

1、算法简介:
2014年6⽉,Alex Rodriguez和Alessandro Laio在Science上发表了⼀篇名《Clustering by fast search and find of density peaks》的文章,提供了⼀种简洁而优美的聚类算法,是⼀种基于密度的聚类方法,可以识别各种形状的类簇,并且参数很容易确定。它克服了DBSCAN中不同类的密度差别大、邻域范围难以设定的问题,鲁棒性强。
2、算法对于数据集的假设:
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:4d974b0e-9f12-4a5e-a9e4-b0e2b4de9768
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:f602da87-c920-4ba5-a537-5608c6e7d90d
1.数据集在空间分布并不均匀,数据中局部高密度点被一些局部低密度点包围
2.数据集中局部高密度点之间的相对距离较大
3、算法相关公式:
1)密度计算:
 其中,密度计算有两种计算方式:1.传统的欧式距离计算距离,将距离小于点的数量直接作为密度,2.计算欧式距离并计算高斯函数值,将所有点值的和作为密度。
其中,密度计算有两种计算方式:1.传统的欧式距离计算距离,将距离小于点的数量直接作为密度,2.计算欧式距离并计算高斯函数值,将所有点值的和作为密度。
2)局部高密度点距离计算:
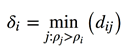 ,当dij是密度最高的点时:。
,当dij是密度最高的点时:。
4、算法过程
1)计算数据密度
根据设定的截断距离
,计算每个数据点的局部密度
2)局部高密度点距离
计算每个点到高于自身局部密度值点的最小距离。得到
3)根据密度与距离估计中心点
对每⼀个点,绘制出局部密度
与高局部密度点距离的散点图
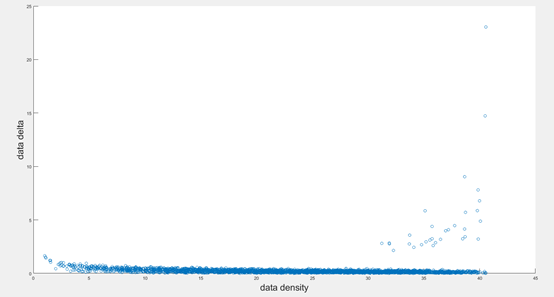
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:af071b16-0a4a-4ffc-b352-da3df64cbad0
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:c2e36178-c99a-4df2-9f73-5a63fb450023
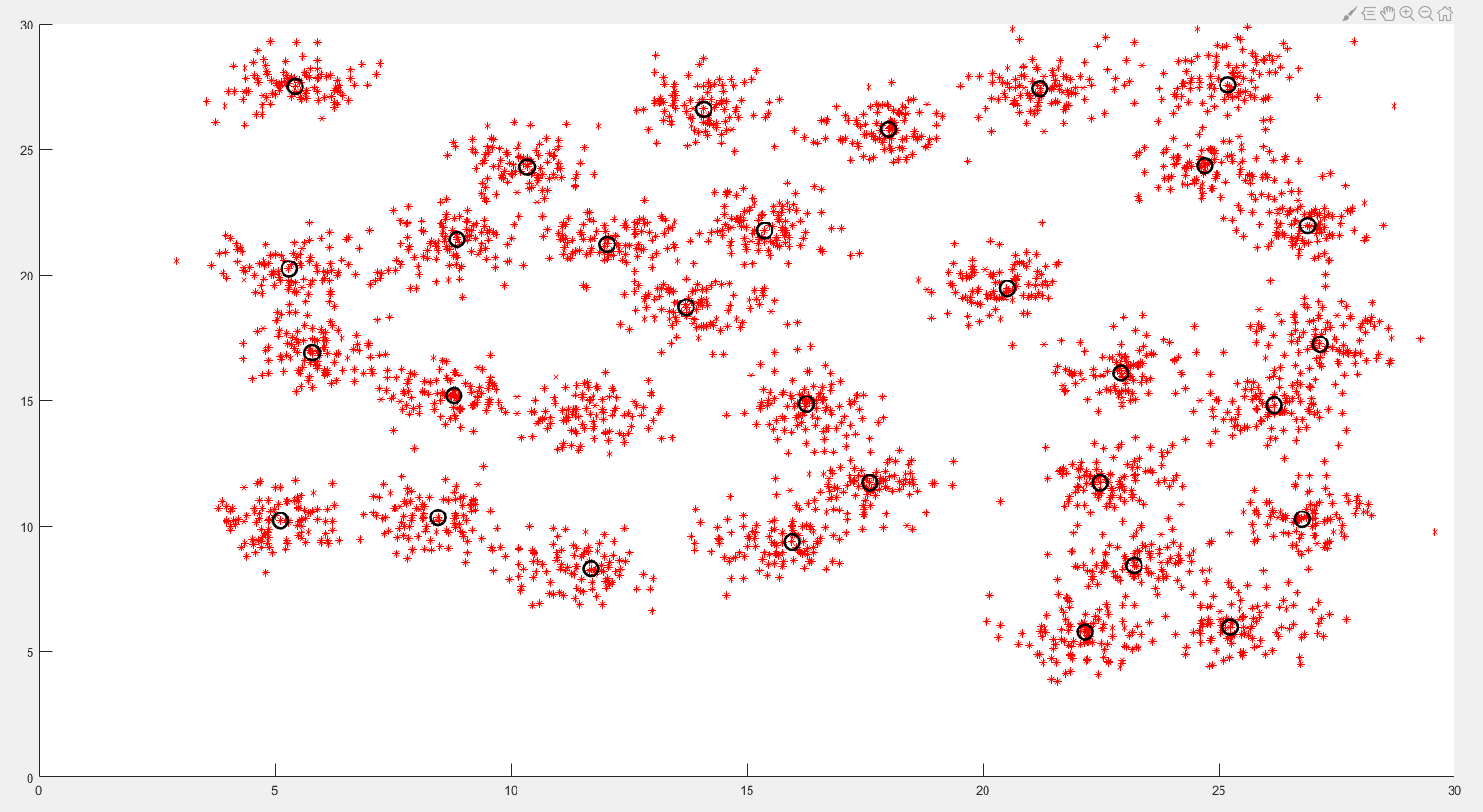
4)划分剩余数据点(聚类过程)
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:2a78f268-7806-4da8-b3c2-06edfceda1c7
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:d886695c-6ea2-452d-918e-45967137b462
