

算法的完整实现代码我已经上传到了GitHub仓库:Distributed-ML-PySpark(包括其它分布式机器学习算法),感兴趣的童鞋可以前往查看。
1 分布式机器学习概述
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:78d8c540-4a3e-44ca-9aca-83379e25df9e
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:e70c3167-bc99-4930-be11-61a4674b51c4
1)对于计算量大的问题,分布式多机并行运算可以基本解决。不过需要与传统HPC中的共享内存式的多线程并行运算(如OpenMP)以及CPU-GPU计算架构做区分,这两种单机的计算模式我们一般称为 计算并行。
2)对于训练数据大的问题,需要将数据进行划分并分配到多个工作节点(Worker)上进行训练,这种技巧一般被称为 数据并行。每个工作节点会根据局部数据训练出一个本地模型,并且会按照一定的规律和其他工作节点进行通信(通信内容主要是本地模型参数或者参数更新),以保证最终可以有效整合来自各个工作节点的训练结果并得到全局的机器学习模型。


如果是训练数据的样本量比较大,则需要对数据按照样本进行划分,我们称之为”数据样本划分”,按实现方法可分为”随机采样法”和”置乱切分法”。样本划分的合理性在于机器学习中的经验风险函数关于样本是可分的,我们将每个子集上的局部梯度平均,仍可得到整个经验风险函数的梯度。
如果训练数据的维度较高,还可对数据按照维度进行划分,我们称之为”数据维度划分”。它相较数据样本划分而言,与模型性质和优化方法的耦合度更高。如神经网络中各维度高度耦合,就难以采用此方式。不过,决策树对维度的处理相对独立可分,将数据按维度划分后,各节点可独立计算局部维度子集中具有最优信息增益的维度,然后进行汇总。此外,在线性模型中,模型参数与数据维度是一一对应的,故数据维度划分常与下面提到的模型并行相互结合。
3)对于模型规模大的问题,则需要对模型进行划分,并且分配到不同的工作节点上进行训练,这种技巧一般被称为 模型并行。与数据并行不同,模型并行的框架下各个子模型之间的依赖关系非常强,因为某个子模型的输出可能是另外一个子模型的输入,如果不进行中间计算结果的通信,则无法完成整个模型训练。因此,一般而言,模型并行相比数据并行对通信的要求更高。

这里提一下数据样本划分中的几种划分方式。给定(n)个(d)维样本和(K)个工作节点,数据样本划分需要完成的任务是将(n)个样本以某种形式分配到(K)个工作节点上。
随机采样法中我们独立同分布地从(n)个样本中有放回随机采样,每抽取一个样本将其分配到一个工作节点上。这个过程等价于先随机采(n)个样本,然后均等地划分为(K)份。
随机采样法便于理论分析,但基于实现难度的考虑,在工程中更多采用的是基于置乱切分的划分方法。即现将(n)个样本随机置乱,再把数据均等地切分为(K)份,再分配到(K)个节点上进行训练。置乱切分相当于无放回采样,每个样本都会出现在某个工作节点上,每个工作节点的本地数据没有重复,故训练数据的信息量一般会更大。我们下面的划分方式都默认采取置乱切分的方法。
我们在后面的博客中会依次介绍针对数据并行和模型并行设计的各种分布式算法。本篇文章我们先看数据并行中最常用的同步并行SGD算法(也称SSGD)是如何在Spark平台上实现的。
2 同步并行SGD算法描述与实现
SSGD[1]对应的伪代码可以表述如下:

其中,SSGD算法每次依据来自(K)个不同的工作节点上的样本的梯度来更新模型,设每个工作节点上的小批量大小为(b),则该算法等价于批量大小为(bK)
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:563b80ca-acdd-40ba-84c2-6d46542b5431
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:4aba3388-6397-4b93-a5ad-4ec42022c15b
我们令(f)为逻辑回归问题的正则化经验风险。设(w)为权值(最后一维为偏置),样本总数为(n),({(x_i, y_i)}_{i=1}^n)为训练样本集。样本维度为(d),(x_i\in \mathbb{R}^{d+1})(最后一维扩充),(y_i\in{0, 1})。则(f)表示为:
[f(w) = \frac{1}{n} \sum_{i=1}^{n}\left[y_{i} \log \pi_{w}\left(x_{i}\right)+\left(1-y_{i}\right) \log \left(1-\pi_w\left(x_{i}\right)\right)\right] + \lambda R(w) ]
这里
