

机器学习实践:足球比赛聚类分析
1、实验描述
- 本实验利用K-Means聚类分析算法对足球比赛结果进行分析,该算法通过Sprak Mllib库来调用,我们将学习K-Means算法的K值选取,聚类原理等内容,理解聚类算法在实际业务中的应用场景
- 实验时长:45分钟
- 主要步骤:
- KMeans算法简介
- Spark Mllib库简介
- 数据准备
- 代码编写
2、实验环境
- 虚拟机数量:1
- 系统版本:CentOS 7.5
- Spark版本:spark-2.1.1-bin-hadoop2.7
3、相关技能
- K-Means 算法
- Spark Mllib
4、相关知识点
- spark-shell
- Scala编程
- Spark Mllib
- K-Means
5、实现效果
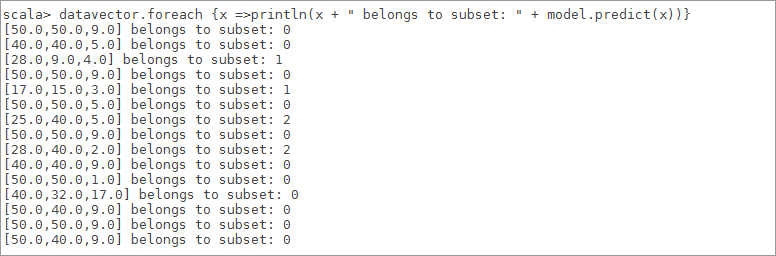

图 1
; 6、实验步骤
6.1K-Means算法:K-Means是非监督学习中的一种聚类算法,K 代表最终将样本数据聚合为 K 个类别。而「均值」代表在聚类的过程中,我们计算聚类中心点的特征向量时,需要采用求相邻样本点特征向量均值的方式进行
6.1.1聚类过程:
6.1.1.1第一步,确定聚类的个数(K),在特征空间上,随机初始化k个类别的中心。当然,k值的大小并不是随机选取的,在我们使用K-Means聚类时我们一般通过计算 轮廓系数来确定k值的大小,我们计算数据集中所有点的轮廓系数,最终以平均值作为当前聚类的整体轮廓系数。整体轮廓系数介于 [-1,1] ,越趋近于 1 代表聚类的效果越好。
6.1.1.2依据上一步随机初始化的中心,将现有的样本按照与最近的中心点之间的距离进行归类。
6.1.1.3通过计算出新的中心点的位置,又接着迭代到上一步的计算,继续求解中心。
6.1.1.4依次迭代下去,直到中心点的变化非常小的时候,停止。就可以将全部样本聚类为k类
6.2Spark Mllib库简介:Spark提供了一个基于海量数据的ML库(MLlib),MLLib提供了常用机器学习算法的分布式实现。开发者只需要有Spark基础,且了解机器学习算法的原理,以及方法相关参数的含义,就可以通过调用相应的API来实现基于海量数据的ML过程,MLlib旨在简化ML的工作实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。本实验中我们将使用Spark MLlib库提供的K-Means聚类算法完成实验
6.3准备实验数据
6.3.1数据说明:数据表示10 支球队在 2006 年~ 2010年的比赛情况,其中包括两次世界杯和一次亚洲杯。图片中的数据做了如下预处理:对于亚洲杯,前四名取其排名,十六强赋予 9,八强赋予 5,预选赛没出线的赋予17。对于世界杯,进入决赛圈则取其最终排名,没有进入决赛圈的,打入预选赛十强赛赋予 40,预选赛小组未出线的赋予 50。这样做方便我们接下来使用数据
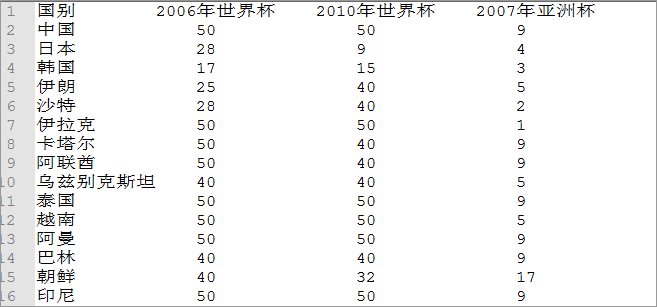
图 2
6.3.2使用vim编辑’data.txt’,添加如下内容,字段之间用空格分隔,并保存。
[zkpk@master ~]$ vim data.txt
50 50 9
28 9 4
17 15 3
25 40 5
28 40 2
50 50 1
50 40 9
50 40 9
40 40 5
50 50 9
50 50 5
50 50 9
40 40 9
40 32 17
50 50 9
6.3.3数据准备完毕,安装spark(这里我们只需要单机版的spark的环境即可),解压tgz下的spark安装包
[zkpk@master ~]$ cd tgz/spark
[zkpk@master spark]$ tar -zxvf spark-2.1.1-bin-hadoop-2.7 -C ~/
6.3.3.1打开spark shell终端
[zkpk@master spark]$ cd ~/spark-2.1.1-bin-hadoop2.7/
[zkpk@master spark-2.1.1-bin-hadoop2.7]$ bin/spark-shell
图 3
6.4导入数据集成为一个RDD对象data,我们用take获取rdd的前15行数据,循环输出看一下
scala>val data =sc.textFile("/home/zkpk/data.txt")
scala>data.take(15).foreach(println)
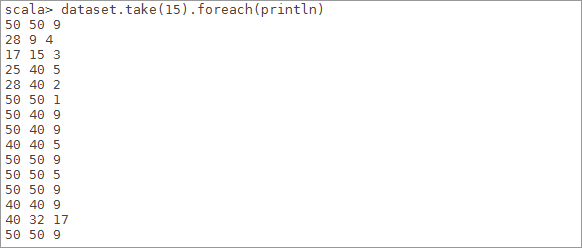
图 4
6.5用import导入Spark Mllib中的Vector和KMeans包,这里的Vector是用来将数据处理成特征向量的工具,KMeans是用来做聚类分析的算法包
scala>import org.apache.spark.mllib.linalg.Vectors
scala>import org.apache.spark.mllib.clustering.KMeans
6.6算法介绍: K-Means 算法是将样本聚类成 k 个簇中心,这里的 k 值是我们给定的,也就是我们希望把数据分成几个类别,具体算法描述如下:
6.6.1为需要聚类的数据,随机选取 k 个聚类质心点
6.6.2求每个点到聚类质心点的距离,计算其应该属于的类,迭代直到收敛于某个值
6.6.3对于每一个类 j,重新计算该类的质心,从而确定新的簇心,一直迭代到某个值或达到要求:
6.7数据处理,训练模型,输出结果
6.7.1将数据以空格切分后,转换成Vector格式
scala>val datavector = data.map{ x => Vectors.dense(x.split(" ").map(_.toDouble))}
6.7.2在计算聚类中心是,需要多次迭代计算,对于迭代计算多次使用到的数据我们利用cache方法缓存到内存加快计算速度,用’collect’查看数据
scala>datavector.cache()
scala>datavector.collect

