

聚类方法
原型聚类
原型是指样本空间中具有代表性的点。此类算法假设聚类结构能通过一组原型刻画,在现实聚类中极为常用。如:k-means、高斯混合聚类
高斯混合聚类::
层次聚类
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:e82f27d3-b4f3-436c-a85f-8aec282c45a7
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:62346fe1-9fd4-476b-a738-dc2716502c03
聚合层次聚类的基本思想:
1)计算数据集的相似矩阵;
2)假设每个样本点为一个簇类;
3)循环:合并相似度最高的两个簇类,然后更新相似矩阵;
4)当簇类个数为1时,循环终止;
聚类流程如下图所示。 此处核心是如何计算各簇类间的距离
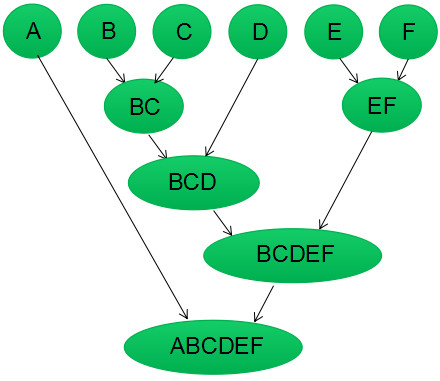

簇间相似度的计算方法:最小距离、最大距离、平均距离、中心距离、最小方差法
算法复杂度:空间复杂度=O(n2), 时间复杂度:O(n3)
算法优化:我们可以 通过连通性约束(connectivity constraint)降低算法复杂度,甚至提高聚类结果。具体实现如下:
from sklearn.neighbors import kneighbors_graph
connectivity = kneighbors_graph(X, n_neighbors=10, include_self=False)
ward = AgglomerativeClustering(n_clusters=6, connectivity=connectivity,
linkage='ward').fit(X)
参考文献:https://mp.weixin.qq.com/s/u5EeRfq4AjP14DRbftZ6AQ
密度聚类
常用密度聚类:DBSCAN、最小熵聚类
评价指标
实际应用
Original: https://blog.csdn.net/u012409283/article/details/121509363
Author: 真炎破天
Title: 相似文本聚类
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/563185/
转载文章受原作者版权保护。转载请注明原作者出处!