

前言
VOLT是Mike Stonebraker 博士主导开发的云原生的内存数据库。他是唯一原生分布式的数据库。VOLT降低了服务器资源开销,通过使用低廉的服务器,在其架构上面,实现高吞吐率gps。同时VOLT提供开源版本和商业发行版本,与行业间有大量的深入交流。 >
VOLT于2017年进入中国市场,现在已经拥有大量中国客户,应用场景包括电信、金融系统、核心网计费解决方案等 ,遍布全国。
1
针对老生常谈的数据库设计原则的技术探索
通过对传统数据库分析发现, 88%的CPU时间耗费在分布式的并发控制以及缓存管理上。对于传统数据库,尤其是关系型数据库而言,这是一些不得不面对的痛点。那这些痛点是无法解决的吗?还是说我们只能靠堆资源、 堆机器去解决呢?还是说另有其他的思路?
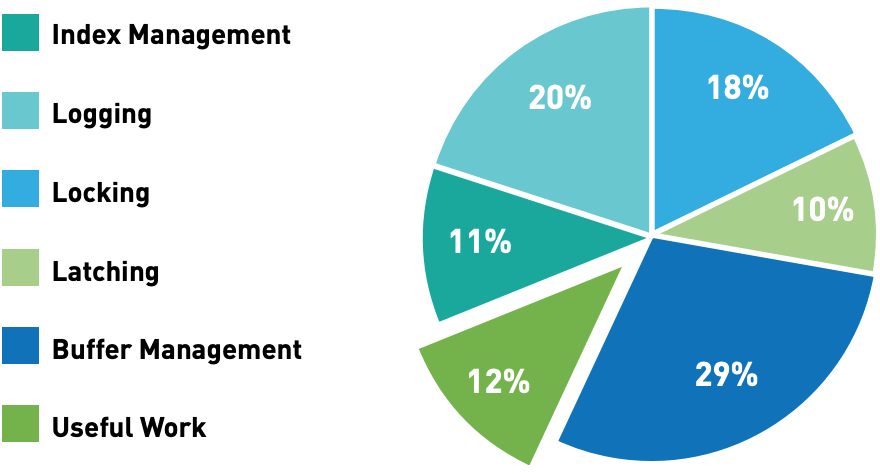

1、 事务隔离级别
VOLT采用了最严格的序列化的方式,同时用单分区的序列化,然后又多分区的并行,来应对。
2 、CAP
VOLT最初设计的时候,探讨在一些极端的情况下,CAP不是你能做什么,而是做不到什么?怎么办?
VOLT在考虑了衡量工具的情况下,做了一些对应机制的设计,包括部分副本崩溃情况下的应对策略(如,活跃的副本提供服务)、多副本活跃但同步失效情况下的应对策略(多副本活跃但同步失效情况下的应对策略(如:VOLT提供 brain split 侦测))。
3 、Lock&Latch
在传统的关系型数据库中,Lock&Latch开销非常大,尤其在分布式系统下,一旦横向扩容到比较大程度,以及存在一些死锁,尤其分布式锁的情况下,其所带来的锁的性能的损失非常巨大,这也就是很多传统数据库无法横向扩容的一个重要原因。
而VOLT所用机制则基本上把锁开销就完全取消掉。
4 、并行Parallel vs. 并发 Concurrent
