

目录
- 参数
* - n_samples(int/array-like,100)
- n_features(int,2)
- centers(int/ndarray of (n_samples, n_features),None)
- cluster_std(float/array-like,1.0)
- center_box(tuple,(-10.0,10.0))
- shuffle(bool,True)
- random_state
- return_centers(bool,False)
- 返回值
- 使用实例
sklearn.datasets.make_blobs(n_samples=100, n_features=2, *, centers=None, cluster_std=1.0, center_box=(- 10.0, 10.0), shuffle=True, random_state=None, return_centers=False)
生成具有各向异性的高斯分布散点用于 聚类
参数
n_samples(int/array-like,100)
生成的训练样本数量
如果是整数,这些点将被均分到所有种群中
如果是类数组,则其中的每个元素都表明一个种群中样本点的数量
n_features(int,2)
每个样本具有的特征数量
centers(int/ndarray of (n_samples, n_features),None)
生成样本中心点(种群)的数量或者固定的中心点的位置
如果n_samples是整数而且centers是None,将生成3个中心点
如果n_samples是一个类数组,那么centers必须是None或者一个长度等于n_samples的长度的数组
cluster_std(float/array-like,1.0)
生成样本点的标准差,表示生成样本点分布的松散程度
center_box(tuple,(-10.0,10.0))
如果centers是随机生成的,那么这个参数表示每个种群的边界框
shuffle(bool,True)
是否打乱样本点
random_state
决定随机数的生成(类似于种子)
return_centers(bool,False)
是否返回每个种群的中心点
返回值
数据类型形状描述xndarray(n_samples, n_features)生成的样本点yndarray(n_samples, )生成样本点的标签
使用实例
from sklearn.datasets import make_bolbs
import matplotlib.pyplot as plt
import numpy as np
centers=[[-1,1],[2,-2],[-2,-3]]
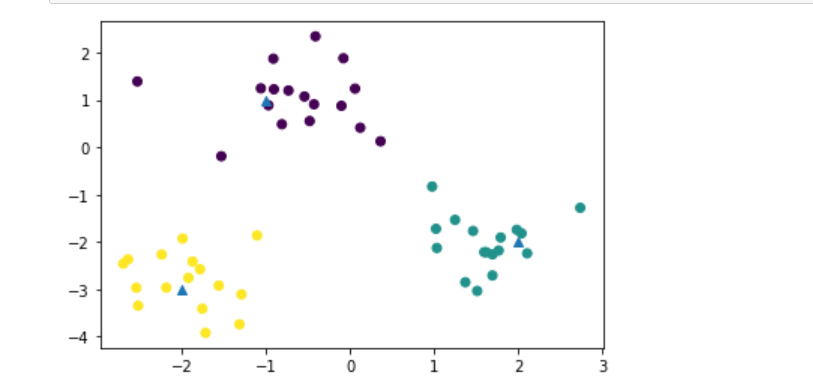
x,y = make_blobs(n_samples=50, centers=centers, cluster_std=0.60,random_state=0)
plt.figure()
c=np.array(centers)
plt.scatter(x[:,0],x[:,1],c=y)
plt.scatter(c[:,0],c[:,1],marker='^')
plt.show()
生成数据点如图所示,样本点被分为3个种群

Original: https://blog.csdn.net/m0_54510474/article/details/124340349
Author: 夺笋123
Title: 聚类数据生成函数–make_blobs()
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/560400/
转载文章受原作者版权保护。转载请注明原作者出处!