

文章目录
*
– 模糊集的基本概念
–
+ 模糊集定义
+ 隶属度函数
+ 模糊集表示方法
+ 模糊集运算
+ 模糊集的特性
+ 模糊与概率的区别
+ 模糊关系(模糊矩阵)
+ 模糊关系合成运算
+ 模糊变换
+ 模糊逻辑
+ 模糊推理
– 数据挖掘中的模糊方法
–
+ 计算流程
+ 模糊C均值聚类
* 模糊C-均值聚类算法 步骤
模糊集的基本概念
模糊集定义

 隶属度属于模糊评价函数里的概念:模糊综合评价是对受多种因素影响的事物做出全面评价的一种十分有效的多因素决策方法,其特点是评价结果不是绝对地肯定或否定,而是以一个模糊集合来表示。 X是论域;A是μ A μ_A μA 确定的子集(模糊集);μ A μ_A μA 代表x属于A的程度,是隶属函数
隶属度属于模糊评价函数里的概念:模糊综合评价是对受多种因素影响的事物做出全面评价的一种十分有效的多因素决策方法,其特点是评价结果不是绝对地肯定或否定,而是以一个模糊集合来表示。 X是论域;A是μ A μ_A μA 确定的子集(模糊集);μ A μ_A μA 代表x属于A的程度,是隶属函数
; 隶属度函数
元素x在论域U中,有A(x)∈(0,1),则称A为U上的模糊集,A(x)为称为x对A的隶属度。当x变化时,A(x)就是一个函数,称为A的隶属函数。A(x)越接近1,表示x属于A的程度越高。 这条不易理解

模糊集表示方法


[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:365295af-ddbc-4e4b-9e88-de29b91c866e
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:f6919858-bf57-4547-a8a9-625bb3e42880
; 模糊集运算

[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:d3dea7a5-f8ce-4d67-a408-95fe8b337a3e
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:9396400b-de96-48ef-9a07-756155032be0
模糊集的特性


; 模糊与概率的区别

模糊关系(模糊矩阵)

[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:f0c455af-f938-48ca-b5e6-e2f0b494fba7
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:095303e5-84f8-43ca-9d4c-725b78d80664
; 模糊关系合成运算

模糊关系合成运算的MATLAB程序
function [R]=fuzzymm(A,B)
%模糊矩阵合成运算的Matlab实现 R = AxB;
%运算规则,先"取小后取大"
%输入必须为二阶矩阵A为m行n列, B为n行p列;
[m,n]=size(A);[q,p]=size(B);%获得输入矩阵的维度信息
if n~=q
disp('第一个矩阵的列数和第二个矩阵的行数不相同!');
else
R=zeros(m,p);%初始化矩阵
for k =1:m
for j=1:p
temp=[];
for i =1:n
Min = min(A(k,i),B(i,j)); %求出第i对的最小值
temp=[temp Min]; %将求出的最小值加入的数组中
end
R(k,j)=max(temp);
end
end
end
end

模糊变换


; 模糊逻辑

[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:cce29a69-33d9-49f3-872b-44dcae4e6d4c
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:9879a907-7a32-4964-8a61-74b18ba5e4cf
 含有多个前提条件的称为多维模糊规则,可以表示为:如果 u_1是 _A_1,且 _u_2是 _A_2,…,且 _um_是 _Am,则 v_是 _B。
含有多个前提条件的称为多维模糊规则,可以表示为:如果 u_1是 _A_1,且 _u_2是 _A_2,…,且 _um_是 _Am,则 v_是 _B。
模糊推理


