
文章目录
原文地址
https://arxiv.org/abs/2112.11573
初识
本文主要提出了异常检测领域中一类新任务:异常聚类(Anomaly Clustering),相比于一般意义上的异常检测【需要构建一个分类器将数据划分为 Normal和 Anomaly两类,如图(a)所示】,异常聚类的目标是将所有数据划分为许多个簇,每个簇代表不同的异常 / 正常,如图(b)所示。
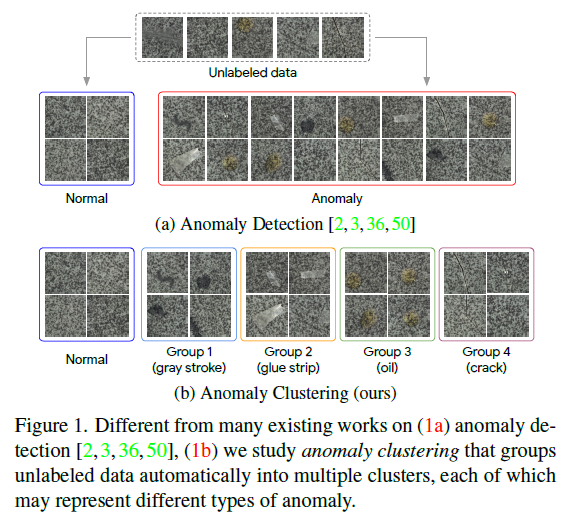

关于这个任务的实际意义,作者提到了两点:1)聚类结果可以被用来生成主动学习查询数据,这可以提升异常检测方法的性能;2)可以帮助工程师分析导致各种异常类型的根本原因,以修复制造流程中的缺陷,减少异常行为。
第一点不太理解,文章引用到的一些方法也比较老,感兴趣可以去查阅原文。
虽然现在(深度)图像聚类的方法已经发展不错了,但本文提出的这个问题还具有很多挑战:1)首先,与典型的图像聚类不同,用于异常聚类的图像可能 不是以对象为中心的,因为这些图像主要是局部区域出现异常;2)其次,在工业应用中数据收集有限,这使得在大型数据集上训练的先进深度聚类方法不太适用(作者也做了实验)。
最后作者在这个任务上提出了一种新的异常聚类框架,并在不同的数据集上验证了方法性能。
; 相知
框架总览
整体的框架如下图(a)所示,其主要做法还是建立在传统聚类策略上,定义好两副图像之间的距离,进行聚类。但之前也提到,与传统的图像聚类不同,这个任务需要更关注于 局部细节,因此先使用 预训练模型提取 patch-level特征,这样每幅图像都会对应一 包(bag) patch嵌入,任务目的就是将每个 包嵌入分配到对应的簇中(assign a cluster membership to each bag)。
附录中介绍了不同架构的具体做法,对应报告的结果(WRes50)采用block2的输出 + 3×3 pooling。
总之,作者将这个任务视为多实例聚类问题(multiple instance clustering, MIC),整体步骤如下:
- 提取patch嵌入,并将一幅图像中的所有特征嵌入定义为一个包(bag),图(a)中橘色部分;
- 计算包与包之前的距离;
- 应用基于距离的聚类方法(比如层次聚类、谱聚类)。
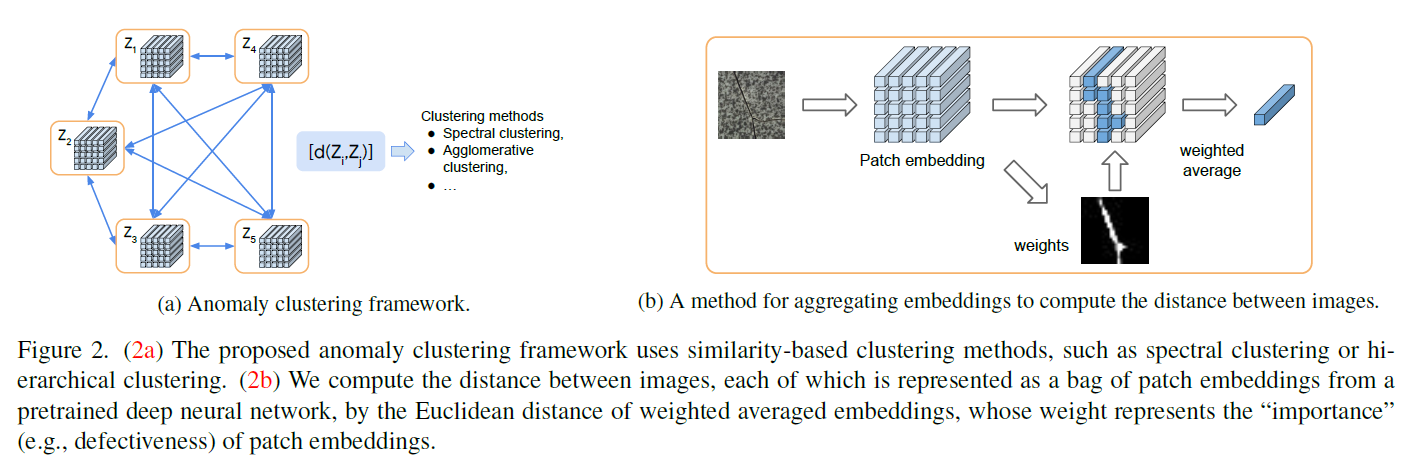
距离度量
框架确定下来之后,可以发现与其他聚类框架一样,一个好的距离度量就显得非常重要。由于在这个任务中,并不是每个patch都有相同的贡献【主要靠异常区域】。因此采用加权平均的方式计算出每个包的整体特征,再根据整体特征去计算距离:

