

以前总结过一次点云下载的相关网站(免费的激光雷达数据的下载方法_依然吧的博客-CSDN博客),这次再更新下。
1.The Stanford 3D Scanning Repository
是初学者用的比较多的数据集,模型居多;
http://graphics.stanford.edu/d


2.SYDNEY URBAN OBJECTS DATASET
数据集包含使用 Velodyne HDL-64E LIDAR 扫描的各种常见城市道路对象,收集于澳大利亚悉尼的 CBD,对不同类别的车辆、行人、标志和树木进行了 631 次单独的物体扫描。
收集它是为了测试匹配和分类算法。 它旨在提供代表实际城市传感系统的非理想传感条件,在视点和遮挡方面具有很大的可变性。
Australian Centre for Field Robotics – Faculty of Engineering
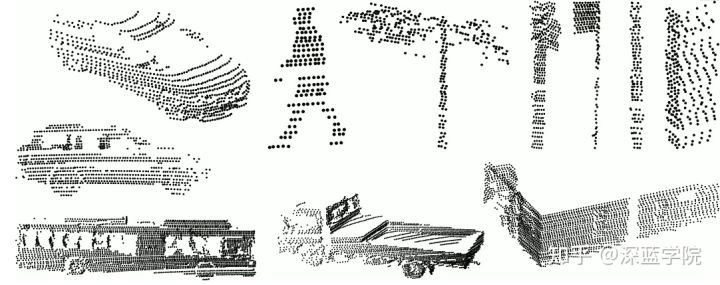
3.ASL Datasets Repository
该站点致力于为机器人社区提供数据集,旨在促进结果评估和比较,数据类型比较多,目标检测和点云配准的都有;
https://projects.asl.ethz.ch/da

4.Large-Scale Point Cloud Classification Benchmark
本数据集提供了一个大型标记的自然场景3D点云数据集,总点数超过 40 亿。它还涵盖了一系列不同的城市场景:教堂、街道、铁轨、广场、村庄、足球场、城堡等等,提供了点云使用最先进的设备进行静态扫描,并包含非常精细的细节。

5.RGB-D Object Dataset
RGB-D 对象数据集是一个包含 300 个常见家庭对象的大型数据集。这些对象被组织成 51 个类别,使用 WordNet 上位词-下位词关系(类似于 ImageNet)排列。该数据集是使用 Kinect 风格的3D 相机记录的,该相机以30 Hz的频率记录同步和对齐的 640×480 RGB 和深度图像。每个物体都放置在转盘上,并在整个旋转过程中捕获视频序列。对于每个物体,有 3 个视频序列,每个视频序列都使用安装在不同高度的摄像机进行记录,以便从与地平线不同的角度观察物体。

6.NYU Depth Datasets
这个数据集应该也是大家比较熟悉的,包括NYU-Depth V1数据集和NYU-Depth V2数据集,都是由来自各种室内场景的视频序列组成,这些视频序列由来自Microsoft Kinect的RGB和Depth摄像机记录。
NYU-Depth V1数据集包含有64种不同的室内场景、7种场景类型、108617无标记帧和2347密集标记帧以及1000多种标记类型。
https://cs.nyu.edu/~silberman/d

7.IQmulus & TerraMobilita Contest
该数据库包含来自巴黎(法国)密集城市环境的 3D MLS 数据,由 3 亿个点组成。该数据库是在 iQmulus 和 TerraMobilita 项目的框架内生成的。它已被法国国家测绘局 (IGN) 开发的 MLS 系统 Stereopolis II 收购。

8.Oakland 3-D Point Cloud Dataset
据库的采集地点是在美国卡耐基梅隆大学周围,用激光扫描仪扫描得到,包含训练集,验证集和测试集数据;
Oakland 3-D Point Cloud Dataset – CVPR 2009 subset

9.The KITTI Vision Benchmark Suite
本数据集是通过在卡尔斯鲁厄中等规模城市、农村地区和高速公路上行驶而捕获的。每张图像最多可以看到 15 辆汽车和 30 名行人。除了以原始格式提供所有数据外,数据集还为每个任务提取基准。
http://www.cvlibs.net/datasets/kit
10.Robotic 3D Scan Repository
这个数据集比较适合做SLAM研究,包含了大量的Velodyne雷达数据;

