,一个流转换为多个流再合成一个流,类型可以改变,可以不输出
- filter,一个流过滤掉某些元素,不能改变类型
- process,底层api,通用一对一处理, 参数为processFunction,也是rich function
- 分组聚合:keyBy -> sum/min/max/minBy/maxBy/reduce/…,参数为基本函数和rich版本函数
- flink中所有的聚合操作都要先分组,reduce、sum等都要先keyBy(对于流,如果不分组就聚合,假如有多个流,直接聚合,多个流的各个聚合结果是没有意义的,如果分组聚合,聚合的结果是针对分组有意义的,聚合结果都是针对当前分组的,flink对某一个key做统计才是有意义的,所以在flink api中只有先keyBy才能聚合)
- keyBy,从逻辑上将一个流拆分成不同的分区,保证相同key的数据都在同一个分区,不同key的数据可能在同一个分区
- min/max,只关注区最小/最大值的字段,其他字段是当前key的第一个元素的字段值,只有最小/最大字段是新的
- minBy/maxBy,关注最小/最大值的字段所在的元素,所有字段都是新的
- reduce,是一般化的聚合操作,也叫做规约,可以使用reduce实现min/minBy/max/maxBy
- process,参数为 KeyedProcessFunction,是rich function,keyBy之后的处理
- window,参数为基本函数和rich版本函数
- sum/min/max/minBy/maxBy/reduce/aggregate/apply/process
- apply,全窗口计算,WindowFunction
- process, 参数为ProcessWindowFunction,也是rich function
- 多流操作:split/connect/union,
- split, 将一条流拆分为多条流,将DataStream转换为SplitStream,虽然还是一个流,但是已经根据某些特征对数据标记进行了标记,可以打多个标记(标记是Iterable类型),调用SplitStream.select()方法返回对应标记的DataStream。(已经Deprecated,使用ProcessFunction的side output Stream)
- connect, 合并两条流,将两个DataStream转换为ConnectedStreams,虽然是一个Stream,但是已经把两个流包在了一个流中,然后就可以对这个ConnectedStreams进行map/flatMap/process/keyBy等操作了,但是传入的是CoMapFunction/CoFlatMapFunction,参数为基本函数和rich版本函数,process传入的是 CoProcessFunction或KeyedCoProcessFunction,后者的参数会多一个key
- union, 将多条类型相同的流合并为一条流,直接调用union方法,参数可以是多条流
- 侧输出流,SingleOutputStream可以获取侧输出流(Window的迟到数据)
- 重分区:rebalance/rescale/forward/broadcast/global
- rebelance是轮询发送数据到下游的subTask,rescale是上游的多个分区分摊下游的分区,如果上游是两个分区,下游是4个分区,rescale就是上游的一个对应下游的两个,与rebalance不同
- forward直接发送给下游的一个分区
- broadcast,将数据广播给下游所有的分区
- global,上游所有数据都发送给下游的第一个分区
- partitionCustom,自定义分区
注意:
- flink的流中不允许有null元素,keyBy的key也不允许为null(flink的流中认为null是无意义的)
- 在自定义转换算子的逻辑时,如果使用lambda表达式,由于泛型擦除的影响,flink是无法推断元素的类型的,可以在算子调用的后面调用returns(),传入类型参数,或者直接使用Function的匿名实现类
- keyBy分组时,只能对元组使用位置参数;如果使用字符串指定字段,那么key是一个元组类型(因为可能有多个字段作为key),也可以使用KeySelector(更直接,如果是pojo可以使用方法引用)
转换算子总结:
- DataStream(SingleOutputStream)
- map/reduce/filter/flatMap:DataStream –> DataStream
- keyBy:DataStream –> keyBy() –> KeyedStream –> map/reduce… –> DataStream
- split:DataStream –> split() –> SplitStream –> select() –> DataStream
- connect:DataStream –> connect() –> ConnectedStreams –> map/reduce… –> DataStream
- broadcast:DataStream –> broadcast(x) –> BroadcastStream –> 被DataStream.connect() –> BroadcastConnectedStream –> process() –> DataStream
- join:DataStream –> join(x) –> JoinedStream –> where() –> JoinedStream.Where –> equalTo() –> JoinedStream.Where.EqualTo –> window() –> JoinedStream.WithWindow –> apply() –> DataStream
- intervalJoin: KeyStream –> intervalJoin() –> IntervalJoin –> between() –> IntervalJoined process() –> DataStream