图 5
6.7.3创建KMeans聚类模型,设置要聚类的子集个数和迭代次数,这里我们将聚类的个数设置为3类,迭代计算100次
scala>val model = KMeans.train(datavector,3,100)
6.7.4模型构建完成后,打印三个子集的质心
scala>model.clusterCenters.foreach { println }

图 6
6.7.5打印数据及对应的子集
scala>datavector.foreach {x =>println(x + " belongs to subset: " + model.predict(x))}
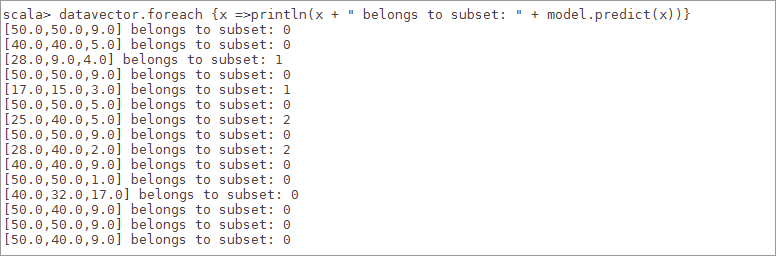
图 7
6.8由聚类中心,数据及对应的分类,知道 3 个类别的索引分别是0、1、2,根据数据我们能看到名次从好到差排序是2、1、0,显然在类别[ 2 ]中有 2 个国家,分别是沙特,伊朗这两个国家足球水平较好点,接着在类别[ 1 ]中有2个国家,分别为日本,韩国这两个国家足球水平一般,最后在类别[ 0 ]剩下 8个国家中数据值都比较高,其中包含中国[ 50, 50, 9 ],说明中国足球有点差。
6.9每次聚类的结果可能略有不同是正常现象
7、总结
K-Means 算法必须先确定K值,K 值的选定是非常难以估计的,在一定程度上影响结果。而K-Means++ 算法给出了解决这个问题的方案,有兴趣的可以看一下。本实验主要讲解了K-Means,并基于算法进行一个简单案例讲解。
Original: https://blog.csdn.net/jintianzheng/article/details/122616349
Author: 奔腾游子
Title: 机器学习实践:足球比赛聚类分析–11
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/560208/
转载文章受原作者版权保护。转载请注明原作者出处!