本文整理了当下主流的三维视觉(图像、点云)与自动驾驶数据集,数据集会持续补充。
适用任务:detection
简介:KITTI数据集由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合创办,是目前国际上最大的自动驾驶场景下的算法评测数据集。该数据集用于评测立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2 km视觉测距序列以及超过200k 3D标注物体的图像组成,以10Hz的频率采样及同步。对于3D物体检测,label细分为car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc。
时间:2015年
简介:Modelnet40 dataset包含约40个对象类别(如飞机,表格,植物等),用三角形网格表示的12311个CAD模型。 数据分为9843个训练样本和2468个测试样本。
时间:2016年
简介:ShapeNet是一个由对象的三维CAD模型表示的形状存储库,注释丰富,规模较大。ShapeNet包含来自多种语义类别的3D模型,并按照WordNet分类法组织它们。它是一组数据集,为每个3D模型提供许多语义标注,如一致的刚性对准、零件和双边对称平面、物理尺寸、关键字以及其他计划的标注。注释通过基于web的公共接口提供,以支持对象属性的数据可视化,促进数据驱动的几何分析,并为计算机图形学和视觉研究提供大规模定量基准。ShapeNet已经索引了超过300万个模型,其中22万个模型被分为3135个类别(WordNet synsets)。
简介:PartNet用于细粒度和分层零件级3D对象理解的大规模基准。数据集包含573585个零件实例,涵盖26671个3D模型,涵盖24个对象类别。 该数据集启用并充当许多任务的催化剂,例如形状分析,动态3D场景建模和仿真,可负担性分析等。数据集建立了用于评估3D零件识别的三个基准测试任务:细粒度语义分割,分层语义分割和实例分割。
适用任务:segmentation
简介:该数据集通过为每个形状添加细粒度部分的递归层次结构的方式,对PartNet数据集进行了增强。
适用任务:segmentation
简介:该数据集提供了来自 2D、2.5D 和 3D 域的各种相互注册的模态,以及实例级语义和几何注释。它包含超过 70,000 张 RGB 图像,以及相应的深度、表面法线、语义注释、全局 XYZ 图像(均采用常规和 360° 等距柱状图的形式)以及相机信息。它还包括注册的原始和语义注释 3D 网格和点云。该数据集能够开发联合和跨模式学习模型以及利用大型室内空间中存在的规律性的潜在无监督方法。
适用任务:classification, segmentation
简介:ScanNet是一个RGB-D视频数据集,在超过1500次扫描中包含250万次视图,附加了3D相机姿态、表面重建和实例级语义分段的注释。
适用任务:matching, classification, clustering
简介:研究人员从互联网上搜集了大量的三维模型,并对这些三维模型进行统一的格式转换,转换成一种简单的格式并且采用人工方式进行分类,提供了161个小类、粗糙一级的6大类、更粗糙一级的两大类共1814个三维模型。
适用任务:matching, classification
简介:这个数据集包含用Velodyne HDL-64E LIDAR扫描的各种常见城市道路对象,收集于澳大利亚悉尼CBD。含有631个单独的扫描物体,包括车辆、行人、广告标志和树木等,可以用来测试匹配和分类算法。
适用任务:registration
简介:该数据集主要被用于特殊环境和条件下点云配准算法的验证。
适用任务:classification
简介:本数据集提供了超过40亿个自然场景下三维点的点云数据,它包含了城市场景下的诸多要素:教堂、街道、铁轨、广场、村庄、足球场等。这些点云数据都是采用当前最先进的设备在静止状态下获取的,包含了非常精细的细节信息。目的是帮助如深度神经网络等数据驱动的方法来发挥他们的作用,学习到更加丰富的3D表达。
22. Canadian Planetary Emulation Terrain 3D Mapping Dataset
http://asrl.utias.utoronto.ca/datasets/3dmap/
适用任务:3D Lidar SLAM
时间:2013年
简介:该数据集是在加拿大两个独特的模拟行星环境中收集的三维激光扫描的数据。这些采集场地在受控环境中提供模拟的行星地形,并以可管理的规模进行算法开发。该数据集被细分为四个独立的子集,使用安装在移动漫游车平台上的平移激光测距仪收集。这些数据可以被用来开发基于非结构化自然地形的3D 激光SLAM算法。所有数据都以人类可读的文本文件形式呈现,并附有Matlab 解析脚本以方便使用。
适用任务:SLAM
时间:2003年-2009年
简介:该数据集涵盖了真实机器人获取的里程计、激光、声纳等传感器数据,还提供了由机器人和人工生成的环境地图。
适用任务:classification, segmentation, detection
时间:2014年
