

数据挖掘复习下
四、聚类(无监督学习,没有标签)
4.1概述
聚类分析:
寻找一组对象,使一组中的对象彼此相似(或相关)与其他组中的对象不同(或无关).。
聚类分析的应用:
生活中
生物学:物种的分类
信息检索:文档聚类
市场营销:帮市场分析人员发现不同的顾客群
社区规划:根据房子类型、价值、地理位置等对房子聚类
气象学:寻找大气和海洋的气候模式
万维网:对WEB日志的数据进行聚类,以发现相同的 用户访问模式
数据挖掘中
数据归约:作为数据回归、PCA、分类、相关分析等方法的预处理
基于组的预测:聚类并发现每个组的模式与特征
寻找k-近邻:在一个或几个聚类内局部搜索
离群点检测:找到不属于任何聚类的点
聚类分析的基本步骤:
1.特征选择:选择和任务相关的数据,最小信息冗余
2.邻近性度量:两个特征向量的相似性
3.聚类准则:通过代价函数或者规则来表达
4.聚类算法:聚类算法选择
5.结果的验证:验证数据集
6.结果的诠释:结合应用进行诠释
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:c81610aa-85cb-4953-8512-da8d5df59f08
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:06cb2561-a569-4cf4-a3a9-a80f187a44e5
聚类效果的判断标准:剪影 Silhouette(一种简洁的图形表示,表示每个数据点在其簇内相对于其他簇的情况)


4.2K-Means
步骤:
1.确定 K 的值。
2.随机生成 K 个聚类中心。
3.每个数据点都被分配到其最近的中心。
4.使用每个簇的平均值更新每个中心。
5.返回到3,直到没有新的分配点。
6.返回K个中心点。
优点:
简单,适用于规则不相交的簇。
收敛速度相对较快。
相对有效,算法复杂度: O(t·k·n),t: 迭代次数; k: 中心点的个数; n: 样本点的数目。
缺点:
需要提前决定K的值。
可能会收敛到局部最优。
对噪声点和奇异点很敏感。
不适合的聚类 :非凸的形状
局限性:
K-means 在聚类有大小,密度,不同时或者非球形时会存在问题 。
K-means 当数据包含离群值时会出现问题。
初始质心的位置不同也会产生不同的结果。
解决初始质心问题:
多次运行。
采样并使用层次聚类法确定初始质心。
选择超过 k 个的初始质心然后从中挑选初始质心。
后处理:
分裂 ‘稀松’ 的簇, 如有较高 SSE的簇。
合并 ‘紧密’ 的和有较低SSE的簇。
生成更多的簇,然后执行层次聚类 。
二分K-means。
二分 K-means 算法:

4.3层次聚类
两种主要类型:
凝聚(自下而上法):
以点作为各个簇开始,每一步, 合并最近的两个簇直到只剩一个(or k clusters) 簇。
分裂(自上而下法):
从一个包括所有点的簇开始,每一步, 分裂一个簇直到每个簇只包含一个点 (or there are k clusters)。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:3d8c9f28-8980-4358-913e-bfbc1ce6b22f
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:8eff269f-09fc-451e-a16c-07080a958cd5