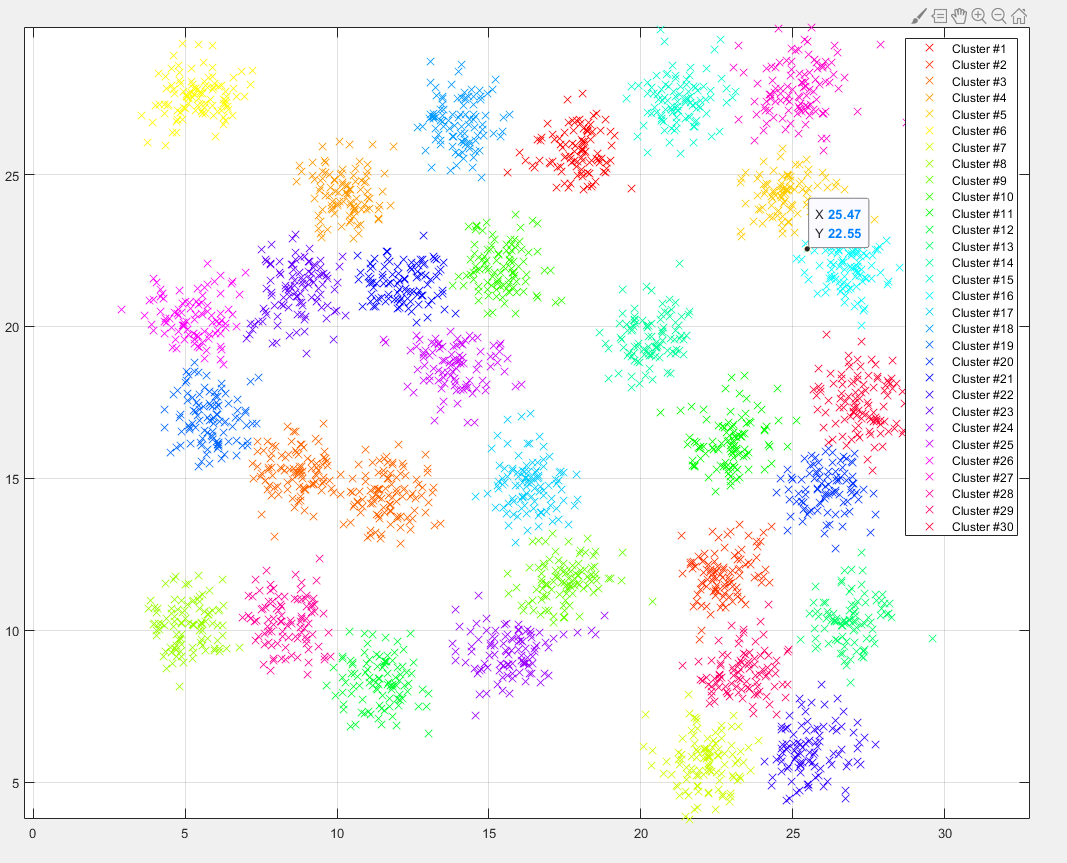
代码实现:
1)密度计算
%% 密度计算函数
function data_density=cal_density(data,cut_dist)
data_len=size(data,1);
data_density=zeros(1,data_len);
for idata_len=1:data_len
temp_dist=pdist2(data,data(idata_len,:));
data_density(idata_len)=sum(exp(-(temp_dist./cut_dist).^2));
end
end
2)距离计算
%% 计算delta
function data_delta=cal_delta(data,data_density)
data_len=size(data,1);
data_delta=zeros(1,data_len);
for idata_len=1:data_len
index=data_density>data_density(idata_len);
if sum(index)~=0
data_delta(idata_len)=min(pdist2(data(idata_len,:),data(index,:)));
else
data_delta(idata_len)=max(pdist2(data(idata_len,:),data));
end
end
end
3)聚类中心点寻找
%% 寻找聚类中心点
function [center,center_index]=find_center(data,data_delta,data_density,cut_dist)
R=data_density.*data_delta;
[sort_R,R_index]=sort(R,"descend");
gama=abs(sort_R(1:end-1)-sort_R(2:end));
[sort_gama,gama_idnex]=sort(gama,"descend");
gmeans=mean(sort_gama(2:end));
%寻找疑似聚类中心点
temp_center=data(R_index(gama>gmeans),:);
temp_center_index=R_index(gama>gmeans);
%进一步筛选中心点
temp_center_dist=pdist2(temp_center,temp_center);
temp_center_len=size(temp_center,1);
center=[];
center_index=[];
%判断中心点之间距离是否小于2倍截断距离并中心点去重
for icenter_len=1:temp_center_len
