

Hadoop-MapReduce
一、MapReduce设计理念
- map—>映射
- reduce—>归纳
- mapreduce必须构建在hdfs之上的一种大数据离线计算框架
在线:实时数据处理
离线:数据处理时效性没有在线那么强,但是相对也需要很快得到结果
- mapreduce不会马上得到结果,他会有一定的延时(磁盘IO)
如果数据量小,使用mapreduce反而不合适
- 原始数据–>map(Key,Value)–>Reduce
- 分布式计算
将大的数据切分成多个小数据,交给更多的节点参与运算
- 计算向数据靠拢
将计算传递给有数据的节点上进行工作
二、mapReduce原理流程示意图
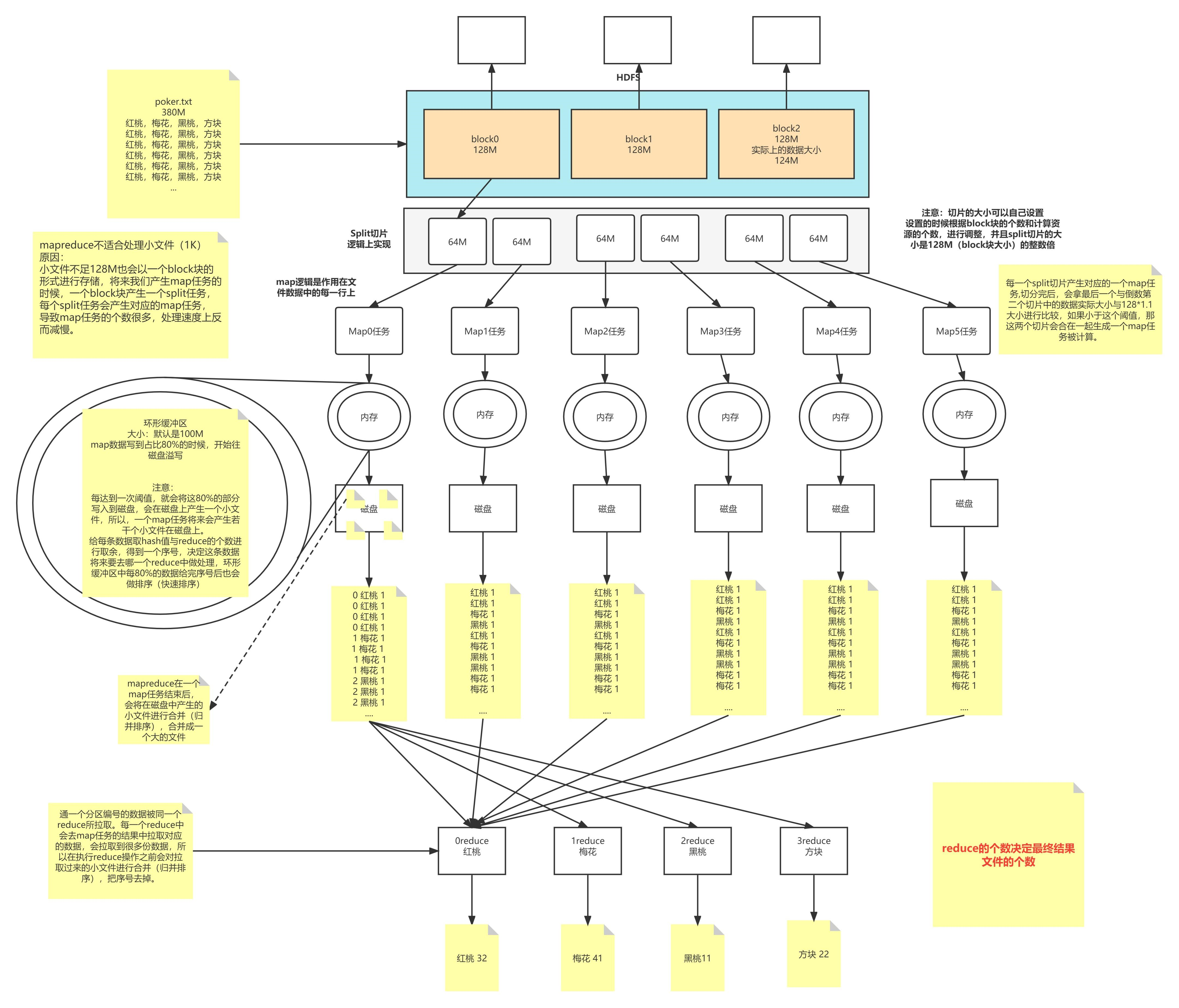

扑克牌问题:假设客户端发送了一个poker.txt的文件,大小是380M,切分成了三个块,此时我们有6个从节点可以存储这些块,如果一个块存入一个磁盘,那么还剩3个磁盘,这回造成资源的浪费,如果我们将block分片,一个block块分成两个切片,每台计算机都可以同时处理block信息,提高了资源利用率和效率。切片的大小可以自己设置,但必须是block块大小的倍数, mapreduce默认的切片大小是128M,正好与block块大小相等, 一个切片对应着一个map任务,如果最后一个切片的实际大小和倒数第二个切片的大小小于1281.1这个值,那么这两个切片会合在一起生成一个map任务。我们要明白的是切片是逻辑上的,作用在文件的每一行上。即使一个block块内的实际数据很小,也只会看block块来切片,不会看里面的实际数据。那么由此可以看出mapreduce不适合处理小文件,小文件不足128 M也会以一个block块 存储,这样大量的小文件会生成大量的map任务,处理速度反而会变慢。 map默认从所属切片读取数据,每次读取一行(默认读取器)到内存中* ,我们可以根据自己书写的分词逻辑(空格、逗号等进行分割),计算每个单词出现的次数,这时会产生(Map
新增
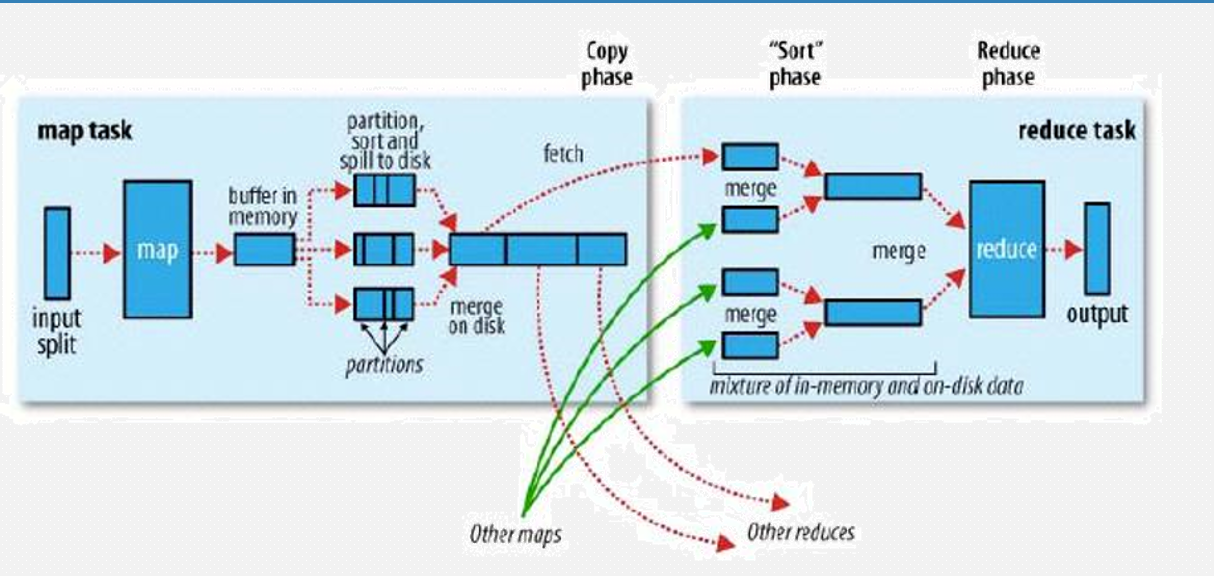
mapreduce详细过程
首先我们在hdfs上存储了一个文件的block块,一个block块默认产生一个切片,一个切片对应一个map任务,如果最
后一个切片的大小不超出默认切片大小的10%将会与倒数第二个切片合并产生一个map任务。当数据切片输入到map
的时候,数据会通过textFileInputformat类格式化数据成kv格式,k是偏移量,v是每一行的数据。kv格式的数据输入
到map经过处理后,将结果写入环形缓冲区,环形缓冲区的大小默认是100M,当数据写入占比80%后,开始往磁盘