簇间的邻近(相似)性:
MIN(单链),MA(全链),Group Average(组平均)。
簇间的邻近(相似)性MIN 或 Single Link:
对于不同的簇,两个簇的相似性基于两个最相似的点(最接近),由一对点来决定。
簇间的邻近(相似)性MAX 或 Complete Linkage:
两个簇的相似性基于两个最相似(最遥远)的点在不同的簇,取决于在两个簇中所有的点对。
簇间的邻近(相似)性Group Average:
两个簇的邻近度是两个簇点与点之间的两两距离平均。
MIN可以处理非椭圆形 但对噪声和离群点敏感。
MAX不受孤立点和噪声影响,但倾向打破大的簇。
(MIN)最小距离的凝聚层次聚类算法流程:
(1) 将每个对象看作一类,计算两两之间的最小距离;
(2) 将距离最小的两个类合并成一个新类;
(3) 重新计算新类与所有类之间的距离;
(4) 复(2)、(3),直到所有类最后合并成一类。
ps:其他的凝聚层次聚类算法大致相同。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:391b1ff0-0224-4d39-960b-c65ffa2f0f7d
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:66efa80d-c5dc-4aa0-b5da-4f2da1fddc93
一旦作出决定合并两个簇,它不能被撤消;
没有目标函数直接最小化;
不同的方案存在一个或多个以下问题:;
实例:
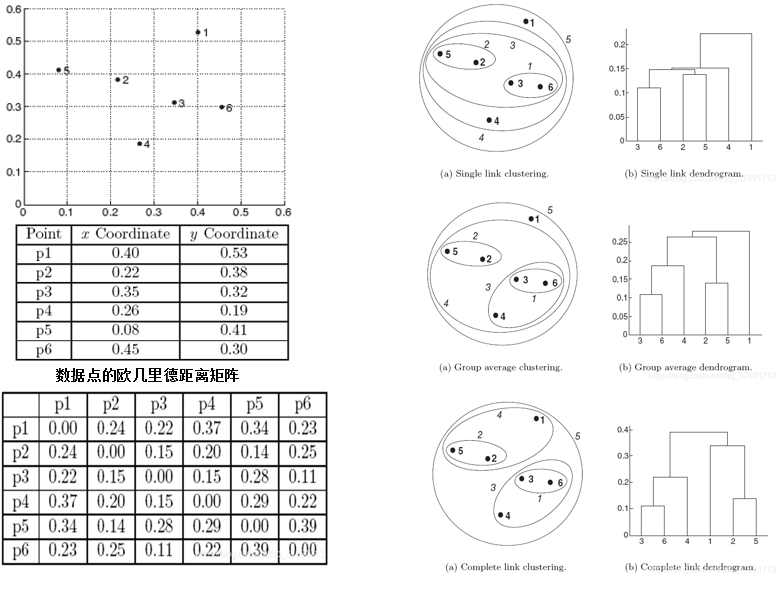
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:a1e00a80-c288-4700-969f-17507981be10
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:fc5a0fef-cff6-4677-992b-000af457c7ec
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:4f5bb579-5e98-4eab-afa3-619a6cf86706
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:c293b873-a4d8-491f-8472-ba1ef609f98f
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:9a4180b7-84f6-4958-b72e-1a9c834b28bc
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:316a0a80-9256-4771-9f4d-d6edec7ee80d
d({3,6},{2,5})=min⁡(d(3,2),d(6,2),d(3,5),d(6,5))
=min⁡(0.15,0.25,0.28,0.39)
=0.15
d({3,6},{2,5})=max⁡(d(3,2),d(6,2),d(3,5),d(6,5))
=max⁡(0.15,0.25,0.28,0.39)
=0.39
我们考虑两个簇Ci和Cj,它们分别具有mi和mj的大小。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:de1af214-f282-43cb-87ed-601b0aed21de