[\begin{aligned} \pi_w(x) = p(y=1 \mid x; w) =\frac{1}{1+\exp \left(-w^{T} x\right)} \end{aligned} ]
其梯度表示如下:
[\nabla f{(w)} = -\sum_{i=1}^n(y_i – \frac{1}{\exp(-w^Tx)+1})x_i + \lambda\nabla R(w) ]
这里正则项的梯度(\nabla R(w))要分情况讨论:
(1) 不使用正则化
此时显然(\nabla R(w)=0)。
(2) L2正则化((\frac{1}{2}\lVert w\rVert^2_2))
此时(\nabla R(w)=w)。
(3) L1正则化((\lVert w \rVert_1))
该函数不是在每个电都对(w)可导,只来采用函数的次梯度(subgradient)来进行梯度下降。(\lVert w \rVert_1)的一个比较好的次梯度估计是(\text{sign}(w))。相比于标准的梯度下降,次梯度下降法不能保证每一轮迭代都使目标函数变小,所以其收敛速度较慢。
(4) Elastic net正则化((\alpha \lVert w \rVert_1 + (1-\alpha)\frac{1 }{2}\lVert w\rVert^2_2))
对(\lVert w\rVert_1)使用次梯度计算式,(\frac{1}{2}\lVert w\rVert_2^2)使用其梯度计算式,得最终的梯度计算式为(\alpha \text{sign}(w) + (1-\alpha) w)。
我们约定计算第(K)个节点小批量(\mathcal{I_k})的经验风险的梯度(\nabla f_{\mathcal{I_k}}(x))时不包含正则项的梯度,最终将(K)个节点聚合后再加上正则项梯度。
用PySpark对上述算法实现如下(因为不存在明显过拟合现象,我们令正则系数(\lambda)为0):
from sklearn.datasets import load_breast_cancer
import numpy as np
from pyspark.sql import SparkSession
from operator import add
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import sys
import os
os.environ['PYSPARK_PYTHON'] = sys.executable
n_threads = 4 # Number of local threads
n_iterations = 1500 # Number of iterations
eta = 0.1
mini_batch_fraction = 0.1 # the fraction of mini batch sample
lam = 0 # coefficient of regular term
def logistic_f(x, w):
return 1 / (np.exp(-x.dot(w)) + 1)
def gradient(point: np.ndarray, w: np.ndarray):
""" Compute linear regression gradient for a matrix of data points
"""
y = point[-1] # point label
x = point[:-1] # point coordinate
# For each point (x, y), compute gradient function, then sum these up
return - (y - logistic_f(x, w)) * x
def reg_gradient(w, reg_type="l2", alpha=0):
""" gradient for reg_term
"""
assert(reg_type in ["none", "l2", "l1", "elastic_net"])
if reg_type == "none":
return 0
elif reg_type == "l2":
return w
elif reg_type == "l1":
return np.sign(w)
else:
return alpha * np.sign(w) + (1 - alpha) * w
def draw_acc_plot(accs, n_iterations):
def ewma_smooth(accs, alpha=0.9):
s_accs = np.zeros(n_iterations)
for idx, acc in enumerate(accs):
if idx == 0:
s_accs[idx] = acc
else:
s_accs[idx] = alpha * s_accs[idx-1] + (1 - alpha) * acc
return s_accs
s_accs = ewma_smooth(accs, alpha=0.9)
plt.plot(np.arange(1, n_iterations + 1), accs, color="C0", alpha=0.3)
plt.plot(np.arange(1, n_iterations + 1), s_accs, color="C0")
plt.title(label="Accuracy on test dataset")
plt.xlabel("Round")
plt.ylabel("Accuracy")
plt.savefig("ssgd_acc_plot.png")
if __name__ == "__main__":
X, y = load_breast_cancer(return_X_y=True)
D = X.shape[1]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=0, shuffle=True)
n_train, n_test = X_train.shape[0], X_test.shape[0]
spark = SparkSession\
.builder\
.appName("SSGD")\
.master("local[%d]" % n_threads)\
.getOrCreate()
matrix = np.concatenate(
[X_train, np.ones((n_train, 1)), y_train.reshape(-1, 1)], axis=1)
points = spark.sparkContext.parallelize(matrix).cache()
# Initialize w to a random value
w = 2 * np.random.ranf(size=D + 1) - 1
print("Initial w: " + str(w))
accs = []
for t in range(n_iterations):
print("On iteration %d" % (t + 1))
w_br = spark.sparkContext.broadcast(w)
(g, mini_batch_size) = points.sample(False, mini_batch_fraction, 42 + t)\
.map(lambda point: gradient(point, w_br.value))\
.treeAggregate(
(0.0, 0),\
seqOp=lambda res, g: (res[0] + g, res[1] + 1),\
combOp=lambda res_1, res_2: (res_1[0] + res_2[0], res_1[1] + res_2[1])
)
w -= eta * (g/mini_batch_size + lam * reg_gradient(w, "l2"))
y_pred = logistic_f(np.concatenate(
[X_test, np.ones((n_test, 1))], axis=1), w)
pred_label = np.where(y_pred < 0.5, 0, 1)
acc = accuracy_score(y_test, pred_label)
accs.append(acc)
print("iterations: %d, accuracy: %f" % (t, acc))
print("Final w: %s " % w)
print("Final acc: %f" % acc)
spark.stop()
draw_acc_plot(accs, n_iterations)
我们尝试以(\lambda=0)的正则系数运行。初始权重如下:
Initial w: [-0.36008689 -0.56946672 -0.111438 -0.69218272 0.14209017 -0.03984532
0.94087485 0.04861045 -0.61083642 -0.64141307 0.94030259 0.30646586
0.02675997 0.11238215 -0.86864834 -0.47662071 -0.0493882 -0.73569782
-0.92104136 0.91834097 -0.05942094 0.06995983 -0.3099812 -0.87308266
0.55421184 0.02251628 0.83765882 -0.69977596 0.02591093 -0.28081701
