

前文
- 一、Windows系统下安装Tensorflow2.x(2.6)
- 二、深度学习-读取数据
- 三、Tensorflow图像处理预算
- 四、线性回归模型的tensorflow实现
- 五、深度学习-逻辑回归模型
- 六、AlexNet实现中文字体识别——隶书和行楷
- 七、VGG16实现鸟类数据库分类
- 七、VGG16+BN(Batch Normalization)实现鸟类数据库分类
- 七、BatchNormalization使用技巧
数据生成器+数据部分展示
#猫狗分类。数据增强
#数据生成器生成测试集
from keras.preprocessing.image import ImageDataGenerator
IMSIZE = 128
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'../../data/dogs-vs-cats/smallData/validation',
target_size=(IMSIZE, IMSIZE),
batch_size=10,
class_mode='categorical'
)


[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:6fb88c95-613f-4926-8260-2aa0fe5f4f63<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:b60fec33-6ab1-482c-991f-ce564af02e4f</font>*</details>
train_generator = ImageDataGenerator(rescale=1. / 255, shear_range=0.5, rotation_range=30,
zoom_range=0.2, width_shift_range=0.2, height_shift_range=0.2
).flow_from_directory('../../data/dogs-vs-cats/smallData/train',
target_size=(IMSIZE, IMSIZE), batch_size=10,
class_mode='categorical')

数据来源kaggle的猫狗数据
#展示数据增强后的图像
from matplotlib import pyplot as plt
plt.figure()
fig, ax = plt.subplots(2, 5)
fig.set_figheight(6)
fig.set_figwidth(15)
ax = ax.flatten()
X, Y = next(validation_generator)
for i in range(10): ax[i].imshow(X[i, :, :, ])
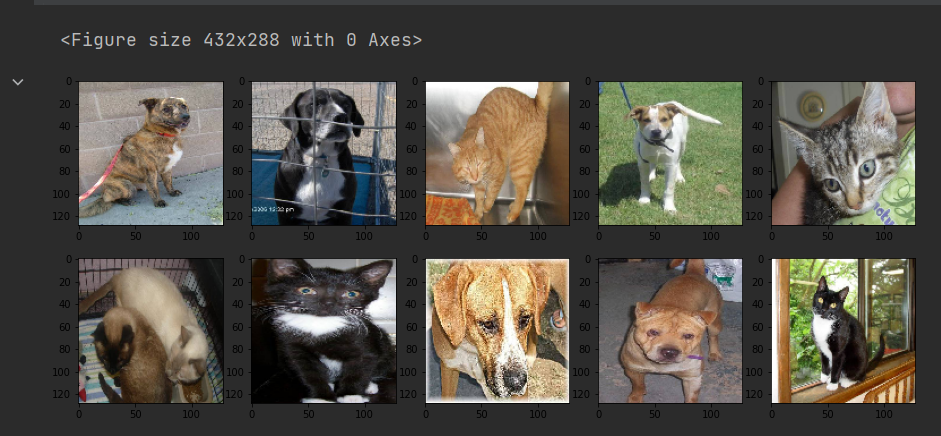
数据增强模型
#数据增强模型
IMSIZE = 128
from keras.layers import BatchNormalization, Conv2D, Dense, Flatten, Input, MaxPooling2D
from keras import Model
n_channel = 100
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
x =BatchNormalization()(x)
for _ in range(7):
x =BatchNormalization()(x)
x =Conv2D(n_channel,[2,2],padding='same',activation='relu')(x)
x =MaxPooling2D([2,2])(x)
x =Flatten()(x)
x =Dense(2,activation='softmax')(x)
output_layer = x
model = Model(input_layer,output_layer)
model.summary()
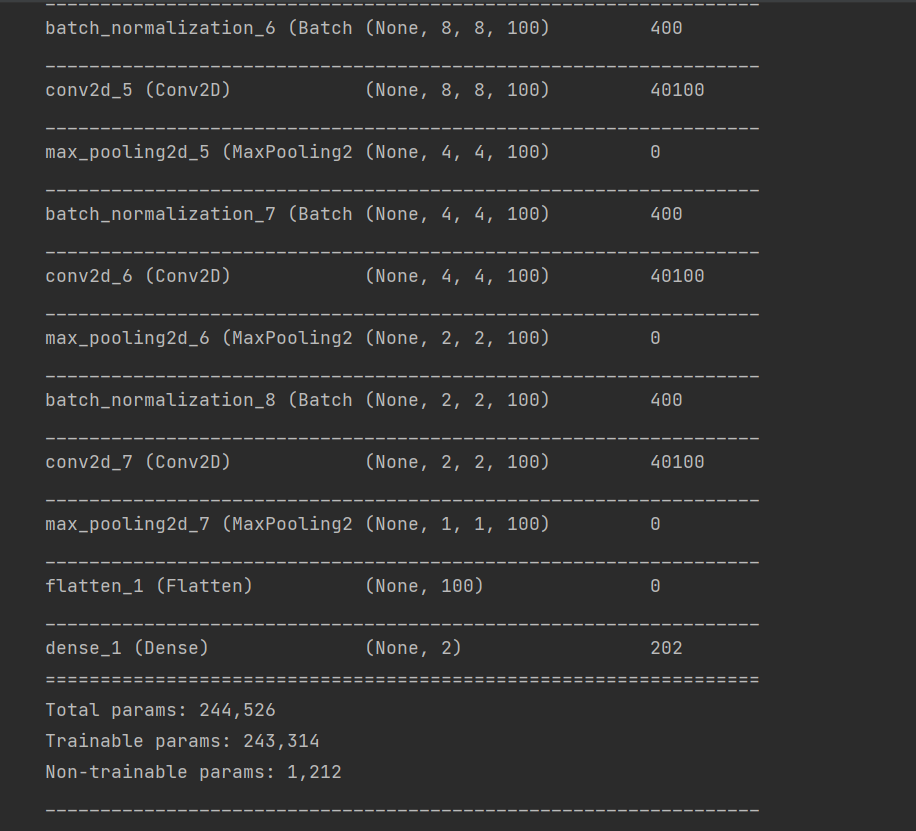
数据增强模型的编译与拟合
#数据增强模型的编译与拟合
from keras.optimizers import Adam
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001),
metrics=['accuracy'])
model.fit_generator(train_generator,
epochs=200,
validation_data=validation_generator)

GitHub下载地址:
Original: https://www.cnblogs.com/lehoso/p/15643960.html
Author: 李好秀
Title: 七、Data Augmentation技巧
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/563741/
转载文章受原作者版权保护。转载请注明原作者出处!