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:e1ba20cf-3bba-4ab8-9705-16cd41c9dabe
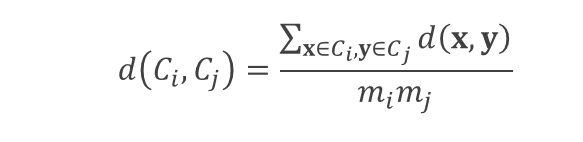
例子:d({3,6,4},{2,5})=(0.15+0.28+ 0.25+0.39+0.20+0.29)/(3×2)= 0.26
4.4基于密度的方法:DBSCAN(Density based Spatial Clustering of Application with noise)
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:1fbd8413-510f-4e78-99aa-51495ab891ab
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:78b014c4-cc98-412d-9b25-d98a7d63659f
主要思想:
寻找被低密度区域分离的高密度区域。
只要临近区域的密度(单位大小上对象或数据点的数目) 超过某个阈值,就继续聚类。
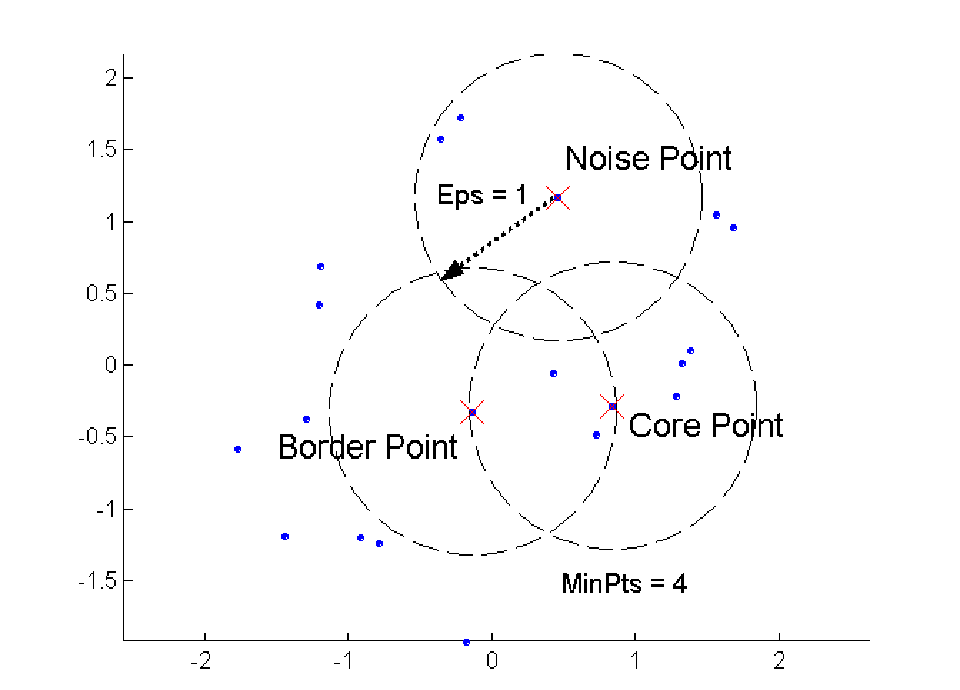
密度 = 指定半径(Eps)内的点的数量 。
一个点是一个核心点,如果在指定半径(Eps) 内有超过一个指定的点数 (MinPts),那这些都是在簇内部的点。
在 指定半径(Eps)内,一个边界点有少于 MinPts 的点数, 但它落在核心点的邻域内。
噪声点 既非核心点也非边界点的任意点。
例子如下:
簇内点的大概形式:
步骤:
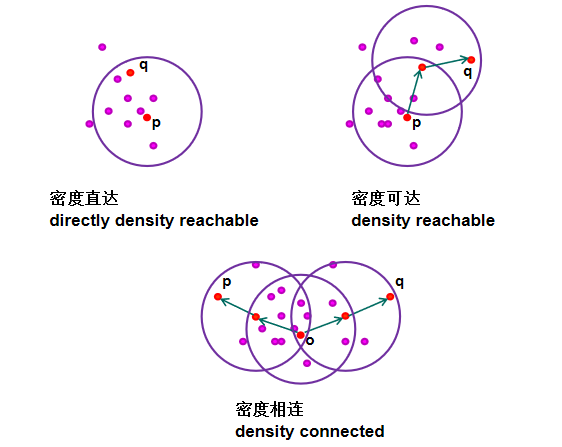
从一个随机选择的点P开始.。
如果P是一个核心点,则通过逐步将密度可达的所有点添加到当前点集来构建簇。
噪声点被丢弃。
优点:抗噪,能处理不同形状不同大小的簇,无需预先设置K值。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:8560342e-ac16-4b7a-9649-50b39e495349
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:17213ee2-1b31-4e80-bcf2-9a261c05dd1a
算法示例:对于下表所示二维平面上的数据集,取Eps=3,MinPts=3 来演示,DBSCAN算法的聚类过程(使用Mahattan距离)。
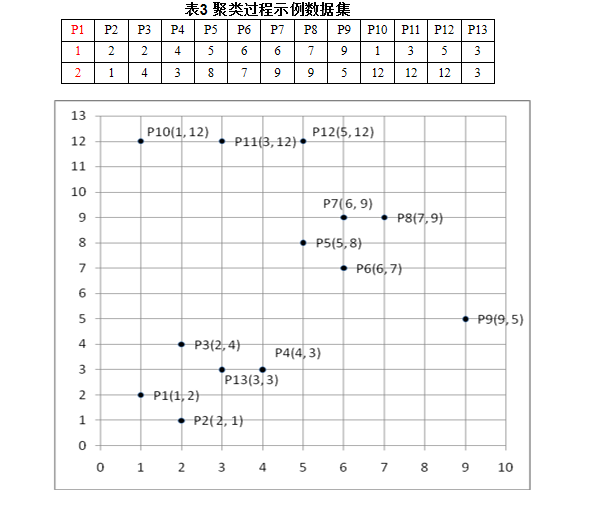
解答:
(1) 随机选择一个点,如P1(1,2),其Eps邻域中包含:{P1,P2,P3,P13},P1是核心点,其邻域中的点构成簇1的一部分,依次检 查P2,P3,P13的Eps 邻域,进行扩展,将点P4并入;
(2) 检查点P5,其Eps邻域中包含:{P5,P6,P7,P8},P5是核心点,其邻域中的点构成簇2的一部分,依次检查P6,P7,P8的Eps邻域,进行扩展,每个点都是核心点,不能扩展;
(3) 检查点P9,其Eps邻域中包含: {P9},P9为噪声点或边界点;