窗口算子总结:
- keyBy+window:DataStream–> keyBy –> KeyedStream –> window… –> WindowedStream –> map/reduce/apply… –> DataStream
- non-keyBy+window:DataStream –> windowAll –> AllWindowedStream –> map/reduce/apply… –> DataStream
Fink支持的数据类型
Java和Scala的基本数据类型,Java和Scala元组,Scala样例类,Java简单对象,其他java和scala中特殊目的类型(Arrays, Lists, Maps, Enum等等)
注意:
- keyBy的javaBean,如果在代码中使用String字段作为参数,必须要求bean有空参构造和所有字段的getter/setter
自定义函数(UDF,User-Defined Function)
- 函数类(Function Classes):
- Flink暴露了所有的udf的接口(实现方式为接口或抽象类,富函数的为抽象类)
- 可以自定义一个类,也可以写匿名实现类,自定义类可以设置属性,封装为更通用的计算逻辑被别处调用
- 匿名函数(Lambda Function):
- 使用lambda表达式,注意如果有泛型可能需要使用returns显式指明泛型类型
- 富函数(Rich Function):
- 富函数,是DataStreamAPI提供的一个函数类的接口,所有的Flink函数类都有Rich版本,与常规函数的不同在于,可以获取 运行时的上下文,并拥有一些 生命周期方法,可以实现更复杂的功能。
- 富函数的使用与基本函数类似,自定义基本函数实现相应接口,自定义富函数继承相应的富函数抽象类(这些富函数抽象类都继承自AbstractRichFunction,该抽象类实现了RichFunction接口,RichFunction接口实现了Function接口)
- 典型的生命周期方法,open/close/getRuntimeContext,open只在创建DAG时的这个对象时执行一次,可以创建一些外部连接,close是最后一个调用的方法,做一些清理工作,getRuntimeContext提供运行时上下文的一些信息,比如函数执行的并行度、任务名称、state状态等
- RichMapFunction/RichFlatMapFunction/RichFilterFunction…
数据输出(Sink)
Source是在执行环境中添加,返回DataStream,在DataStream上可以addSink,返回DataStreamSink
flink流数据写入kafka/redis/es/jdbc,以及其他官方的连接器,也可以自定义sink(实现SinkFunction或RichSinkFunction)
window把无界的流拆分成有限大小的bucket,每个窗口是一个bucket,数据来了之后分到不同的bucket,可以多个bucket并存(允许迟到数据),flink在这些bucket上做计算。每个bucket来数据之后可以更新该窗口的计算结果。
窗口分类
- 时间窗口(Time Window):
- 滚动时间窗口(Tumbling),按时间滚动
- 滑动时间窗口(Sliding),按时间步长滑动
- 会话窗口,多久未收到数据后结束当前窗口(只有时间类型的)
- 计数窗口(Count Window):
- 滚动计数窗口(Tumbling),按数据个数滚动
- 滑动计数窗口(Sliding),按数据个数步长滑动
说明:
- 滚动窗口:将数据按照固定的窗口长度对数据切分,时间是对齐的(左闭右开),窗口长度固定,没有重叠,只有一个参数 窗口长度
- 滑动窗口:是固定窗口的更广义的一种形式,由 窗口长度和滑动步长组成,时间对齐,窗口长度固定,可以重叠,滚动窗口是特殊的滑动窗口,滑动步长为敞口长度
- 会话窗口,由一系列事件组合一个指定长度的timeout间隙组成,一段时间没有接收到数据就会生成新的窗口,事件不对齐,由一个参数session gap确定,表示最小时间间隔,超过这个时间,窗口失效,下一个数据来会是新窗口
使用:
- Window使用前必须先keyBy(flink的聚合操作都要先分组,分组后的聚合才是有意义的,窗口也是聚合操作)
- 再进行Window操作(窗口分配器,指定如何开窗,timeWindow,countWindow,通用的window)
- 后面必须再跟上类似聚合的窗口操作(窗口函数,指定如何计算)
窗口分配器(Window assigner)
window()方法接收的输入参数是一个windowAssigner,它负责把每条数据分发到正确的window中,flink提供了通用的windowAssigner,可用直接赋值给window()方法:滚动窗口,滑动窗口,会话窗口,全局窗口(处理计数窗口)。
使用:
- 时间和计数窗口一般不直接使用window()方法,可以使用timeWindow(),countWindow(),会话窗口没有直接定义的方法,可以使用window(EventTimeSessionWindows.withGap())。使用window方法可以在创建时间窗口时设置偏移量(默认对齐时间戳)
窗口函数(Window function)
窗口分配之后进行计算,分为两类:
- 增量聚合函数:来一条数据计算一次,保持一个简单的状态,窗口结束后输出,ReduceFunction(简单reduce),AggregateFunction(可以存储一个状态)
- 全窗口函数:先把窗口所有数据收集起来,全部到来之后进行计算,计算时会遍历所有数据(比如求中位数),ProcessWindowFunction(底层全窗口数据处理process),WindowFunction(一般的全窗口数据处理)
使用:stream.keyBy().window().[可选api].sum/…reduce/aggregate/apply/process[.getSideOutput],不keyBy就使用windowAll.