其中,α对应于权重。作者针对无监督 / 半监督两种不同的模式来确定α。
1)无监督模式【不区分正常图像与异常图像】
- 根据 豪斯多夫最大距离进行定义,其中(2)(3)展示了 豪斯多夫最大距离的计算公式,其核心是找到Z i Z_i Z i 和Z j Z_j Z j 之间的最大的相似距离。其对应的权重α所(4)示,

(对包中每个实例先找到对应最相似的实例计算距离,以最大的距离作为d(Zi,Zj))

- 上面的做法使得在计算距离是,每幅图像只考虑两个包中的单个实例。虽然有人提出采用相应的改进办法,但作者实验发现也不鲁棒。因此提出了一个
soft weight的策略,如下所示,其中τ控制α的光滑程度:

2)半监督模式【知道哪些图像是正常图像】
- 如果在训练时,知道数据中哪些图像是正常图像,那么就可以采用下式来计算权重α,其中Z t r Z_{tr}Z t r 为正常图像包的集合:

下图展示了不同数据集的采用不同方法得到的归一化权重α可视化。其中 Segmentation表示从数据集 GT转换而来的权重α。

部分实验
这里只展示部分实验结果,更多实验见原文以及原文附录。
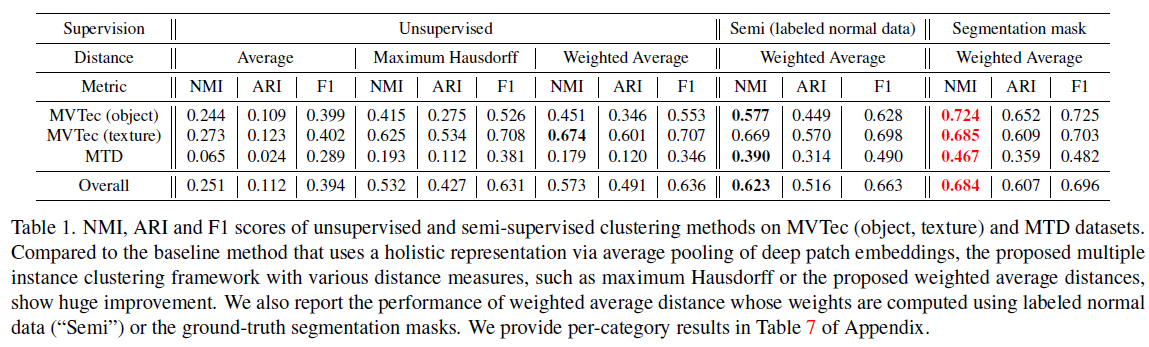
下表展示了不同模式下采用不同方法的结果,因为能够获取到真实聚类标签,可以采用匈牙利算法高效计算GT与预测的最佳匹配,并以此衡量性能。其中 NMI、ARI都是衡量聚类性能的指标, F1 score也是反映聚类的精确度。这几个指标都是 值越大越好。
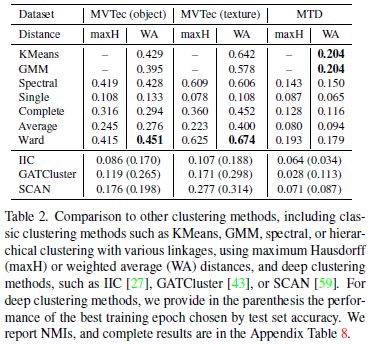
下表展示了步骤3采用不同聚类方法的结果,综合来看层次聚类(Ward)效果最好。
最后展示一下聚类结果,其中红色框表示错分的图像,橘色框表示此图像存在多种缺陷。

回顾
本文是2021年12月 google cloud AI research团队放上Arxiv上的文章,针对的数据集主要还是MVTec AD。这个团队在最近两年针对该数据集做了不少工作,不过目前这个数据集基本上已经被刷爆了【指的是异常检测 / 分割任务】,因此这次提出了一个新坑?
但从整体的思路和做法来看,本文构建的框架和方法并不难,主要是提出了一种新任务,并构建了一个不错的baseline以及提供了大量的消融实验结果。
从排版的格式和放在arxiv上的时间节点来看,大概率是投递CVPR2022的工作,但是否收录目前还不清楚,如果收录了,那后续肯定有非常多基于其改进的方法出现。拭目以待… …
Original: https://blog.csdn.net/qq_36560894/article/details/122577692
Author: 我是大黄同学呀
Title: (2022) 异常检测新任务《Anomaly Clustering: Grouping Images into Coherent Clusters of Anomaly Types》
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/560248/
转载文章受原作者版权保护。转载请注明原作者出处!