

ElasticSearch概述
The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack),能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。ES是一个开源的高扩展的分布式全文搜索引擎,是ELK Stack的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
ElasticSearch入门
安装
安装过程参考:https://www.cnblogs.com/bingmous/p/15643678.html
基本操作
一般情况下,当然也可以使用POST新增
- GET表示获取
- PUT表示新增
- POST表示修改
- DELETE表示删除
查看es相关信息
GET _cat/nodes # 查看所有节点
GET _cat/health # 查看es健康状况
GET _cat/master # 查看主节点
GET _cat/indices # 查看所有索引
GET _cat/indices?v # 带参数v, 更详细,显示title
GET _cluster/health # 查看集群健康信息
索引操作
PUT customer # 创建索引 使用PUT
DELETE customer # 删除索引 使用DELETE
GET customer # 查看单个索引 使用GET
文档操作
添加一个文档:
使用PUT添加,不指定id会报错,因为添加认为你准确知道添加哪个id的数据。
使用POST添加,可以不指定id,会自动生成,因此相同数据会认为是多条数据,因为id不同
重复发送会增加版本号,并覆盖原文档
PUT /customer/_doc/1
{
"name":"john"
}
使用_create添加文档
准确表示在创建文档,只能创建一次,PUT POST都可以,多次创建会失败
PUT /customer/_create/1
{
"name":"john"
}
## 总结:_create用于创建,只能创建一次,PUT、POST都可以。_doc表示文档,PUT必须指定id才能添加,POST会随机生成id。如果索引没有会自动创建
删除一个文档
DELETE customer/_doc/5
查看一个文档
GET customer/_doc/6
结果如下,带_的都是元信息
{
"_index" : "customer", # 在哪个索引
"_type" : "_doc", # 在哪个类型
"_id" : "6", # id
"_version" : 1, # 版本号
"_seq_no" : 27, # 序列号,用于并发控制,每次更新就会加1,用来做乐观锁
"_primary_term" : 1, # 同上,主分片重新分配,如重启就会变化
"found" : true,
"_source" : { # 实际存储的数据
"name" : "john"
}
}
使用乐观锁修改文档,更新时携带?if_seq_no=0&if_primary_term=1 当满足条件时修改数据,否则不修改
PUT /customer/_doc/6?if_seq_no=27&if_primary_term=1 # PUT POST + _doc是覆盖,修改使用POST + _update
{
"name2":"alice"
}
更新一个文档
对比原数据,没有变化则不更新,noop,如果使用_doc直接创建新文档,会直接覆盖
_update只允许使用POST,"doc"表示文档,是内置字段,原数据会增加age字段
POST customer/_update/6/
{
"doc":{
"age":18
}
}
可以直接添加一个新文档,直接覆盖,根据实际情况确定
总结:大并发偶尔更新的使用_update更新,重新计算分配规则,大并发更新较多的直接覆盖
bulk批量API
语法格式
PUT customer/_bulk 或 PUT _bulk 或使用POST,POST _bulk表示对整个es操作
{action:{metadata}} # action可以是index delete create update 这个请求体是操作
{requestbody} # 这个是数据
示例1
PUT customer/_bulk # POST也可以 index表示都是创建新文档 多次发送覆盖
{"index":{"_id":"1"}}
{"age":123}
示例2
PUT customer/_bulk
{"index":{"_id":"1"}}
{"name":"John Doe"}
{"index":{"_id":"2"}}
{"name":"Jane"}
复杂示例,对整个ES操作,删除索引、创建索引
PUT _bulk
{"delete":{"_index":"webset","_type":"blog","_id":"123"}}
{"create":{"_index":"webset","_type":"blog","_id":"123"}}
{"title":"My first blog post"}
{"index":{"_index":"webset","_type":"blog"}}
{"title":"My second blog post"}
{"update":{"_index":"webset","_type":"blog","_id":"123"}}
{"doc":{"title":"My updateed blok post"}}
官方数据批量导入,用于练习
https://github.com/elastic/elasticsearch/blob/7.4/docs/src/test/resources/accounts.json
PUT bank/acount/_bulk,注意:acount作为类型已经被弃用了
进阶检索
Search API
- es支持的两种基本方式:
- 通过REST request URI 发送搜索参数(URI + 请求参数)
- 通过REST request body 来发送(URI + 请求体)
通过request uri检索 q=* 等价于query match_all
GET bank/_search?q=*&sort=account_number:desc
通过request body检索,请求体为Query DSL
GET bank/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"account_number": { # 也可以简写为"account_number": "desc"
"order": "desc"
}
}
]
}
默认返回10条数据,在hits.hits数组里,_source里是存储的数据


Query DSL
- 基本语法
ES提供的可以查询的json风格的DSL(Domain Specific language 领域特定语言),称为Query DSL.该查询语言非常全面,并且刚开始的时候有些复杂,真正学好它的方法是从一些基础示例开始的。
典型结构
{
query_name:{ # 根操作,要做什么,对于某个字段也是同样的结构
argument:value,
argument:value,...