(4) 检查点P10,其Eps邻域中包含: {P10,P11},P10为噪声点或边界点;检查P11,其Eps邻域中包含:{P10,P11,P12},P11为核心点,其邻域中的点构成簇3的一部分;进一 步检查,P10、P12为边界点。
(5)所有点标记完毕,P9没有落在任何核心点的邻域内,为噪声点。
最终识别出三个簇,P9为噪声点。
簇1包含{P1,P2,P3,P4,P13},均为核心点;
簇2包含{P5,P6,P7,P8 },其全部点均为核心点;
簇3包含{P10,P11,P12},P10、P12为边界点,P11为核心点;
如果MinPts=4,
则簇3中的点均被识别成噪声点。
确定 EPS 和 MinPts:
思路:对于簇中的点,它们的第k个近邻,有大致相同的距离
噪声点的第k个近邻则在更远的距离上。所以, 图按每个点到它们的第k个最近邻的距离进行排序。
五、关联分析(简)
5.1概述
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:c0a80caa-a386-40ff-a5bd-fdb9513a4be8
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:7745f087-0b61-4a08-94e0-1808fc1ecc08

5.1.2频繁项集(Frequent Itemset)
项集(Itemset):包含0个或多个项的集合。
例子: {Milk, Bread, Diaper}
k-项集:如果一个项集包含k个项
支持度计数(Support count ):包含特定项集的事务个数。
例如: (Support count )({Milk, Bread,Diaper}) = 2
支持度(Support):包含项集的事务数与总事务数的比值
例如: s({Milk, Bread, Diaper}) = 2/5
频繁项集(Frequent Itemset):满足最小支持度阈值( minsup )的所有项集
5.1.2关联规则(Association Rule)
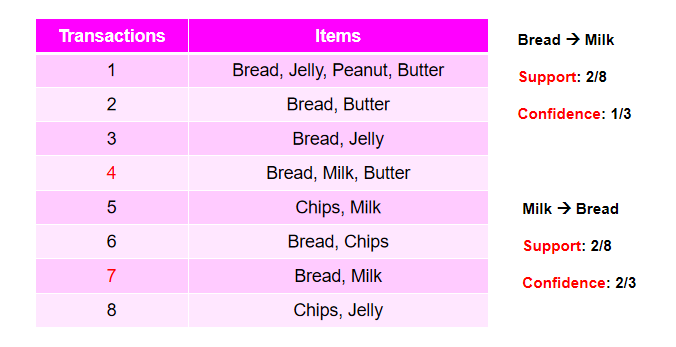
关联规则:关联规则是形如 X-> Y的蕴含表达式, 其中 X 和 Y 是不相交的项集。
例子:{Milk, Diaper} -> {Beer}
关联规则的强度:
支持度 Support (s):确定项集的频繁程度.
支持(Support)度量规则在数据集中出现的频率.
置信度 Confidence (c):确定Y在包含X的事务中出现的频繁程度.
置信度 (Confidence) 衡量规则的力量。
关联规则X ->Y的支持度是包含X和Y的事务的百分比。
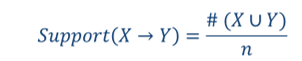
关联规则X ->Y的置信度是包含{X,Y}的事务数与包含X的事务数之比。
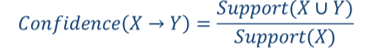
条件概率:P(Y|X)。
例子:

5.2Apriori 算法
主要思想:
频繁项集的子集必须是频繁的。
{Milk, Bread, Coke} 是频繁的 -> {Milk, Coke} 是频繁的。
任何不频繁项集的超集都不能是频繁的。
{Battery} 是不频繁的 -> {Milk, Battery}是不频繁的。
步骤:
1.生成特定大小的项集 (通常是1-项集)。
2.扫描数据库一次,看看哪一个是频繁的。
3.使用频繁项集来产生候选项集(size=size+1)。返回到2.