- 增量聚合函数:
- sum/min/max/minBy/maxBy,也是增量聚合,只不过写好了底层的实现逻辑
- reduce传入reduceFunction,也可以增加WindowFunction或ProcessWindowFunction参数作为全窗口的输出结果
- aggregate传入AggregateFunction,这个带有一个累加器,可以累加一个状态
- 全窗口函数:
- apply,传入WindowFunction;
- process,传入ProcessWindowFunction,是底层api,是rich function,可以拿到上下文
- 其他可选api
- trigger() 定义窗口什么时候关闭 触发并计算结果
- evictor() 定义移除某些数据的逻辑
- allowedLateness(),允许迟到数据 窗口触发时输出计算结果 但是窗口不关闭 该窗口的数据如果再来 就再输出一次结果 (水印之前, 只有事件时间窗口下才有效)
- sideOutputLateData() 将迟到数据放入侧输出流,这个侧输出流可以使用返回的SingleOutputStreamOperator.getSideOutput()获取到(聚合结果之后),侧输出流标签OutputTag使用匿名实现类,加{},由于泛型擦除没法直接拿到参数类型
时间语义
- EventTime:事件时间,是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都有生成时间,Flink通过时间戳分配器访问事件时间戳。如果使用kafka,自动使用kafka的时间
- IngestionTime:注入时间,是数据进入Flink的时间。
- ProcessingTime:处理时间,是每一个执行基于时间操作的算子的本地系统时间,与机器相关,算子默认是ProcessingTime
注意:
- 系统默认是Process Time语义,算子默认也是Process Time
- 设置时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
Watermark
当达到事件时间的窗口结束时,不立刻触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口(相当于把处理事件时间的进展的时钟调慢了)
WM的概念:
- Watermark是一种衡量Event Time进展的机制,可以设置延迟触发
- Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。
- 数据流中的Watermark用于表示timestamp小于Watermark的数据已经到达了,因此,window的执行也是由Watermark 触发的。
- WaterMark用来让程序自己平衡延迟和结果的正确性,不能太大也不能太小,太大延迟大,准确性高,太小延迟小,准确性低。
WM的特点:
- WM是一条特殊的数据记录
- WM必须单调递增,以保证任务的事件时间时钟在向前推进,而不是在后退
- WM与数据的时间戳相关
- WM可以理解成一个延迟触发机制,我们可以设置WM的延时时长t,每次系统会校验已经到达的数据中最大的事件时间maxEventTime,然后认定事件时间小于maxEventTime – t的所有数据都已经到达,如果有窗口的结束时间等于maxEventTime – t,那么这个窗口被触发执行。
WM的传递:
- 如果当前task有多个上游分区,那么当前task会存储每个上游分区的WM(如果分区还没有数据到来,存储的是Long的最小值),选择所有分区最小的WM向下游传递,表示当前task的上游中所有小于WM的数据都已经处理完了。如果WM没有更新或者更新后最小WM没有改变,不向下游传递。
- WM生成离source越近越好,
WM的类型:
- flink有两种类型WM,周期性生成和每条数据后面生成,都继承类了接口TimestampAssigner,周期性生成WM默认实现类有两个
BoundedOutOfOrdernessTimestampExtractor和AscendingTimestampExtractor - AssignerWithPeriodicWatermarks,周期性生成WM,默认200ms,可以在env设置时间语义的源码上看到(适合数据量大)
- AssignerWithPunctuatedWatermarks,每条数据后都插入一个水印(适合数据量小)
WM的使用:
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<yourtype>(Time.milliseconds(200))</yourtype>.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<yourtype>()</yourtype>,用当前事件时间减1ms作为WM,保证左闭右开- 上面两个都是周期性生成,自定义WM,实现接口AssignerWithPeriodicWatermarks
WM的设定:
- 在flink中,WM由开发人员设定,通常需要对领域有一定的了解,以确定合适的延时时长,如果设置WM时间太长,延迟高,如果WM时间太短,结果不够准确
- 设置WM生成周期:
