

0. 环境准备
本实验基于以下 8 台测试机器进行:
IP hostname 10.4.79.90 hadoop-1 10.4.79.8 hadoop-2 10.4.79.6 hadoop-3 10.4.79.58 hadoop-4 10.4.79.38 hadoop-5 10.4.79.96 hadoop-6 10.4.79.62 hadoop-7 10.4.79.92 hadoop-8
首先确认每个机器都安装了如下软件:
- JAVA >= 1.8.x
- SSH,并确保所有集群节点之间可互相 *SSH免密登录
为集群每个节点配置 hostname: vi /etc/hosts
10.4.79.90 hadoop-1
10.4.79.8 hadoop-2
10.4.79.6 hadoop-3
10.4.79.58 hadoop-4
10.4.79.38 hadoop-5
10.4.79.96 hadoop-6
10.4.79.62 hadoop-7
10.4.79.92 hadoop-8
1. zookeeper 集群搭建
为什么要搭建 zookeeper 集群呢?这是为了保障后续 hadoop 集群的高可用性, zookeeper 可以为 hadoop 集群的主备切换控制器提供主备选举支持。详细搭建步骤移步至 zookeeper 集群搭建
2. hadoop 集群搭建
本文所使用的 hadoop 版本为: 3.2.3
搭建高可用 Hadoop 集群之前,我们需要对集群做一个规划,分配好每个节点在集群中扮演的角色;
hostname NameNode JournalNode ZKFC DataNode ResourceManager NodeManager hadoop-1 Y Y Y Y Y Y hadoop-2 Y Y Y Y Y Y hadoop-3 Y Y Y hadoop-4 Y Y hadoop-5 Y Y hadoop-6 Y Y hadoop-7 Y Y hadoop-8 Y Y
2.1 解压 hadoop 安装包
tar -zxvf hadoop-3.2.3.tar.gz
2.2 添加 hadoop 环境变量
编辑 /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_281
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export HADOOP_HOME=/opt/hadoop-3.2.3
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
编辑 hadoop/etc/hadoop/hadoop-env.sh,配置 JAVA_HOME
The java implementation to use.
export JAVA_HOME=/opt/jdk1.8.0_281
2.3 验证 hadoop 是否安装成功


2.4 配置 hadoop 集群
接着配置 hadoop 的 4 个核心配置文件: core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml,分别对应 hadoop 的 4 个主要组成部分:核心包,HDFS文件系统,MapReduce模型,yarn 资源调度框架。
如果没有相应文件,从当前目录下的模板文件复制:
cp hadoop/etc/hadoop/xxx.site.xml.template hadoop/etc/hadoop/xxx.site.xml
core-site.xml 的配置:
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/data/hadoop
ha.zookeeper.quorum
hadoop-1:2181,hadoop-2:2181,hadoop-3:2181
hdfs-site.xml 的配置
按照我们的规划,选择 hadoop-1,hadoop-2 作为 namenode,hadoop-1,hadoop-2,hadoop-3 作为 journalnode;
