

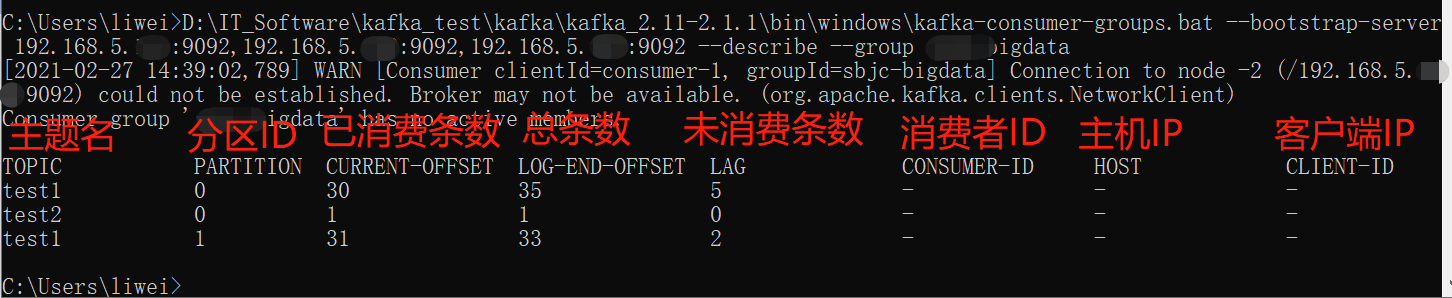
命令格式:kafka-consumer-groups.sh –bootstrap-server IP:端口,IP:端口 –describe –group 组名
例如:./kafka-consumer-groups.sh –bootstrap-server 192.168.110.97:9092 –group group –describe

RabbitMQ 自带一个管理界面, Kafka就比较原始了. 下面比较一下 RabbitMQ和Kafka:
- Kafka支持消息重播. 假如要接入FLink,就不能用RabbitMQ
- RabbitMQ的优势在于能够灵活地路由消息,Kafka不支持路由。 Kafka主题分为多个分区,每个分区包含不可更改的消息
- RabbitMQ支持优先级队列,Kafka中,不能以优先级顺序发送消息。 Kafka中的所有消息都按照接收顺序存储和传递。
- RabbitMQ采用Push 推送消息, Kafka采用Pull请求, 消费者从给定偏移量中请求一批消息
再比较一下 Pulsar和Kafka:
- plusar扩容,增加节点时比kafka更快更方便,P而Puslar是对数据分片,容易扩展 ;Kafka的topic的性能扩展受限于partitions的个数
- 流量负载均衡. Kafka要用商业工具,手动操作.比较麻烦(需求迁移分区,相当增加副本)
- Pulsar分层存储,您可以自动将旧消息推入实际上无限,廉价的云存储. Kafka现在Broker和存储是一体的
选择Pulsar而不是Kafka的5个原因 系列一:关于kafka的思考——后kafka时代下的消息队列,Kafka还会走多远?
Kafka Improvement Proposals – Apache Kafka – Apache Software Foundation
假设每日有1000w条消息, 每条消息10kB, 消息储存7天,用不同的消息队列,价格是多少呢?
消息队列 Pulsar 版 价格总览 按腾讯云这个价格 API 调用12002=2400元,存储价格7TB=7000G0.42/周*3 副本=8820, 主题每月不能超2000个,不然另外收费. 毛估一下每月1万2打住了.但是用Pulsar的假如是多租户在用,主题数可能是10w+, 假如按0.2元/个/天的主题价格, 那不是要60万了???? 我算错了吗?
阿里云kafka 计算下来1个月1万左右, 感觉2者价格差不多
消息队列 RabbitMQ 版包年包月, 每日有1000w条消息折算下面每秒才115条消息*2=230, 选用TPS 10000/秒就应该绰绰有余了, 一个月才1300,便宜好多啊, 不过阿里云最高TPS才5000/秒, 超过这个数量的还是选择Pulsar了吧.
用kafkaTemplate 一个连接连续发送10w条记录,用8个线程发只需要1.6秒.在发送的同时接收,10w条记录4秒,速度真的挺快的哦!!!
多线程发送,消息是乱序的, 假如要有次序,只用1个线程发,3.6秒
在console统计不了那么多,要写log,有2个配置文件要配一下
logging:
#level 日志等级 指定命名空间的日志输出
level:
com.fishpro.kafka: debug #根据包名修改
#file 指定输出文件的存储路径
#file: logs/app.log
#pattern 指定输出场景的日志输出格式
pattern:
console: "%d %-5level %logger : %msg%n"
file: "%d %-5level [%thread] %logger : %msg%n"