env.getConfig().setAutoWatermarkInterval(100); //默认200ms
窗口的起始点和偏移量:
- 窗口默认是对时间戳对齐的(1970年1月1日),第一条数据到来后(事件时间为t),先确定第一个窗口,
t - (t - offset + windowSize) % windowSize - 偏移量可以在创建窗口时设置(window()),主要用来处理时区
迟到数据处理的几种保障:
- 水印,允许事件时间延迟一段时间再触发计算(触发是由水印时间触发的),可以设置一个时间t,当前最大事件时间currentT-t之前的窗口开始触发计算
- 窗口设置允许迟到数据,设置窗口延迟关闭时间t1,currentT-t之前的窗口触发计算后并不马上关闭,在currentT + t1的事件到来之前,从currentT-t到currentT + t1且属于currentT-t之前没有关闭窗口的数据依然可以更新到那个窗口,来一条更新一次,在currentT + t1的事件到来之后,currentT-t之前的窗口关闭。
- 窗口关闭后迟到的数据,放入侧输出流
ProcessFunction API(底层API)
基本的转换算子是无法访问事件时间的时间戳和水位线信息的,基于此,flink提供了一系列low-level转换算子,可以获取到上下文信息: 获取事件时间、 获取WaterMark时间、 注册定时事件(实现任意时间窗口)、输出特定事件、 输出侧输出流(之前只能在window下使用)。
ProcessFunction用来构建事件驱动的应用以及实现自定义的业务逻辑(之前的算子和window无法实现)
flink提供了8个process function:
- ProcessFunction,处理单个元素,DataStream.process使用ProcessFunction
- KeyedProcessFunction,处理分组后的单个元素
- CoProcessFunction,处理DataStream.connect(DataStream)得到ConnectedStream,连接流process使用
- ProcessJoinFunction,处理KeyedStream与KeyedStream intervalJoin
- BroadcastProcessFunction,处理广播连接流,DataStream.connect(BroadcastStream)得到BroadcastConnectedStream,这个广播连接流process使用
- KeyedBroadcastProcessFunction,处理keyed广播连接流,KeyedStream.connect(BroadcastStream)得到BroadcastConnectedStream,这个广播连接流process使用
- ProcessWindowFunction,处理窗口流,DataStream.keyBy()得到KeyedStream,KeyedStream.window()得到WindowedStream,后面跟的窗函数process使用
- ProcessAllWindowFunction,处理全窗口流,DataStream.windowAll()得到AllWindowedStream,process()使用
使用:
// ---------- Context api 底层api可以拿到上下文 ----------
ctx.getCurrentKey(); //当前key
ctx.timestamp(); //事件时间的时间戳 如果时间语义是process time 为null
//timerService
ctx.timerService().currentProcessingTime(); //获取当前处理时间
ctx.timerService().currentWatermark();
ctx.timerService().registerEventTimeTimer(1); //参数是绝对时间戳 可以拿到当前时间相加 可以用state保存 以便后续删除
ctx.timerService().registerProcessingTimeTimer(1);
ctx.timerService().deleteEventTimeTimer(1);
ctx.timerService().deleteProcessingTimeTimer(1);
//侧输出流
// ctx.output(new OutputTag("keyed"){}, value); //将一些数据放入侧输出流里
由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。可以认为状态就是一个本地变量,可以被任务的业务访问。flink会进行状态管理,包括一致性、故障处理、高效存储和访问,以便开发人员可以专注于业务逻辑。
存在的目的主要是因为同一个算子分布式并发执行,需要访问到相同的变量(状态)
概念:
- 状态与特定算子相关联,为了使运行时的flink了解算子的状态,需要预先注册其状态
- 总的来说,有两种类型的状态
- 算子状态(Operator State),作用范围限定为算子任务,由同一并行任务所处理的数据都可以访问到相同的状态