temp_index=find(temp_center_dist(icenter_len,:)<2*cut_dist); [~,max_density_index]="max(data_density(temp_center_index(temp_index)));" if sum(center_index="=temp_center_index(temp_index(max_density_index)))==0" center="[center;temp_center(temp_index(max_density_index),:)];" center_index="[center_index,temp_center_index(temp_index(max_density_index))];" end % center(icenter_len,:)="temp_center(temp_index(max_density_index),:);" end< code></2*cut_dist);>
4)聚类过程
%% 聚类算法
function cluster=Clustering(data,center,center_index,data_density)
data_len=size(data,1);
data_dist=pdist2(data,data);
cluster=zeros(1,data_len);
% 标记中心点序号
for i=1:size(center_index,2)
cluster(center_index(i))=i;
end
% 对数据密度进行降序排序
[sort_density,sort_index]=sort(data_density,"descend");
for idata_len=1:data_len
%判断当前数据点是否被分类
if cluster(sort_index(idata_len))==0
near=sort_index(idata_len);
while 1
near_density=find(data_density>data_density(near));
near_dist=data_dist(near,near_density);
[~,min_index]=min(near_dist);
if cluster(near_density(min_index))
cluster(sort_index(idata_len))=cluster(near_density(min_index));
break;
else
near=near_density(min_index);
end
end
end
end
end
完整代码:峰值聚类算法(matlab)_matlab密度峰值聚类算法-机器学习文档类资源-CSDN下载
Original: https://blog.csdn.net/qq_30977037/article/details/112160360
Author: qq_30977037
Title: 密度峰值聚类介绍与matlab实现
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/561366/
转载文章受原作者版权保护。转载请注明原作者出处!