

postgresql高级应用之合并单元格
1.写在前面✍
继上一篇postgresql高级应用之行转列&汇总求和之后想更进一步做点儿复杂的(圖表暫且不論哈😂),当然作为報表,出現最多的無非就是合并單元格了,是的,我已經迫不及待啦😎~


2.思考
首先,我們的腦海中應該有一個對前端 table有一個大致的了解, 當然這對非前端的同學十分的不友好,如果您嘗試閲讀以下内容存在困難的話(前端 html、 javascript) 可就此打住哈。。。
enn…,讓我先稍稍解釋下前端 html 的表格格式吧😀
2.1 前端 html -> table 基本結構
先給出一個十分base的html demo.html
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>demo</title>
</head>
<body>
<!-- 這裏定義了兩個屬性 border:定義表格邊框 cellpadding:定義單元格大小 -->
<table border="3" cellpadding="8">
<thead>
<tr>
<th>表頭1</th><th>表頭2</th><th>表頭3</th>
</tr>
</thead>
<tbody>
<tr>
<td>第一行第1個</td><td>第一行第2個</td><td>第一行第3個</td>
</tr>
<tr>
<!-- 使用colspan屬性進行橫向合并,橫向被合并的單元格位置需要騰出來 -->
<!-- 以下橫向合并兩個單元格,所以第二個td標簽就不要寫了,否則會溢出哦~ -->
<td colspan="2">橫向合并了兩個單元格</td><td>第二行第3個</td>
</tr>
<tr>
<td>第三行第1個</td><td>第三行第2個</td><td>第三行第3個</td>
</tr>
<tr>
<!-- 使用rowspan屬性進行縱向合并,縱向合并的(跨越的)單元格位置需要騰出來 -->
<!-- 以下縱向合并三個個單元格(在本行最後一個標簽),所以下兩行的最後兩個td標簽就不要寫啦~,否則同樣會溢出哦~ -->
<td>第四行第1個</td><td>第四行第2個</td><td rowspan="3">縱向合并了三個單元格</td>
</tr>
<tr>
<td>第五行第1個</td><td>第五行第2個</td>
</tr>
<tr>
<td>第六行第1個</td><td>第六行第2個</td>
</tr>
</tbody>
</table>
</body>
</html>
瀏覽器渲染出來(使用瀏覽器打開html文件)的樣子是這樣的~

以上總結就是 colspan實現橫向合并單元格, rowspan實現縱向合并單元格~
呃嗯,既然我們知道了 html需要這兩個屬性值(也就是合并的行數或合并的列數),那麽就是要在sql中生成這兩個參數值然後提供給前端的同學使用哈,這是淺層意思,那麽深層意思是什麽呢???容我想想看。。。
- 對於橫向合并單元格 需要使用
case+when+then語句判斷是否需要橫向合并(重要的是要給出橫向合并的數值),這樣想是合理的,可能造成的困擾可能是這樣做會造成sql冗餘(當然也是不得已而爲之),當然本節就不再講橫向合并單元格啦 - 對於縱向合并單元格 step1.👉 如果使用
聚合+窗口函數來計算需要合并的相同的列數,可能造成的問題是生成的rowspan對於相同列來説數值是一樣的(如下圖),這樣不可以欸~

倒排序的窗口列
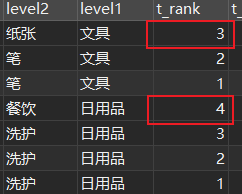
求總的列+倒排序的列


2.2表结构
drop table if EXISTS report2 ;
CREATE TABLE report2 (
"id" varchar(10) primary key,
"name" varchar(50),
"price" numeric,
"level2" varchar(50) ,
"level1" varchar(50)
);
2.3表字段注释
字段 注释 id 主键 name 商品名称 price 价格 level2 二级分类 level1 一级分类
2.4表数据
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0015', '洗发露', '36', '洗护', '日用品');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0008', '香皂', '17.5', '洗护', '日用品');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0007', '薯条', '7.5', '垃圾食品', '零食');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0009', '方便面', '3.5', '垃圾食品', '零食');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0004', '辣条', '5.6', '垃圾食品', '零食');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0006', 'iPhone X', '9600', '小电器', '电器');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0003', '手表', '1237.55', '小电器', '电器');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0012', '电视', '3299', '大电器', '电器');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0016', '洗衣机', '4999', '大电器', '电器');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0013', '围巾', '93', '配饰', '服装配饰');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0017', '特步凉鞋', '499', '鞋子', '服装配饰');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0001', 'NIKE新款鞋', '900', '鞋子', '服装配饰');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0002', '外套', '110.9', '上衣', '服装配饰');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0014', '作业本', '1', '纸张', '文具');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0005', '铅笔', '7', '笔', '文具');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0010', '水杯', '27', '餐饮', '日用品');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0011', '毛巾', '15', '洗护', '日用品');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0018', '绘图笔', '15', '笔', '文具');
INSERT INTO "report2"("id", "name", "price", "level2", "level1") VALUES ('0019', '汽水', '3.5', '其它', '零食');
3.🎉結果集最終求解
select
t1.*,
case when t_rank=t_count then t_count else null end as level1_row,
case when tu_rank=tu_count then tu_count else null end as level2_row
from
(
select
*,
row_number() over(PARTITION by level1 order by level1 asc) t_rank,
count(1) over (partition by level1) t_count,
row_number() over(PARTITION by level1,level2 order by level1,level2 asc) tu_rank,
count(1) over (partition by level1,level2) tu_count
from report2 order by level1
) t1 order by t1.level1,t_rank desc,t_count desc,tu_rank desc,tu_count desc;
_紅色_部分即為前端童鞋需要的合并數值哈🥰~

如果你能看懂以上問題及求解的 sql ,恭喜你又升級啦😂
總結下::對問題的 分析✨以及對問題求解的 思考🤔很重要嘛,當然還包含對 postgresql所提供工具的靈活使用 👉 總會產生意想不到的驚喜,哈哈😘~
Original: https://www.cnblogs.com/funnyzpc/p/14732172.html
Author: funnyZpC
Title: postgresql高级应用之合并单元格
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/562396/
转载文章受原作者版权保护。转载请注明原作者出处!