4.迭代产生基数从1~k的频繁项集 。
5.可避免产生不是频繁项集的候选者。
6.需要对数据库进行多次扫描。
7.高效的索引技术,如哈希函数和位图可能会有所帮助。
特点:
它是一个逐层算法。即从频繁1-项集到最长的频繁项集,它每次遍历项集格中的一层。
它使用产生-测试策略来发现频繁项集。在每次迭代,新的候选项集由前一次迭代发现的频繁项集产生,
然后对每个候选的支持度进行计数,并与最小支持度阈值进行比较。
该算法需要的总迭代次数是kmax+1,其中kmax是频繁项集的最大长度
实例:

5.3FP增长算法(FP-growth Algorithm)
FP树是一种输入数据的压缩表示,它通过逐个读入事务,并把每个事务映射到FP树中的一条路径来构造。
构造FP树:
(1)扫描一次数据集,确定每个项的支持度计数。丢弃非频繁项,而将频繁项按照支持度的递减排序
(2)算法第二次扫描数据集,构建FP树。读入第一个事务{a,b}之后,创建标记为a和b的结点。然后形成null->a->b路径,对该事务编码。该路径上的所有结点的频度计数为1.
(3)读入第二个事务{b,c,d}之后,为项b,c和d创建新的结点集。然后,连接结点null->b->c->d,形成一条代表该事务的路径。该路径上的每个结点的频度计数也等于1.尽管前两个事务具有一个共同项b,但是它们的路径不相交,因为这两个事务没有共同的前缀。
六、集成学习
6.1 概述
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:496fdcc5-5a06-477c-967a-217788271441
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:cdc17324-8db6-42a3-b2c9-08c757d9f993
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:1ad1b033-663d-4677-a76e-2ec8b39150a9
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:7485f36d-cec5-4dc7-bf89-4544f7698507
什么是集成学习?
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:28ab2535-be8a-47ed-99e9-8480dec90af9
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:ac3632e9-7251-4b3e-8fa6-7b4b2dc428ff
两种主要的集成学习:平行(Bagging),顺序(Boosting)