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
hadoop-1:9000
dfs.namenode.http-address.mycluster.nn1
hadoop-1:50070
dfs.namenode.rpc-address.mycluster.nn2
hadoop-2:9000
dfs.namenode.http-address.mycluster.nn2
hadoop-2:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop-1:8485;hadoop-2:8485;hadoop-3:8485/mycluster
dfs.journalnode.edits.dir
/data/hadoop/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
dfs.permissions.enabled
false
mapred-site.xml 的配置
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop-1:10020
mapreduce.jobhistory.webapp.address
hadoop-1:19888
yarn-site.xml 的配置
按照我们的规划,选择 hadoop-1,hadoop-2 作为 ResourceManager
yarn.resourcemanager.ha.enabled
true
开启 RM 高可用
yarn.resourcemanager.cluster-id
jyarn
指定 RM 的 cluster id,可以自定义
yarn.resourcemanager.ha.rm-ids
rm1,rm2
指定 RM 的名字,可以自定义
yarn.resourcemanager.hostname.rm1
hadoop-1
分别指定 RM 的地址
yarn.resourcemanager.hostname.rm2
hadoop-2
yarn.resourcemanager.zk-address
hadoop-1:2181,hadoop-2:2181,hadoop-3:2181
指定 zk 集群地址
yarn.nodemanager.aux-services
mapreduce_shuffle
要运行 MapReduce 程序必须配置的附属服务
yarn.resourcemanager.recovery.enabled
true
启用自动恢复
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
设定 resourcemanager 的状态信息存储在 zookeeper 集群上
yarn.nodemanager.resource.memory-mb
8192
每个nodemanager最多分配内存,单位MB
yarn.nodemanager.resource.cpu-vcores
4
每个节点的可用 CPU 虚拟核心数量
yarn.nodemanager.vmem-pmem-ratio
4
yarn.log-aggregation-enable
true
开启 YARN 集群的日志聚合功能
yarn.nodemanager.remote-app-log-dir
/tmp/logs
日志聚合hdfs存储路径
yarn.log-aggregation.retain-seconds
604800
YARN 集群的聚合日志最长保留时长
yarn.nodemanager.delete.debug-delay-sec
604800
应用执行完日志保留的时间,默认0,即执行完立刻删除
2.5 配置集群 workers 节点
编辑 hadoop/etc/hadoop/workers 文件,配置 worker 节点,每行一个:
hadoop-1
hadoop-2
hadoop-3
hadoop-4
hadoop-5
hadoop-6
hadoop-7
hadoop-8