; 数据挖掘中的模糊方法
计算流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eLJfzQ2L-1657852241523)(https://s2.loli.net/2022/07/15/V1yZNEi4Yuew7Jg.png)]
模糊C均值聚类
目标函数中c表示c类,n表示样本的数量, m为加权指数,一般取1.5-3.5 。u表示隶属函数,d用于计算样本点与中心点之间的欧几里德距离,通过这个公式,我们就可以计算每个样本点属于哪一类。对于目标函数的求解,我们可以使用拉格朗日乘子法进行求解,对所有输入参量求导,使式达到最小的必要条件为:u…c…
模糊C均值聚类算法是一个简单的迭代过程。在批处理方式运行时,FCM用下列步骤确定聚类中心ci和隶属矩阵U[1]:…用值在0,1间的随机数初始化隶属矩阵U,计算c个聚类中心,计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数值的改变量小于某个阀值,则算法停止。
实验中我们使用的是iris数据集,这个数据集…通过算法我们的出了聚类的结果,0,1,2就表示聚类的类别,我们可以看到,0类都标记正确,1类有13个错误标记,2类有3个标记错误。因此我们得到最终的聚类准确率为89.33%,右图是横纵坐标分别为特征2和特征3时对应的聚类结果。
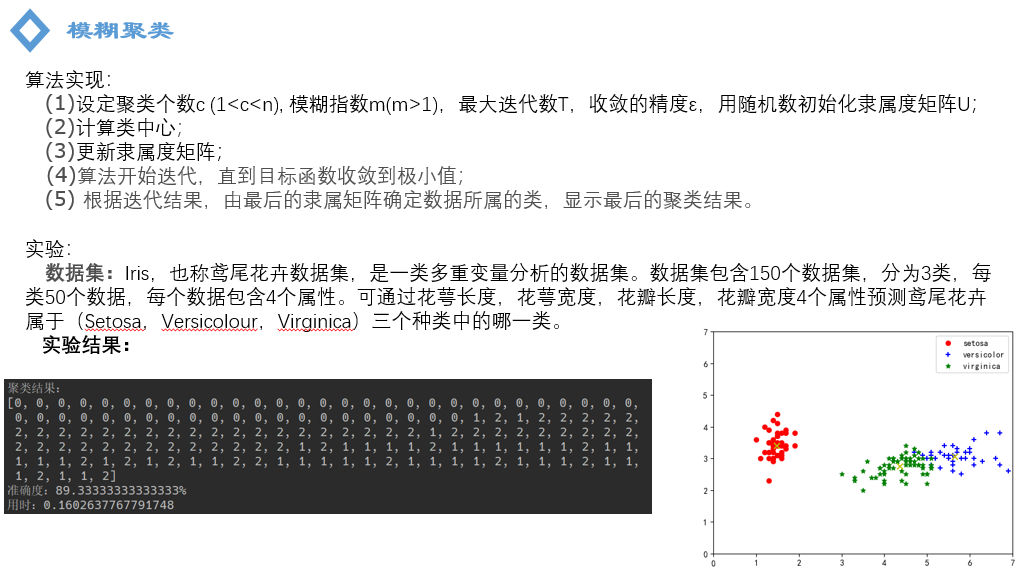
; 模糊C-均值聚类算法 步骤
https://blog.csdn.net/weixin_39788703/article/details/111370295
这个缺少最关键的更新迭代那一步。更新矩阵U那一步。
https://blog.csdn.net/vendetta_gg/article/details/106671089这个就是隶属度矩阵的推导过程。
- 导入数据并转换为矩阵;样本综述为n个;
X = [ x 1 x 2 ⋮ x n ] = [ x 11 x 12 … x 1 p x 21 x 22 … x 2 p ⋮ ⋮ … ⋮ x n 1 x n 2 ⋯ x n p ] X=\left[\begin{array}{c} x_{1} \ x_{2} \ \vdots \ x_{n} \end{array}\right]=\left[\begin{array}{cccc} x_{11} & x_{12} & \ldots & x_{1 p} \ x_{21} & x_{22} & \ldots & x_{2 p} \ \vdots & \vdots & \ldots & \vdots \ x_{n 1} & x_{n 2} & \cdots & x_{n p} \end{array}\right]X =⎣⎡x 1 x 2 ⋮x n ⎦⎤=⎣⎡x 11 x 21 ⋮x n 1 x 12 x 22 ⋮x n 2 ………⋯x 1 p x 2 p ⋮x n p ⎦⎤
X是由n个样品的P个变量观测值构成的矩阵。 - 设定聚类个数c和加权指数m,最大迭代数和收敛精度; 聚类个数2 ≤ c ≤ n 2≤c≤n 2 ≤c ≤n;
- 用随机数初始化隶属度矩阵μ i j μ_{ij}μij ;
- 计算聚类中心; V = ( v 1 , v 2 , . . . v c ) V=(v_1,v_2,…v_c)V =(v 1 ,v 2 ,…v c )为c个类的聚类中心,其中v i = ( v i 1 , v i 2 , . . . v i p , ) v_i=(v_{i1},v_{i2},…v_{ip},)v i =(v i 1 ,v i 2 ,…v i p ,)。
v i = ∑ j = 1 n x j μ i j m ∑ j = 1 n μ i j m ( i = 1 , 2 , . . . , c ) {v_i} = \frac{{\sum\nolimits_{j = 1}^n {{x_j}{\mu {ij}}^m} }}{{\sum\nolimits{j = 1}^n {{\mu {ij}}^m} }} (i=1,2,…,c)v i =∑j =1 n μij m ∑j =1 n x j μij m (i =1 ,2 ,…,c )
更新隶属度矩阵;