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:baaf6870-1036-4dbd-a783-50aab199ce7f
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:b92a344f-fc3a-45e4-a6fa-11904e87a16e
1.平均 Averaging。
2.投票 Voting:
多数表决 Majority Voting:随机森林 Random Forest;
加权表决 Weighted Majority Voting:AdaBoost。
3.学习合成器Combiners:
通用合成器General Combiner:堆叠Stacking;
分段合成器Piecewise Combiner:区域推进RegionBoost。
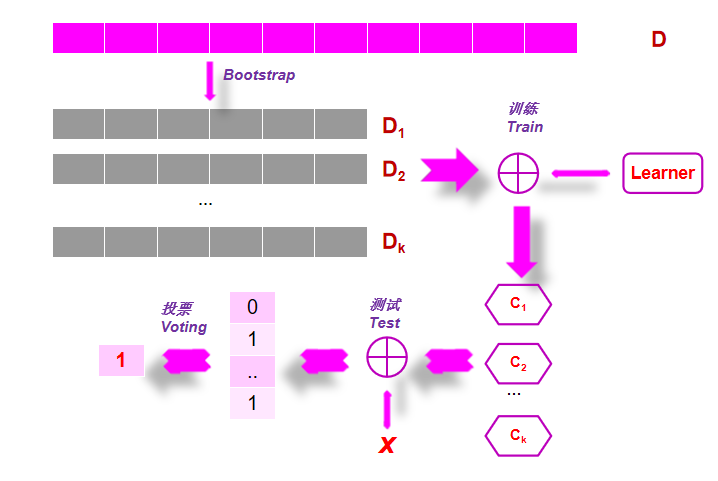
6.2引导聚集算法-Bagging (Bootstrap Aggregating)

6.3随机森林
主要特性:
1.生成完全不同的树:
训练集生成:随机 bootstrap 样本;
属性结点:随机变量的子集。
2.属性(变量)的数量:
平方根 (K);
K: 总的变量个数;
可以极大地加快建树过程。
3.树的数目:500 或者更多
4.自我测试:
大约有三分之一的原始数据被遗漏了;
Out of Bag (OOB);
相似于交叉验证(Cross-Validation)。
优点:
1.所有数据都可以用来训练,不需要留下一些数据进行测试,无需进行常规交叉验证。
2.整个t随机森林RF的性能,取决于它是否在OOB中。
3.高水平的预测精度:需要调整的参数很少,适用于分类和回归。
4.过训练(过拟合)。
5.不需要做特征选择。
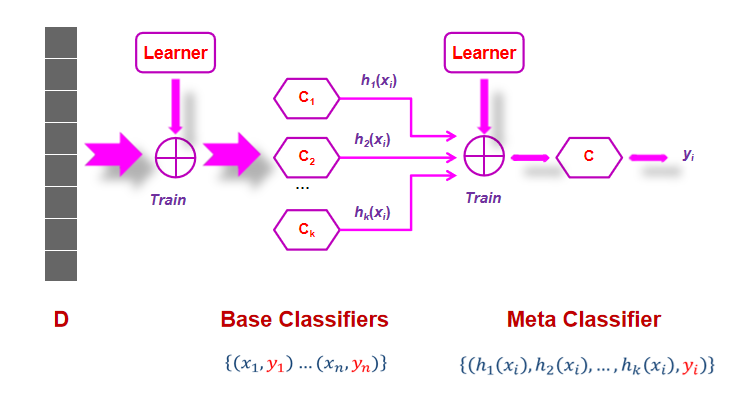
6.4Stacking

6.5Boosting
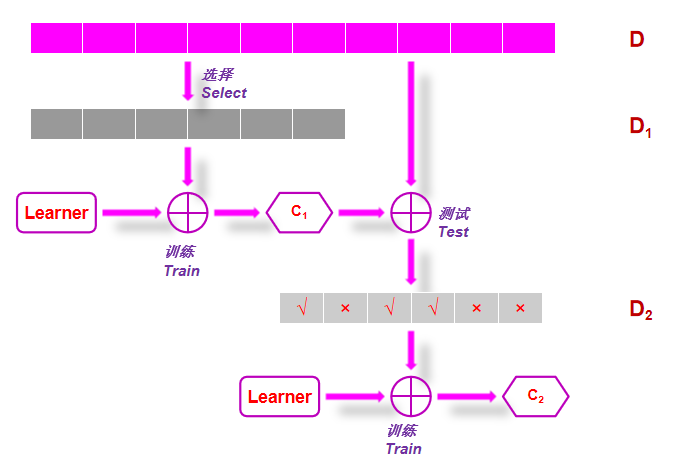
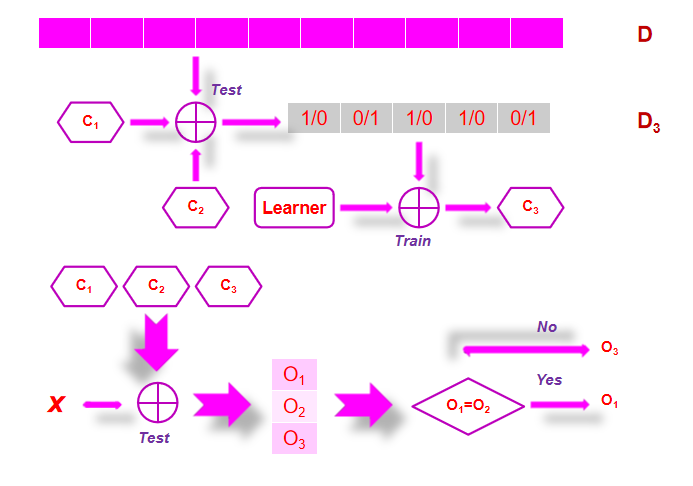

特点:
在Boosting中, 分类器是按顺序生成的。
重点放在信息最丰富的数据点上。
训练样本是有权重的。
输出通过加权表决组合。
可以创建任意强分类器 。
基础学习者可以是任意弱的 。
6.6AdaBoost

Original: https://blog.csdn.net/weixin_45613955/article/details/112055391
Author: ms scholar
Title: 数据挖掘复习下
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/561662/
转载文章受原作者版权保护。转载请注明原作者出处!