简介:该数据库包含由3亿点组成的巴黎密集城市环境的三维MLS数据。在这个数据库中,对整个三维点云进行分割和分类,即每个点包含一个标签和一个类。因此,可用于对检测-分割-分类方法进行点向评估。
25. Oakland 3D Point Cloud Dataset
http://www.cs.cmu.edu/~vmr/datasets/oakland_3d/cvpr09/doc/
适用任务:classification
时间:2009年
简介:该数据集是从CMU校园周围的城市环境中收集的三维点云激光数据。
适用任务:SLAM
时间:2017年
适用任务:SLAM
时间:2009年
简介:我们提供了一个由一辆改良的福特F-250皮卡收集的数据集。该车辆配备了一个专业的组合导航设备ApplanixPOS LV和消费者惯性测量单元(IMU),一个Velodyne三维激光雷达扫描仪,两个推扫式(push-broom)前视Riegl激光雷达,和一个PointGrey Ladybug系列全景相机。在这里,我们展示了这些安装在汽车上的传感器的时间对齐数据。这些数据集中的车辆路径轨迹包含几个大的和小的环路闭包,这对于测试各种最新的计算机视觉和SLAM算法应该是有用的。数据集的大小约100 GB。
适用任务:detection
时间:2014年
简介:PASCAL 3D+ 是一个 3D 物体检测和姿态识别数据集,包括 PASCAL VOC 2012 中 12 个类别物体的 3D 标注,平均每个类别中包含 3000 个实例。这12个类物体都是刚体,也就是说,它们的三维形状相对具有不变性和一致性,可以用某一/几种通用的三维几何模型做模板进行配准和位姿估计。
适用任务:classification
时间:2016年-2019年
简介:3D MNIST 是一个3D数字识别数据,用以识别三维空间中的数字字符。
适用任务:detection, tracking, prediction
时间:2019年
简介:自动驾驶公司Motional(前身nuTonomy)建立的大规模自动驾驶数据集,该数据集不仅包含了Camera和Lidar,还记录了雷达数据。这个数据集由1000个scenes组成,每个scenes长度为20秒,包含了各种各样的情景。在每一个scenes中,有40个关键帧(key frames),也就是每秒钟有2个关键帧,其他的帧为sweeps。关键帧经过手工的标注,每一帧中都有了若干个annotation,标注的形式为bounding box。不仅标注了大小、范围、还有类别、可见程度等等。
这个数据集在sample的数量上、标注的形式上都非常好,记录了车的自身运动轨迹(相对于全局坐标),包含了非常多的传感器,可以用来实现更加智慧的识别算法和感知融合算法。
适用任务:detection, tracking, prediction
时间:2019年
简介:用于自动驾驶汽车感知的精确的合成图像与LiDAR数据集。
适用任务:detection, tracking
时间:2019年
简介:该数据集主要侧重点在其数据集关注点在车辆自我周围物体的有意义的动态变化,因此引入了这么一个数据集BLVD,这是一个大规模的5D语义基准,它没有集中于之前已经充分解决的静态检测或语义/实例分割任务。取而代之的是,BLVD旨在为动态4D(3D +时间)跟踪,5D(4D +交互式)交互式事件识别和意图预测的任务提供一个平台。BLVD数据集包含654个高分辨率视频剪辑,这些剪辑来自中国江苏省常熟市,提取了120k帧。官方完全注释了所有帧,并总共产生了249129个3D标注,以进行跟踪和检测任务。
适用任务:pose estimation
时间:2018年
简介:PedX由超过5000对高分辨率(12MP)立体图像和LiDAR数据组成,并在全局坐标系中提供二维(2-D)图像标签和行人的3D标签。数据是在三个四向停车道交叉路口捕获的,行人与车辆交错。
适用任务:tracking
时间:2019年
简介:Argoverse是第一个大规模的自动驾驶数据收集,它包含带有几何和语义数据的HD地图,例如车道中心线、车道方向和可驾驶区域。我们提供的所有细节使得开发更精确的感知算法成为可能,这反过来将使自动驾驶车辆能够安全地在复杂的城市街道上行驶。
35. Matterport3D
https://niessner.github.io/Matterport/
适用任务:reconstruction
时间:2017年
简介:Matterport的数据获取,使用了三脚架固定的相机设备,有3个彩色相机和3个深度相机,分布在上中下。对于每个全景,它需要沿着垂直方向旋转到6个不同的方向(也就是60度拍一下),每个彩色相机都要拍高动态范围图像。当相机旋转时,3个深度相机持续拍摄数据,整合生成1280×1024的深度图像,与每幅彩色照片进行配准。每个全景图像是由18个彩色图片组成,中心点正好是拍摄人员的高度。
数据集包含90个建筑物的194,400张RGB-D图像,10,800个全景图像,24,727,520个纹理三角面。
适用任务:segmentation
时间:2019年
简介: SynthCity是由367.9M个点合成的全彩移动激光扫描点云。点云中的每个点都被标记了类别标签(9类中的某一类)。
适用任务:detection, segmentation, prediction, depth estimation