注:hadoop-2.x.x 版本是需要编辑 master 文件作主节点,编辑 slaves 文件作为 worker 节点。因为 slave 这个单词具有别样色彩,在 hadoop-3.x.x 版本中调整为了光荣的工人阶级 worker。
到此,hadoop 的 master 节点配置就基本完成了,将配置好的 hadoop 从 master 节点复制到其它节点, 但要保证 hadoop 在每个节点的存放路径相同, 同时不要忘记在各个节点配置 HADOOP 环境变量。
2.6 启动 JournalNode
分别在每个 journalnode 节点(hadoop-1,hadoop-2,hadoop-3)启动 journalnode 进程:
cd hadoop/sbin
hadoop-daemon.sh start journalnode
2.7 格式化 HDFS 文件系统
在第一个 namenode 节点(hadoop-1)输入以下命令格式化 HDFS 文件系统
hadoop namenode -format
出现以下结果就算成功
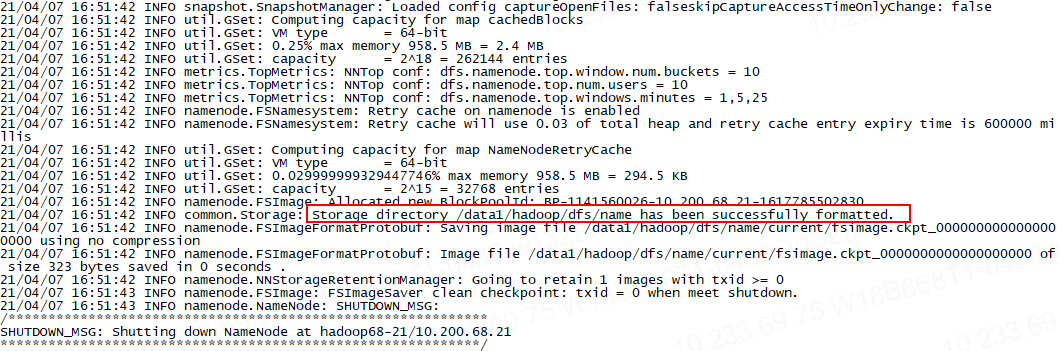
2.8 格式化 ZKFC
任选一个 namenode 节点格式化 ZKFC
hdfs zkfc -formatZK
出现以下信息说明格式化成功:
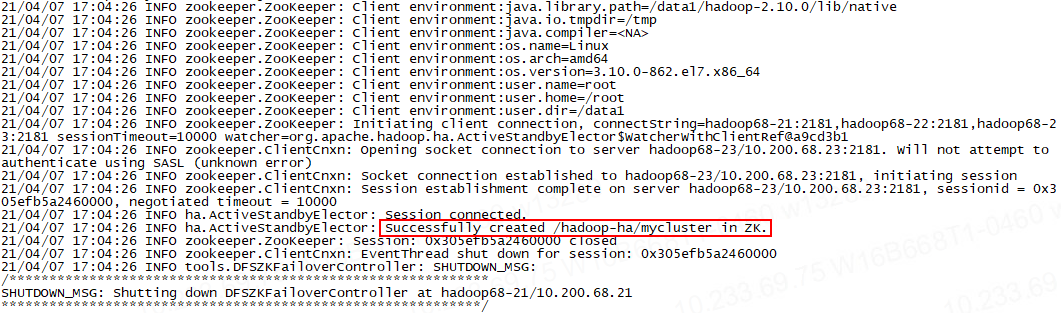
2.9 启动 NameNode:
启动主 namenode(hadoop-1):
./sbin/hadoop-daemon.sh start namenode
在备用 namenode(hadoop-2)上同步元数据:
hadoop namenode -bootstrapStandby
出现以下信息说明元数据同步成功:
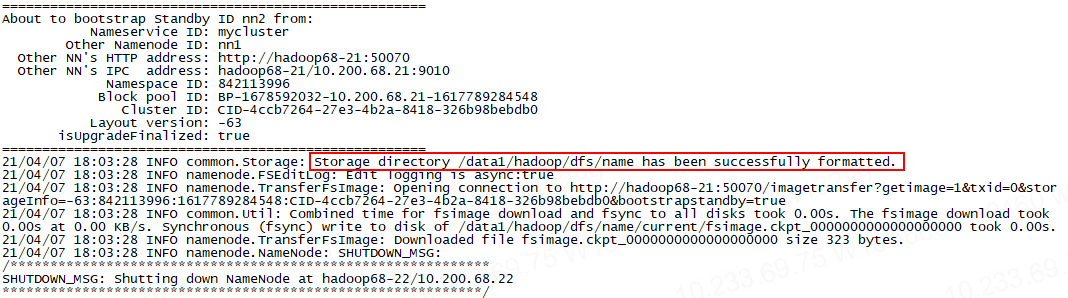
2.10 启动 HDFS
在第一个 namenode 节点(hadoop-1)启动 hdfs:
./sbin/start-dfs.sh
执行个 hdfs 命令测试一下是否启动成功:
hdfs dfs -ls /
如果没有异常输出就代表启动成功。
2.11 启动 YARN
在第一个 resourcemanager 节点(hadoop-1)启动 yarn:
./sbin/start-yarn.sh
在另一个 resourcemanager 节点(hadoop-2)手动启动 resourcemanager:
./sbin/yarn-daemon.sh start resourcemanager
启动成功后,可以在浏览器访问 yarn 管理控制台: http://hadoop-1:8088
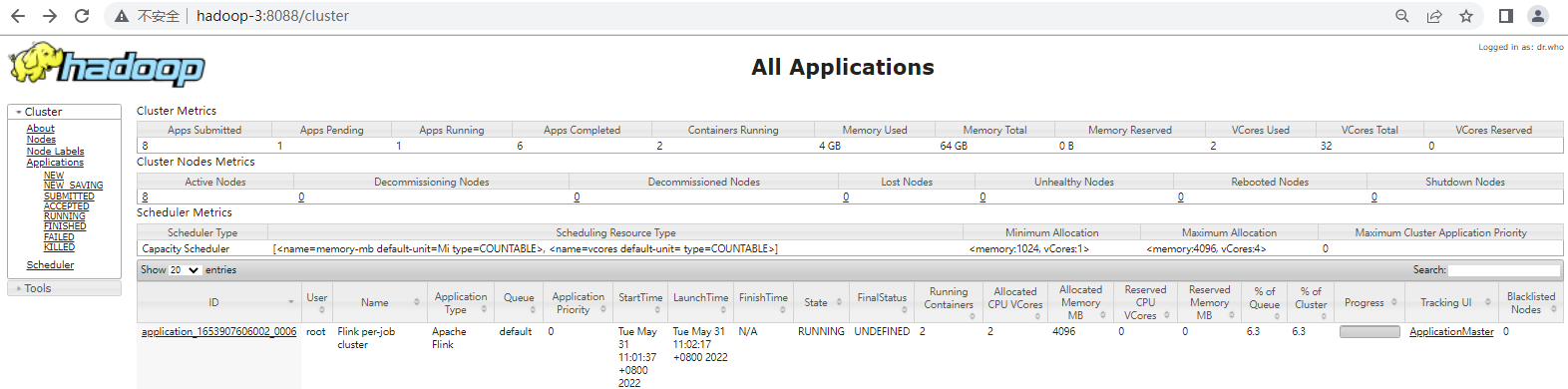
2.12 附
如果想要不重启集群来动态刷新 hadoop 配置可尝试如下方法:
刷新 hdfs 配置
在每个 namenode 节点上执行:
hdfs dfsadmin -fs hdfs://hadoop-1:9000 -refreshSuperUserGroupsConfiguration
hdfs dfsadmin -fs hdfs://hadoop-2:9000 -refreshSuperUserGroupsConfiguration
刷新 yarn 配置
在每个 namenode 节点上执行:
yarn rmadmin -fs hdfs://hadoop-1:9000 -refreshSuperUserGroupsConfiguration
yarn rmadmin -fs hdfs://hadoop-2:9000 -refreshSuperUserGroupsConfiguration
Original: https://www.cnblogs.com/myownswordsman/p/hadoop-environment-prepare.html
Author: watermark’s
Title: Hadoop 环境搭建
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/564948/
转载文章受原作者版权保护。转载请注明原作者出处!