-0.21881969]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:a862c4ba-602b-4301-a3f7-4aca9f244e41
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:0175b26d-456c-422d-b185-c0f9d7117900
Final w: [ 3.58216967e+01 4.53599397e+01 2.07040135e+02 8.52414269e+01
4.33038042e-01 -2.93986236e-01 1.43286366e-01 -2.95961229e-01
-7.63362321e-02 -3.93180625e-01 8.19325971e-01 3.30881477e+00
-3.25867503e+00 -1.24769634e+02 -8.52691792e-01 -5.18037887e-01
-1.34380402e-01 -7.49316038e-01 -8.76722455e-01 9.23748261e-01
3.81531205e+01 5.56880612e+01 2.04895002e+02 -1.17586430e+02
8.92355523e-01 -9.40611324e-01 -9.24082612e-01 -1.16210791e+00
7.10117706e-01 -7.62921434e-02 4.48389687e+00]
Final acc: 0.929825
回忆一下我们在博客《分布式机器学习:逻辑回归的并行化实现(PySpark) 》中在同样的超参数下,测得同步并行梯度下降(非随机)学到的模型的精度为0.941520,可见SSGD引入的随机梯度对算法收敛有一定影响。具体的算法收敛性分析我们在第3部分中分析。
代码中有两个关键点,一个是 points.sample(False, mini_batch_fraction, 42 + t)。函数 sample负责返回当前RDD的一个随机采样子集(包含所有分区),其原型为:
RDD.sample(withReplacement: bool, fraction: float, seed: Optional[int] = None) → pyspark.rdd.RDD[T]
参数 withReplacement的值为 True表示采样是有放回(with Replacement, 即replace when sampled out),为 False则表示无放回 (without Replacement)。如果是有放回,参数 fraction表示每个样本的期望被采次数,fraction必须要满足(\geqslant0);如果是无放回,参数 fraction表示每个样本被采的概率,fraction必须要满足位于([0, 1])区间内。
还有一个关键点是
.treeAggregate(
(0.0, 0),\
seqOp=lambda res, g: (res[0] + g, res[1] + 1),\
combOp=lambda res_1, res_2: (res_1[0] + res_2[0], res_1[1] + res_2[1])
)
该函数负责对RDD中的元素进行树形聚合,它在数据量很大时比 reduce更高效。该函数的原型为
RDD.treeAggregate(zeroValue: U, seqOp: Callable[[U, T], U], combOp: Callable[[U, U], U], depth: int = 2) → U[source]
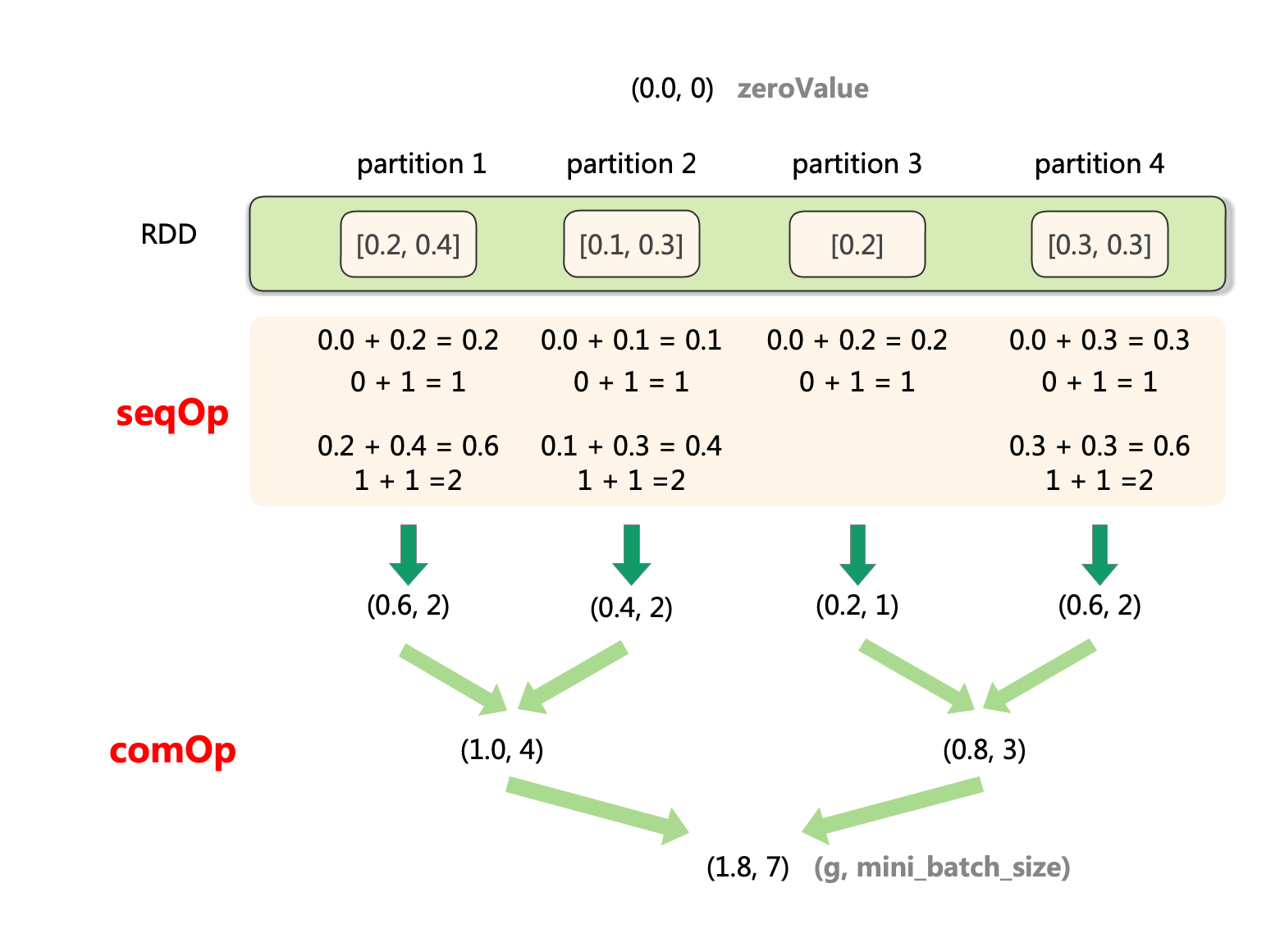
其中 zeroValue为聚合结果的初始值, seqOp函数用于定义单分区(partition)做聚合操作的方法,该方法第一个参数为聚合结果,第二个参数为分区中的数据变量,返回更新后的聚合结果。 combOp定义对分区之间做聚合的方法,该方法第一个参数为第二个参数都为聚合结果,返回累加后的聚合结果。 depth为聚合树的深度。
我们这里 treeAggregate想要聚合得到一个元组 (g, mini_batch_size), g为所有节点样本的随机梯度和, mini_batch_size为所有节点所采的小批量样本之和,故我们将聚合结果的初始值 zeroVlue初始化为 (0,0, 0)。具体的聚合过程描述如下:
- 对每个partition:
a. 初始化聚合结果为(0.0, 0)。
b. 对当前partition的序列元素,依次执行聚合操作seqOp。
c. 得到当前partition的聚合结果(partition_sum, partition_count)。 - 对所有partition:
a. 按照树行模式合并各partition的聚合结果,合并方法为combOp。
b. 得到合并结果(total_sum, total_count)。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:1deee005-530e-4586-8bdd-070a5fd6ca10
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:4bc2e421-3eb8-49e8-b485-84ce3acfdb84
3 算法收敛性及复杂度分析
3.1 收敛性和计算复杂度
该算法最终得到的ACC曲线如下图所示:

我们将其与在同样超参数设置下的同步梯度下降法(非随机)的ACC曲线对比(如下是同步梯度下降法的ACC曲线):
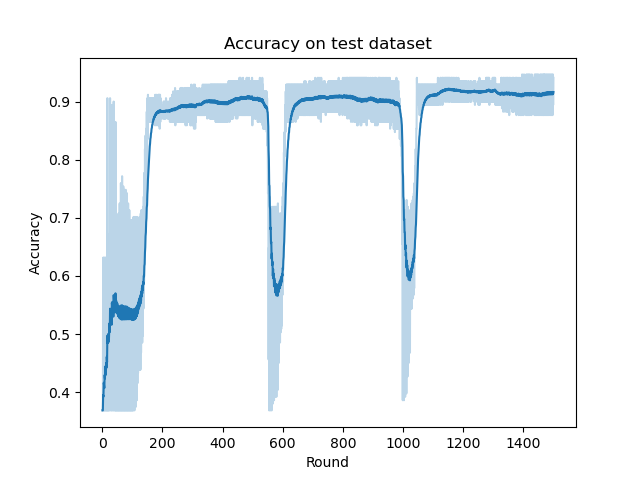
可以看到SSGD的收敛速率相同步并行梯度下降有所降低。正如我们在博客《数值优化:经典随机优化算法及其收敛性与复杂度分析》中所说的,虽然随机梯度是是全梯度的无偏估计,但这种估计存在一定的方差,会引入不确定性,导致最终算法的收敛速率下降。
这里的损失函数(l( \space \cdot \space ))是光滑凸函数(非强凸函数,它只在局部呈现强凸性),如我们在该博客中所分析,若目标函数(f: \mathbb{R}^d\rightarrow \mathbb{R})是凸函数,并且(L)-Lipschitz连续,(w^* = \underset{\lVert w\rVert\leqslant D}{\text{arg min}}f(w)),当步长(\eta^t = \sqrt{\frac{D^2}{L^2t}})时,对于给定的迭代步数(T),随机梯度下降法具有(\mathcal{O}(\frac{1}{\sqrt{T}}))的次线性收敛速率:
[\mathbb{E}[ \frac{1}{T}\sum_{t=1}^T f(w^t) – f(w^*) ] \leqslant \frac{LD}{\sqrt{T}} ]
这意味着随机梯度下降法求解逻辑回归问题的迭代次数复杂度为(\mathcal{O}(\frac{1}{\varepsilon^2})),也即(\mathcal{O}(\frac{1}{\varepsilon^2}))轮后会取得(\varepsilon)的精度。
尽管梯度的计算可以被分摊到个计算节点上,然而梯度下降的迭代是串行的。每轮迭代中,Spark会执行同步屏障(synchronization barrier)来确保在各worker开始下一轮迭代前(w)已被更新完毕。如果存在掉队者(stragglers),其它worker就会空闲(idle)等待,直到下一轮迭代。故相比梯度的计算,其迭代计算的”深度”(depth)是其计算瓶颈。
3.2 通信复杂度
map过程显然是并行的,并不需要通信。broadcast过程需要一对多通信,并且reduce过程需要多对一通信(都按照树形结构)。故对于每轮迭代,总通信时间按
[2\text{log}_2(p)(L + \frac{m}{B}) ]
增长。
这里(p)为除去driver节点的运算节点个数,(L)是节点之间的通信延迟。(B)是节点之间的通信带宽。(M)是每轮通信中节点间传输的信息大小。故消息能够够以(\mathcal{O}(\log p))的通信轮数在所有节点间传递。
参考
-
[1] Zinkevich M, Weimer M, Li L, et al. Parallelized stochastic gradient descent[J]. Advances in neural information processing systems, 2010, 23.
- [3] PySpark文档:pyspark.RDD.treeAggregate函数
-
[4] 刘浩洋,户将等. 最优化:建模、算法与理论[M]. 高教出版社, 2020.
-
[5] 刘铁岩,陈薇等. 分布式机器学习:算法、理论与实践[M]. 机械工业出版社, 2018.
-
[6] Stanford CME 323: Distributed Algorithms and Optimization (Lecture 7)
Original: https://www.cnblogs.com/orion-orion/p/16413182.html
Author: orion-orion
Title: 分布式机器学习:同步并行SGD算法的实现与复杂度分析(PySpark)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/562899/
转载文章受原作者版权保护。转载请注明原作者出处!