- 键控状态(Keyed State),根据输入流中定义的key来维护和访问,只要在同一个分区访问的就是同一个状态,可能同一分区有多个不同的key??,flink为每个key维护一个状态实例,并将所有具有相同key的所有数据都分区都同一个算子任务,这个任务会维护和和处理这个key的状态,当任务处理一条数据时,它将自动将状态的访问范围限定为当前数据的key。
数据结构
- 算子状态的数据结构:
- 列表状态(List State),将状态表示为一组数据的列表
- 联合列表状态(Union List State),也将状态表示为数据的列表,与常规列表状态的区别在于,发生故障时或者从保存点(savepoint)启动应用程序时如何恢复
- 广播状态(Broadcast State),如果一个算子有多项任务,而每个任务状态都相同,那么这种状态适合应用广播状态
- 键控状态的数据结构
- 值状态(Value State),将状态表示为单个的值(算子状态没有是因为并行度改变时没法切分,这里是按key维护的,按key切分就可以了,所以有单个的值状态)
- 列表状态(List State),将状态表示为一组数据的列表
- 映射状态(Map State),将状态表示为一组kv
- 聚合状态(Reducing State & Aggregating State),将状态表示为一个用于聚合操作的列表
State使用:
- 算子状态:算子自定义属性,并实现ListCheckpoint接口,将属性保存在这个ListState里,接口有两个属性,保存和恢复,恢复时的ListState可能是多个分区的所有State,此时如果并行度改变,状态也会被均分
- 键控状态:每个key都有一个状态,使用运行时上下文
状态后端(State Backends)
- 每来一条数据,有状态算子都会读取和更新状态,有效的状态访问对处理数据的延迟至关重要,因此每个任务都会在本地维护其状态,以确保快速的访问。
- 而状态的存储、访问、维护,由一个可插入的组件决定,这个组件叫状态后端,负责两件事,本地状态的管理,以及将检查点(checkpoint)状态写入远程存储
- flink提供了三种状态后端:
- MemoryStateBackend,内存级状态后端,将键控状态作为内存中的对象进行管理,存储在TM的堆上,checkpoint存储在JM的内存中。特点是快速、低延迟、不稳定
- FsStateBackend,checkpoint存储到本地文件系统,本地状态存在TM的堆上。特点是拥有内存级的存储速度和更好的容错保证。
- RocksDBStateBackend,将所有状态序列化后,存入本地的RocksDB,RocksDB也是kv数据库,读写也很快,如果不直接传递StateBackend 底层还是创建的FsStateBackend,所以用RocksDBStateBackend就可以了
- 配置状态后端:
env.setStateBackend((StateBackend)new RocksDBStateBackend("uri"));
Queryable State
将Flink的managed keyed(partitioned)state暴露给外部,从而用户可以在Flink外部查询作业state。查询时直接引用状态的值,没有任何同步或拷贝。
架构组成
- QueryableStateClient,默认运行在 Flink 集群外部,负责提交用户的查询请求
- QueryableStateClientProxy,运行在每个 TaskManager 上(即 Flink 集群内部),负责接收客户端的查询请求,从所负责的 Task Manager 获取请求的 state,并返回给客户端
- QueryableStateServer, 运行在 TaskManager 上,负责服务本地存储的 state
总结:客户端连接到一个proxy,并发送请求获取特定key的state,proxy询问jobmanager找到key所属group所在的TaskManager,根据返回结果,proxy向运行在这个TaskManager上的QueryableStateServer查询key对于的state,并将结果返回给客户端。
客户端 -> 任意一个TaskManager的proxy -> jobmanager -> key所在的TaskManager -> TaskManager的QueryableStateServer -> proxy查询到结果返回给客户端
激活 Queryable State
- 将
flink-queryable-state-runtime_2.11-1.14.4.jar从flink安装目录的opt/下拷贝到lib/ - 配置
queryable-state.enable设为true,验证激活,可检查TaskManager日志Started Queryable State Server @ xxx - 其他相关配置:官网配置,默认是0的,实际线程数为slot数,需要修改下,否则内存过小容易报直接内存溢出
在程序中设置状态可查询
– 在 KeyedStream 上调用 .asQueryableState(stateName, stateDescriptor),它会作为一个 sink,并将输入数据转化为 queryable state
– Managed keyed state 可以通过 StateDescriptor.setQueryable(String queryableStateName) 将 state descriptor 设置成可查询的