u i j = [ ∑ k = 1 c ( d i j d k j ) 2 m − 1 ] − 1 ( i = 1 , 2 , . . . c ; j = 1 , 2 , . . . n ) u{i j}=\left[\sum_{k=1}^{c}\left(\frac{d_{i j}}{d_{k j}}\right)^{\frac{2}{m-1}}\right]^{-1} (i=1,2,…c; j=1,2,…n)u ij =[k =1 ∑c (d kj d ij )m −1 2 ]−1 (i =1 ,2 ,…c ;j =1 ,2 ,…n ) - 迭代算法,直至收敛; 目标函为:
( m i n ) J m ( U , V ) = ∑ j = 1 n ∑ i = 1 c u i j m d i j 2 ( x j , v i ) d i j ( x j , v i ) = ∥ v i − x j ∥ (\mathrm{min}) J_{m}(U, V)=\sum_{j=1}^{n} \sum_{i=1}^{c} u_{i j}^{m} d_{i j}^{2}\left(x_{j}, v_{i}\right) \ d_{i j}\left(x_{j}, v_{i}\right)=\left\|v_{i}-x_{j}\right\|(min )J m (U ,V )=j =1 ∑n i =1 ∑c u ij m d ij 2 (x j ,v i )d ij (x j ,v i )=∥v i −x j ∥ - 根据迭代结果,由最后的隶属度矩阵确定所属的类,显示聚类结果。
FCM算法用隶属度确定每个样本属于某个聚类的程度。它与K-means算法和中心点算法等相比,计算量可大大减少,因为它省去了多重迭代的反复计算过程,效率将大大提高。同时,模糊聚类分析可根据数据库中的相关数据计算形成模糊相似矩阵,形成相似矩阵之后,直接对相似矩阵进行处理即可,无需多次反复扫描数据库。
根据实验要求动态设定m值,以满足不同类型数据挖掘任务的需要,适于高纬度数据的处理,具有较好的伸缩性,便于找出异常点。但m值是根据经验或者实验得来的,故具有不确定性,可能影响实验结果;并且,优于梯度法的搜索方向总是沿着能量减小的方向,使得算法存在易陷入局部极小值和对初始化敏感的缺点。为了克服上述缺点,可在FCM算法中引入寻优法,以摆脱FCM聚类运算时可能陷入的局部极小点,优化聚类效果。
%%
% 模糊C均值聚类的方法实现
% # 导入数据集
clc
clear
irisInput = readtable('\\tsclient\d\0-work\学习\模糊方法\Iris数据集\iris.txt'); % 导入.txt文件
iris= irisInput(:,2:6); %取数据中的一部分
% 处理数据集 ;
x = table2array( iris(1:150,1) ); %将表格转换成阵列
classf = table2cell( iris(1:150,5) ); %将表格转换成字符串数组
%对种类进行编码
y = zeros(150, 1);
y(strcmp(classf, 'setosa')) = 1;
y(strcmp(classf, 'versicolor')) = 2;
y(strcmp(classf, 'virginica')) = 3;
%
%%
% 2. 设定聚类个数和加权指数,最大迭代数和收敛精度
n = size(x,1); %样本个数
p = size(x,2); %一个样本中的变量数
c = 3; %类个数
m = 1.5; %加权指数m的取值范围是(1.5,3.5)
maxtimes = 150;
precision = 0.0001;
%%
% 3.初始化隶属矩阵,取[0,1]的随机数,隶属度矩阵的维度是cXn
%%
U = rand(c,n); %初始化随机矩阵,范围[0,1]
v = zeros(c,p); %c行p列的矩阵,对每一类每一个变量的中心
J = zeros(200,1);
J(1) = 0;
errorJ = 1;
times = 1;
%%
% 4. 计算聚类中心
while (errorJ>precision && times
Original: https://blog.csdn.net/qq_42984090/article/details/125799261
Author: 木头征
Title: 模糊聚类方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/560686/
转载文章受原作者版权保护。转载请注明原作者出处!