并行指”真的在有两个咖啡机”;并发指”看起来有两个队伍,但其实只有一个咖啡机”。VOLT使用了分区并行的策略和事务队列串行化的策略结合,能够实现惊人的gps,另外一方面又避免了锁的开销。
2
VOLT的解决落地
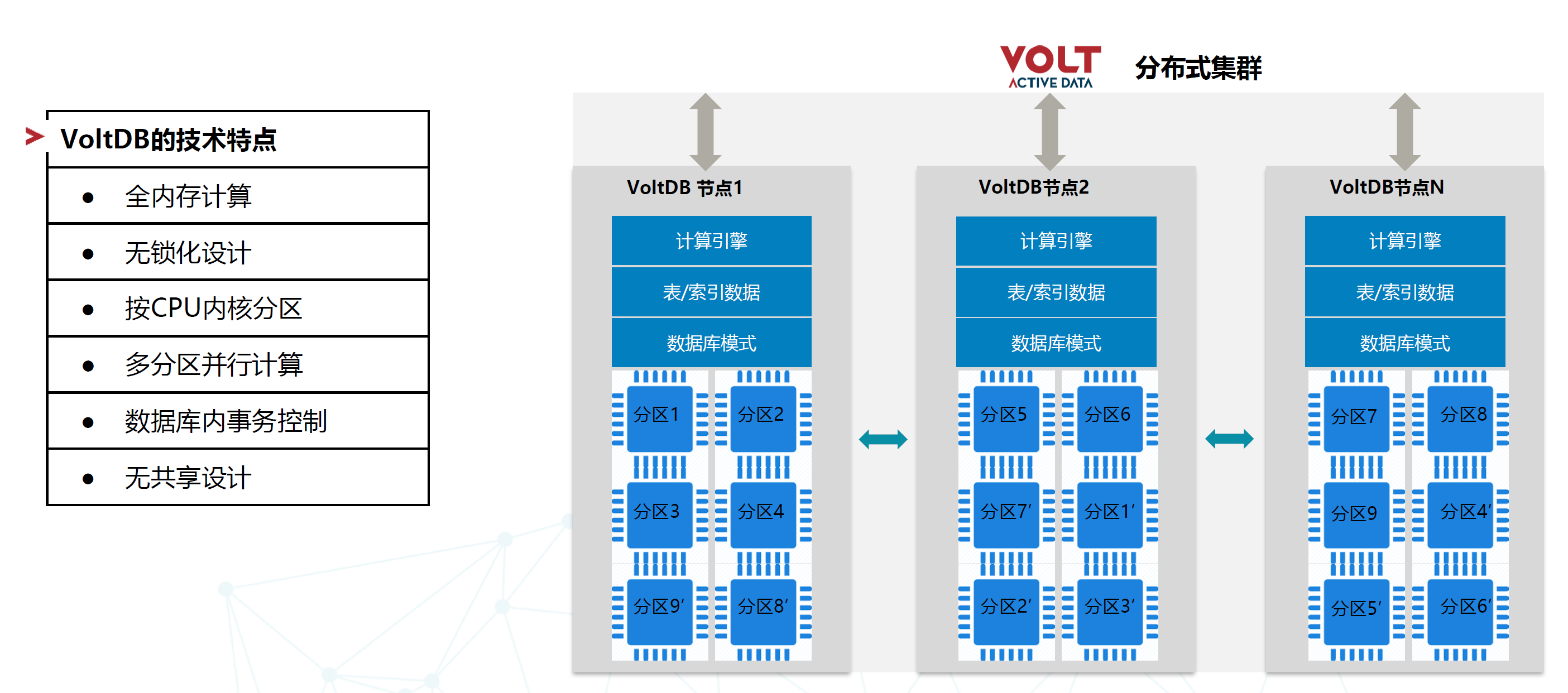
首先VOLT是一个权力存基层的,也就是说所有的数据,包括计算的逻辑、数据的存储、表设计的结构啊,都是在内存中,分布在各个节点中这些节点之间大部分情况下是没有锁的。
VOLT每个节点上面都有一定量的分区,分区之间通过内部的机制,可以把它分散到各个节点上去,这样可以防止单节点故障。
VOLT还有一个重要特点——按CPU内核分区,一个节点上面比方说有24个核,建议16个左右的分区,这样每个CPU都对应一个分区,捆绑在上面后,每个分区上面的事物都是串行的情况下,便完全避免了锁的开销。
VOLT多个分区之间完全并行,从CPU到Thread到内存(包括共享内存)到网络到硬盘,整个一条线都是并行的。
同时VOLT能够实现数据库内的事务控制,即业务层不需要关心事物的处理。VOLT选择讲所有的事务都在集群内完成的机制,对于client 来说,无需控制事务。
此外VOLT采用无共享设计,能够避免瓶颈。从CPU 到内存到网络,没有share,全部分布式。
可以说,VOLT是一个原生的分布式的数据库, 其扩容、分区的均衡等,全都对于业务层_是透明的。
<
Original: https://www.cnblogs.com/VoltDB/p/16056138.html
Author: VoltActiveData
Title: VOLT ACTIVE DATA于传统数据库有哪些差别?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/562673/
转载文章受原作者版权保护。转载请注明原作者出处!