"1.0" encoding="UTF-8"?>
"true" scanPeriod="60 seconds" debug="false">
logback
"console" class="ch.qos.logback.core.ConsoleAppender">
%d{HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n
UTF-8
"logFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
true
class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
applog/%d{yyyy-MM-dd}/%d{yyyy-MM-dd}.log
15
class="ch.qos.logback.classic.PatternLayout">
%d{yyyy-MM-dd HH:mm:ss} -%msg%n
"com.fishpro.kafka" additivity="false">
ref ref="console"/>
ref ref="logFile"/>
"org.springframework" level="WARN"/>
"org.mybatis" level="WARN"/>"com.ibatis" level="DEBUG"/>"com.ibatis.common.jdbc.SimpleDataSource" level="DEBUG"/>"com.ibatis.common.jdbc.ScriptRunner" level="DEBUG"/>"com.ibatis.sqlmap.engine.impl.SqlMapClientDelegate" level="DEBUG"/>"java.sql.Connection" level="DEBUG"/>"java.sql.Statement" level="DEBUG"/>"java.sql.PreparedStatement" level="DEBUG"/>"com.ruidou.baoqian.mapper" level="DEBUG"/>
"error">
ref ref="console"/>
ref ref="logFile"/>
logback-spring.xml
kafka客户端自己决定写到哪个分区还是kafka来决定?
对消息顺序一致无强需求的场景下用kafka默认策略即可。也方便group多线程/进程消费,增加消费者吞吐。对消息顺序一致有强需求时可以将消息统一发送到同一partition,可保证消息先进先出。但对消费者吞吐产生影响。
生产者在生产数据的时候,可以为每条消息指定Key,这样消息被发送到broker时,会根据分区规则选择被存储到哪一个分区中,如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡和水平扩展。
java;gutter:true;
public class SimplePartitioner implements Partitioner { @Override public int partition(Object key, int numPartitions) {
int partition = 0;</p>
<pre><code> String k = (String) key;
partition = Math.abs(k.hashCode()) % numPartitions;
return partition;
}
</code></pre>
<p>}</p>
<pre><code>
如果10w个连接,每个连接发一条消息呢?
kafka如何限制连接数呢?
如何保证kafka消息不会丢失呢?
</code></pre>
<p>1.生产端:使用带回调的发送方法,设置acks=all (所有副本都收到),重试次数</p>
<ol>
<li>
<p>消费端: 关闭自动位移避免消费丢失</p>
</li>
<li>
<p>Broker端: 设置replication.factor=3, min.insync.replicas=2
kafka的可视化工具 Kafka 可视化工具(Kafka Tool)
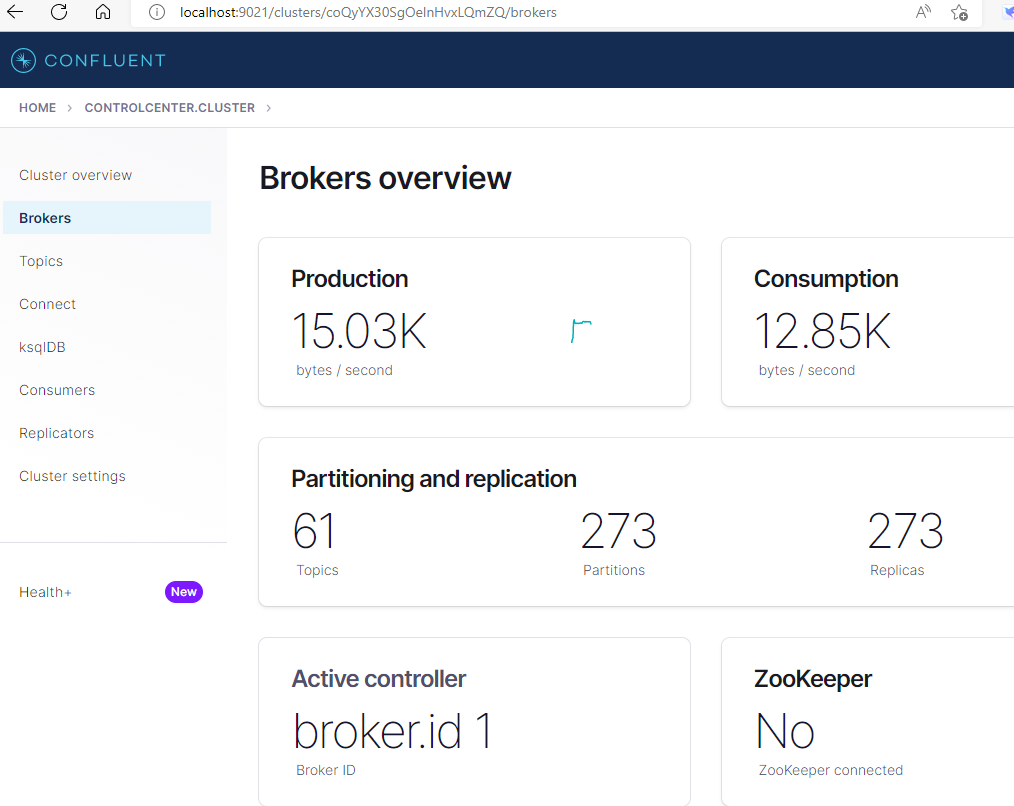
套装版 带control center 需要License Quick Start for Confluent Platform
为了将 MQTT 消息集成到 Kafka 集群中,您需要某种类型的桥接器将 MQTT 消息转发到 Kafka 中。有四种不同的方法
-
Kafka Connect for MQTT 充当 MQTT 客户端,它订阅来自 MQTT 代理的所有消息 存在性能和可伸缩性问题
-
MQTT Proxy,需要一个功能齐全的 MQTT 代理。如果可以忍受消息丢失,那么代理方法可能是一种轻量级的替代方案
3 您自己的自定义桥接器,需要大量的开发工作,有可能崩溃,丢失消息
- MQTT 代理扩展 MQTT 代理经过扩展,包括一个本机 Kafka 客户端,并将 MQTT 消息转置到 Kafka 协议。这允许物联网数据同时路由到多个Kafka集群和非Kafka应用程序。使用 MQTT 代理还将提供对 IoT 设备所需的所有 MQTT 功能的访问,例如遗嘱和遗嘱。像 HiveMQ 这样的 MQTT 代理旨在实现高可用性、持久性、性能和弹性,因此可以在 Kafka 不可写的情况下在代理上缓冲消息,因此重要消息永远不会从 IoT 设备丢失。
Original: https://www.cnblogs.com/zitjubiz/p/kafka_FAQ.html
Author: Gu
Title: Kafka FAQ
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/564914/
转载文章受原作者版权保护。转载请注明原作者出处!