时间:2019年
简介:数据集当中包含超过5.5万个由人类标记的 3D 注释帧,来自 7 个摄像头与多达 3 个激光雷达的数据,一份可直接使用的地表地图,一份底层高清空间语义地图(包括车道与人行横道布局等)。该数据集是目前已经公布的,规模较为可观的无人驾驶数据集。
时间:2018年
简介:百度今年发布的自动驾驶数据,数据的规模为超过140K images,每一张分辨率都是3384 × 2710, 并且有3D point cloud的信息和camera pose information。场景十分复杂,数据采集地点在北京(还看到了后厂村路和上地西路),具有拥堵的路况数据。数据具有3D attribute, 每张图有相机的pose信息和准确的3D静态点云。
适用任务:segmentation
时间:2019年
简介:Semantic KITTI 是自动驾驶领域的权威数据集,它基于 KITTI 数据集,对 KITTI Vision Odometry Benchmark 中的所有序列都进行了标注,同时还为 LiDAR 360 度范围内采集到的所有目标,进行了密集的逐点注释。
该数据集包含 28 个标注类别,分为静态对象和动态对象,既包括行人、车辆等交通参与者,也包括停车场、人行道等地面设施。研发团队还将数据采集过程中用到的点云标记工具进行了开源。
- Waymo Open Dataset
- https://waymo.com/open/
适用任务:detection, tracking, prediction
时间:2019年
简介:数据集包含3000个驾驶片段,每一片段包含20秒的连续驾驶画面。连续镜头内容可以使得研究人员开发模型来跟踪和预测其他道路使用者的行为。数据采集的范围涵盖凤凰城、柯克兰、山景城、旧金山等地区,以及各种驾驶条件下的数据,包括白天、黑夜、黎明、黄昏、雨天和晴天。每个分段涵盖5个高分辨率Waymo激光雷达和五个前置和侧面摄像头的数据。车辆、行人、自行车、标识牌等图像都经过精心标记,一共打了2500万个3D标签和2200万个2D标签。
适用任务:detection
时间:2020年
简介:该数据集由RGB图像和LiDAR数据组成,具有显著的场景、时间和天气差异。该数据集由高密度图像(比首创的Kitti数据集多10倍)、严重遮挡、大量的夜间帧(约为nuScenes数据集的3倍)组成,解决了现有数据集中的空白,从而将自动驾驶研究中的任务边界推到更具挑战性的高度多样化的环境中。数据集包含39K帧、7个类和230K 3D对象注释。
- Oxford Robotcar
https://robotcar-dataset.robots.ox.ac.uk/
适用任务:classification, detection, recognition
时间:2015年
简介:这一数据集包含牛津大学从 2014 年 4 月到 2015 年 12 月间通过牛津 RobotCar 平台(使用日产 LEAF 自动驾驶汽车)平均每周在牛津市中心运行 10 公里路线产生的数据。总计约 1010 公里驾驶数据,同时包含超过 2000 万张由六台车载相机拍摄的图片,以及激光测距,GPS 和惯性导航收集的地貌资料,容量 23.15TB。
在数据收集期间,车辆完全处于人工驾驶状态。这些数据中存在所有天气情况,包括雨雪,夜间,直射阳光。在数据集收集的一年时间里,车辆运行在同一区域,但这一地区的道路和建筑情况出现了很大改变。通过一年时间频繁地通行在同一路线中,研究人员可以探究在现实世界动态城市环境中自动驾驶车辆如何进行定位和地图映射。
适用任务:detection, segmentation
时间:2020年
简介:禾赛科技与Scale AI联合发布了自动驾驶开源数据集PandaSet,该数据集采用2款激光雷达和6个摄像头进行数据采集,包含超过16000帧激光雷达点云和超过48000张照片,共100多个场景。除了激光雷达点云和照片外,数据集还包含GPS(全球定位系统)/IMU(惯性传感器)、标定参数、标注、SDK(软件开发工具包)等信息。
尤其值得关注的是,PandaSet数据集对100多个场景的每个场景都进行了目标检测,共检测28类物体;大多数场景还进行了语义分割,共37种语义标签。 目标检测采用传统的长方体标注,因此数据集还通过点云分割工具精确标注了每个点的语义标签。如此细腻的标注,也为深度学习算法模型提供了绝佳的数据资料。
适用任务:reconstruction, recognition, segmentation
时间:2020年
简介:该数据集来自无人驾驶飞行器摄影,涵盖新加坡国立大学校园1.58平方公里的面积。它由大约10亿点组成。每个点都被层次化和基于实例的标签注释。有2,530个基于情态的实例,24个语义类和6个基于模式的区域,可用于对象检测、语义分割、实例分割、快速场景理解、对象检测、三维模型重建等
Original: https://blog.csdn.net/qq_32867925/article/details/123247438
Author: 仰望星空_2022
Title: 三维开源点云数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/559625/
转载文章受原作者版权保护。转载请注明原作者出处!