溢写,每达到一次阈值就会将这80%的部分数据写入到磁盘,并在磁盘上产生一个小文件,同时者部分数据会进行分区
和排序,通过k的hash值与reduce的个数取余产生一个分区序号,然后对每一个分区里的数据按k进行快速排序。最后
这些小文件会按分区合并成一个大文件,同时用归并排序对合并后的每个分区数据数据进行排序。最后所有的map任务
产生的文件相同分区的数据会被同一个reduce所拉取,在执行reduce任务之前会对这些拉取的数据进行归并排序,并把
分区序号去掉。然后执行reduce任务,把相同k的数据合并到一起。
组合器Combiner
集群的带宽限制了mapreduce作业的数量,因此应该尽量避免map和reduce任务之间的数据传输,hadoop允许用户对map的输出数据进行处理,用户可自定义combiner函数(如同map函数和reduce函数一般),其逻辑一般和reduce函数一样,combiner的输入是map的输出,combiner的输出作为reduce的输入,很多情况下可以i直接将reduce函数作为conbiner函数来试用(job.setCombinerClass(FlowCountReducer.class))。
b. combiner属于优化方案,所以无法确定combiner函数会调用多少次,可以在环形缓存区溢出文件时调用combiner函数,也可以在溢出的小文件合并成大文件时调用combiner,但是要保证不管调用多少次,combiner函数都不影响最终的结果,所以不是所有处理逻辑都可以i使用combiner组件,有些逻辑如果试用了conbiner函数会改变最后reduce的输出结果(如求几个数的平均值,就不能先用conbiner求一次各个map输出结果的平均值,再求这些平均值的平均值,那样会导致结果的错误)。
c. combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量:
原先传给reduce的数据时a1 a1 a1 a1 a1
第一次combiner组合后变成a(1,1,1,1,1)
第二次combiner后传给reduce的数据变为a(5,5,6,7,23,…)
Original: https://www.cnblogs.com/bfy0221/p/16633601.html
Author: 伍点
Title: Hadoop-MapReduce
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/562060/
转载文章受原作者版权保护。转载请注明原作者出处!