查询 state
- 创建客户端
org.apache.flink
flink-core
1.14.4
org.apache.flink
flink-queryable-state-client-java
1.14.4
- 使用:参考官网例子,官网示例
//tmHostname为任意一个TaskManager所在的主机
//proxyPort为代理的端口,默认9069,参考官网配置
QueryableStateClient client = new QueryableStateClient(tmHostname, proxyPort);
CompletableFuture getKvState(
JobID jobId, //flink提交任务生成的jobId,可以使用JobID.fromHexString()转换
String queryableStateName, //设置状态可查询时设置的名称
K key, //keyBy所使用的字段
TypeInformation keyTypeInfo, //提供key的类型信息,进行序列化
StateDescriptor stateDescriptor) //设置状态可查询时设置的stateDescriptor
总结:
- Managed State 直接设置可查询即可,(与ttl冲突),keyedStream也可以设置值状态
一致性检查点(checkpoints):
- flink故障恢复机制的核心,就是应用状态的一致性检查点
- 有状态流的一致性检查点,其实就是所有任务的状态在某个时间点的一份快照,这个时间点,应该是所有任务都恰好处理完一个相同输入数据时候,
- 进行保存状态,同步保存,检查点分界线之后的数据先缓存,等所有检查点保存完成之后再进行计算
从检查点恢复状态:
- 从最近的检查点恢复应用状态,重新启动处理流程
Flink检查点算法:
- 基于Chandy-Lamport算法的分布式快照,检查点的保存和数据处理分离开,不暂停整个应用。
- 检查点分界线(Checkpoint Barrier):一种特殊数据,用于把一条流上的数据按照不同的检查点分开。
保存点:
- 自定义保存检查点
端到端的一致性需要source可以使用偏移量查询历史数据、sink可以回滚。
状态一致性:
- 有状态的流处理,内部每个算子任务都可以有自己的状态
- 对于流处理器内部来说,状态一致性就是指计算结果要保证正确,一条数据不应该丢失也不应该重复计算
- 遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正确的
- 状态一致性分类:
- AT MOST ONCE (最多一次)
- AT LEAST ONCE (至少一次)
- EXACTLY ONCE (精确一次)
一致性检查点:
- flink使用了一种轻量级快照机制(检查点)来保证exactly-once语义
- 有状态流的一致性检查点,其实就是,所有任务的状态在某个时间点的一份拷贝,这个时间点应该是所有任务都敲好处理完一个相同输入数据的时候
- 应用状态的一致性检查点,是flink故障恢复机制的核心
端到端状态一致性:
- 目前看到的一致性保证都是由流处理器实现的,在真实应用中,流处理应用处理流处理器以外还包含了数据源和输出到持久化系统
- 端到端一致性意味着,每个组件都要保证自己的一致性
- 端到端的一致性取决于所有组件中一致性最弱的组件
端到端exactly-once保证:
- 内部,使用checkpoint保证
- source端,可重设数据读取位置,如果不可重置,只能实现【At-most-once】
- sink端,故障恢复时,数据不会重复写如外部系统
- 幂等写入,一个操作可以重复执行多次,但只导致一次结果更改,也就是后面重复执行的就不起作用了,会有短暂的数据不一致,但最终是正确的,【Exactly-once,故障恢复时会出现端在不一致】
- 事务写入,事务中所有操作要么都完成,要么都撤销,具有原子性
- 实现思想:构建事务对应着checkpoint,等到checkpoint真正完成的时候,才把对应的结果写入sink系统
- 实现方式有两种:预写日志wal、两阶段提交(要求外部系统提供事务支持、提交事务必须幂等)
事务写入的两种方式:
- 预写日志(Write-ahead-log,WAL):【At-least-once】
- 把结果数据先当成状态保存,然后在收到checkpoint完成的通知时,一次性写入sink系统
- 简单易于实现,由于数据提前在状态后端做了缓存,所以无论是什么sink系统,都能用这种方式一批搞定
- DataStream api提供了一个模板类,GenericWriteAheadSink,来实现这种事务sink
- 缺点:批处理,一次性写入的时候不能保证完全写正确,还是不能保证精确一致性,
- 两阶段提交(Two-Phase-Commit,2PC):【Exactly-once】
- 对于每个checkpoint,sink任务会启动一个事务,并将接下来的数据添加到事务里
- 然后将这些数据写入外部sink系统,但不提交它们,只是预提交
- 当它收到checkpoint完成的通知时,它才正式提交事务,实现结果的真正写入
- 这种方式真正实现了exactly-once,它需要一个提供事务支持的外部sink系统,flink提供了TwoPhaseCommitSinkFunction抽象类