}
}
- 基本使用
GET bank/_search
query # 定义如何查询
match_all # 代表查询所有 等价于xxx/_search?q=*
match # 【模糊匹配】分词匹配,全文检索按照评分进行排序,keyword表示匹配字段整个内容,全文检索使用match,非text使用term,text类型才有keyword子属性
term # 【精确匹配】比如整数值,文本字段使用match,文本字段进行了分析,使用term检索非常困难
match_phrase # 【短语匹配】不进行分词,对整个短语进行匹配
multi_match # 【多个字段匹配】在某些字段里面匹配
bool # 【复合查询】,可以组合多个查询
must # 【必须满足】这几个查询都可以使用range指定范围lte,gte,lt,gt,贡献相关性得分
must_not # 【必须不满足】
should # 【应该满足】
filter # 【过滤】不贡献相关性得分
sort # 【排序】,会在前字段相等时,后字段内部排序,跟数组
from # 【从第几条开始】偏移量
size # 【限定返回结果数量】完成分页,默认返回10,设置为0不显示数据
_source # 【返回部分字段】指定返回哪些字段
aggs # 【对匹配结果聚合】
terms # 【字段频次】size指定频次结果的前几个
avg # 【字段平均值】
- Mapping
字段类型,7.x之后移除了type的概念:
两个不同type下的两个相同字段在ES同一个索引下是同一个field,必须在两个不同的type下定义相同的filed映射,否则不同type中的相同字段名称处理就会出现冲突的情况,导致lucene处理效率下降,去掉type就是为了提高ES处理数据的效率。
查看某个索引的映射
GET bank/_mapping
创建映射 keyword表示不进行分词,text会进行分词,index默认为true表示是否可被检索
可以在创建索引的时候添加映射
PUT my_index
{
"mappings": {
"properties": {
"age":{"type": "integer"},
"email":{"type": "keyword"},
"name":{"type": "text","index": true}
}
}
}
对现有索引再添加映射
PUT my_index/_mapping
{
"properties":{
"employee_id": {
"type":"long",
"index":"false"
}
}
}
不能更改映射,只能将数据迁移至新索引
POST _reindex
{
"source": {
"index": "my_index"
},
"dest": {
"index": "my_new_index"
}
}
分词
直接解压在elasticsearch的plugins目录
查看
bin/elasticsearch-plugin.bat list
- 测试ik
分词 无法分割中文
POST _analyze
{
"analyzer": "standard",
"text": ["hello你好"]
}
使用ik分词器,观察两个效果
POST _analyze
{
"analyzer": "ik_smart",
"text": ["我是中国人"]
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": ["我是中国人"]
}
- 自定以词库,通过ngix搭建自定义词库,nginx安装见附录
配置词库,在ik安装目录下的config/IKAnalyzer.cfg.xml,返回自定义词汇即可
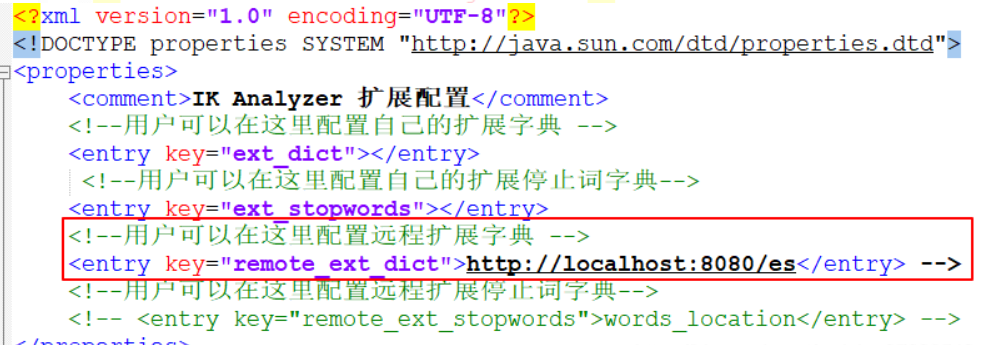
Elasticsearch进阶
集群
集群健康情况:黄色表示当前机器的主分片都正常运行,但是副本分片没有全部处于正常状态(副本分片与主分片必须在不同的节点)
带星的是主节点
Elasticsearch优化
硬件:
- 使用ssd硬盘
分片策略:
- 合理设置分片,一个分片数据过多,它的查询效率会降低,分片在创建索引时就确定了,不可更改(查询数据会直接定位到在哪个分片上),副本数可以随时更改
- 分片也不能过多,一个分片就是一个Lucene索引,会消耗一定的句柄、内存、cpu,每一个搜索请求都要命中每一个分片,如果分片处于不同的节点还好,如果多个分片都在同一个节点上,那么就会竞争使用相同的资源
- 用于计算相关度的词频统计信息是基于分片的,如果分片过多,每个分片都只有很少的数据会导致很低的相关度
- 一般分片数量不超过节点数量的三倍。主分片、副本和节点最大数可参考:
节点数<=主分片*(副本数-1)< code><!--=主分片*(副本数-1)<--> - 推迟分片分配
路由选择:
- 带路由搜索,直接去指定节点查询数据,而不用查询所有节点数据
Rest-Client
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.8.0
待整理
常用命令
- 设置自动创建索引
PUT /_cluster/settings
{
"persistent" : {
"action": {
"auto_create_index": "true"
}
}
}
Original: https://www.cnblogs.com/bingmous/p/15811843.html
Author: Bingmous
Title: ElasticSearch学习笔记(详细)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/565477/
转载文章受原作者版权保护。转载请注明原作者出处!