- 2PC对外部sink系统的要求:
- 外部系统必须支持事务,或者sink任务能够模拟外部系统上的事务
- 在checkpoint间隔期间里,必须能够开启一个事务并接受数据写入
- 在收到checkpoint完成通知之前,事务必须是等待提交状态,在故障恢复的情况下,这可能需要一些时间,如果这个时候系统关闭了(比如超时),那么未提交的数据就会丢失,(注意事务超时、checkp超时、算子超时要一致,外部读取kafka数据要read committed,默认是read uncommitted)
- sink任务必须能够在进程失败后恢复事务
- 提交事务必须是幂等操作
Flink + Kafka端到端状态一致性的保证:
- 内部,利用checkpoint机制,把状态存盘,发生故障时可以恢复,保证内部的状态一致性
- source,kafka consumer作为source,可以把偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性,(默认就会把偏移量作为状态保存)
- sink,kafka producer作为sink,采用两阶段提交,需要实现TwoPhaseCommitSinkFunction,
- jobmanager协调各个TaskManager进行checkpoint
- checkpoint保存在stateBackend中,默认是内存级别的,也可以改为文件级进行持久化保存
- 当checkpoint启动时,jobmanager会将检查点分界线barrier注入数据流
- barrier会在算子间传递下去
- 每个算子会对当前的状态做个快照,保存到状态后端
- checkpoint机制可以保存内部状态的一致性
- 每个内部的transform遇到barrier时,都会把状态存到checkpoint里
- sink任务首先把数据写入外部kafka,这些数据都属于预提交的事务,遇到barrier时,把状态保存到状态后端,并开启新的预提交事务
- 当所有的算子任务的快照完成,也就是这次checkpoint完成时,jobmanager会向所有任务发通知,确认这次checkpoint完成
- sink任务收到确认通知,正式提交之前的事务,kafka中未确认数据改为已确认
- 两阶段提交步骤:
- 第一条数据来了之后,开启一个kafka事务,正常写入kafka分区日志,但标记为未提交,这就是预提交
- jobmanager触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知jobmanager
- sink连接器收到barrier,保存当前状态,存入checkpoint,通知jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager收到所有任务的通知,发出确认信息,正式提交这段时间的数据
-
外部kafka关闭事务,提交的数据可以正常消费了
-
创建TableEnvironment
- 创建表
- 表的查询:Table API、SQL
- 输出表
- 更新模式:追加模式、撤回模式、更新插入模式
- Table与DataStream的转换
- 创建临时视图
- 查看执行计划
- 动态表和持续查询
- 时间特性:事件时间和处理时间
- 窗口:group window、over window(有界和无界)、滚动窗口、滑动窗口、会话窗口
- 函数:比较函数、逻辑函数、算数函数、字符串函数、时间函数、聚合函数、用户自定义函数(标量函数、聚合函数、表函数、表聚合函数)
总结
- flink的知识点
- 安装部署
- 运行时架构
- api
- 转换算子api:source/transform/sink,map/coMap/flatMap/coFlatMap/filter/sum/min/max/minBy/maxBy/reduce/process/coProcess
- 窗口api:…/reduce/process/apply/aggregate
- flink中的概念
- JobManager,TaskManager,ResourceManager,Dispatcher
- slot
- 分区partition
- 窗口:窗口类型,窗口函数(增量函数,全窗口)
- 时间语义,watermark
- 状态管理:算子状态,键控状态
- flink的Function
- 所有的Function都有基本的Function、RichFunction,如map-RichMapFunction
- 底层api,对于单个元素处理有ProcessFunction,KeyedProcessFunction,窗口处理有ProcessWindowFunction、ProcessAllWindowFunction,多流处理有CoProcessFunction,KeyedCoProcessFunction
Original: https://www.cnblogs.com/bingmous/p/15718277.html
Author: Bingmous
Title: Flink学习笔记(整理)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/565481/
转载文章受原作者版权保护。转载请注明原作者出处!