

1. 构建模板的问答方法
思想: 人工构建大量带变量的问题模板,根据问题的相关部分选取模板形成查询表达式,查询结构化数据库以生成答案。后期有研究工作可以自动生成模板。
优点: 不需要理解问题语义,避开了语义解析难题,可以获得比较准确的答案,回答响应速度快,针对问答领域多跳复杂问题,最新的模板方法也能提供解决思路。
缺点:需要耗费大量人力进行模板校对,以及模板库维护。
当前研究重点: 模板自动生成,克服耗时耗力难题。
2. 语义解析的问答方法
思想: 首先,使用语义解析器解析自然语言问句,生成逻辑表达式,然后根据该逻辑表达式生成结构化查询语言,查询知识图谱,再从返回的实体集合中寻找答案。核心任务是将自然语言转化成机器能够理解和执行的语义表示。
2.1 基于词典—文法的语义解析方法
优点: 可解释性强,结构清晰,在限定领域问答方面有很好效果。
缺点: 很多重要组成部分都需要人工编写;
面对大规模多源异构数据库,存在以下不足:
(1)资源(例如词汇表、规则集)标注费时费力,在训练数据有限情况下,性能大打折扣;
(2)语义表示与知识库联系不紧密,无法在解析过程中利用知识约束;
(3)大规模知识库开放域特性使文本歧义问题严重。
2.2 基于语义图的问题解析方法
思想: 通过对问句分析,构建相对应的语义图,语义图由节点(实体、变量或者类型)、边(关系)、操作符(count、argmax 等)构成,被看作知识图谱子图,实现将问句映射到知识图谱中,再通过图匹配完成问题回答。
优点: 语义图结构与自然语言句子结构具有相似性,故使用语义图作为目标语义表示有显著优点,语义解析过程充分利用知识库的知识约束,由组合文法转换为语义图构建,减少了搜索空间。
缺点: 依赖于一些启发式方法构建语义图,导致缺乏通用性。
2.3 基于神经网络的方法
思想: 将自然语言及对应的语义看作是两种不同语言,语义分析任务被看做类似于机器翻译任务,利用端到端模型,实现将问句翻译成对应语义的表示序列。
优点: 模型简单
缺点: 可解释性差,需要训练语料,大量的标记数据,训练过程较长
2.4 深度学习方法
实体识别采用的经典 BILSTM+CRF 方法,如下图所示,谷歌提出 BERT模型; 关系分类、意图分类,采用基于字级别的深度学习方法; 实体消歧采用深度学习排序方法,判断语义匹配性等。
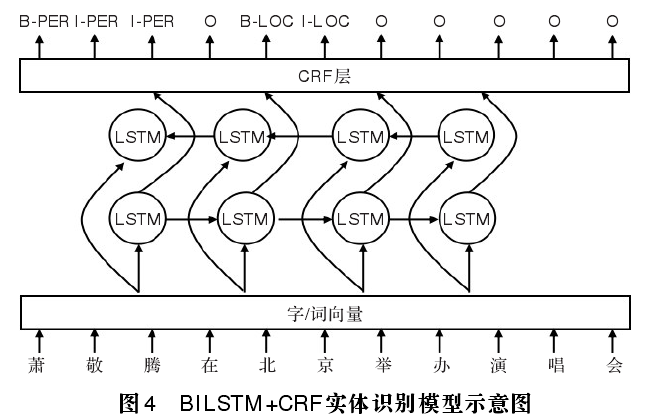

; 3 基于深度学习的答案排序方法
思想: 采用深度学习的方法需要将问题以及知识图谱中包含的丰富的语义信息(字、词语、上下文关系,知识图谱中的实体、关系以及属性),投射到一个高维向量空间,获得字向量或者词向量,通过深度学习模型对向量进行相似度计算,再通过相应打分机制获得候选排序,得出最终问答结果。如下图所示。
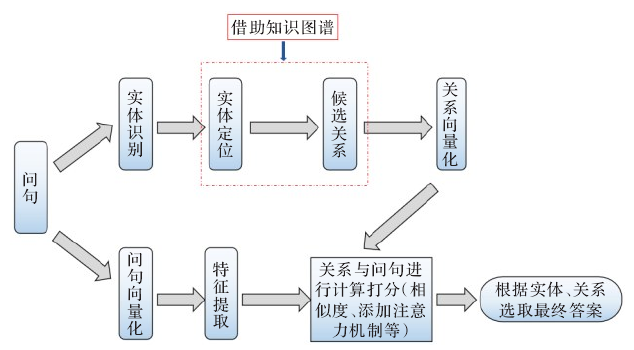
4. 基于知识图谱的嵌入学习问答方法
思想: 将知识图谱中的实体和关系嵌入低维连续向量空间中。
优点: 有很好的可行性和鲁棒性。
5. 多跳推理的知识图谱问答
多跳问题主要分为两类,一类是路径问题,另一类是联合问题。 路径问题指的是问题中只包含一个主题实体,但是含有多个关系,这类问题的解决需要沿着图谱中的某些线路遍历才能找到问题的答案(借助一些关系和中间实体); 联合问题则是包含多个主题实体,这类问题的答案可能是多个路径问题结果的交集。
语义解析方法、深度学习答案排序以及知识图谱嵌入的方法不能有效地解决多跳复杂问题。
多跳推理的问答是当前的研究难点与热点问题,还有许多的工作需要去做。
6. 展望
6.1 回答复杂问题(多跳)
现有的基于知识图谱的问答技术,在单一问题上已取得非常好的效果,如:BERT 模型实验。然而,在实际问答场景下,用户的问题往往复杂,现有的基于深度学习的知识图谱问答方法受到挑战,复杂问题研究仍有很大提升空间。
6.2 深度推理机制
传统的基于符号的推理需要严格符号匹配,推理规则有限,以致领域适应性差,无法实现大规模推理。但是,深度学习作用于分布式语义表示,可以利用语义空间中的相似度计算,弥补符号推理需要严格规则的缺陷。所以,如何利用深度学习的大规模、可学习优点、融入传统逻辑推理规则,构建精准的大规模知识推理引擎是自动问答系统迫切需要解决的又一个热点问题。
6.3 多轮交互式回答
传统的问答系统大多采用一问一答的形式,但是现实应用场景中,用户与机器之间需要多轮交互,由此反馈给用户的答案不只是单一的实体、概念、关系等形式,需要考虑到先前的对话对即将发生的对话的影响或者当前的对话可能对后续对话造成的影响。除此之外,还需要采用用户理解的自然语言形式回复问题。在这一过程中,如何结合知识库,将知识库问答的答案加入自然语言回复中,是亟待解决的问题。
6.4 长尾问句挑战
长尾问句是指近似语义的问题类别的数量在数据集中占比很大,而还有很多不同语义的问题在数据集中数量很少。将问句以柱状图的形式展示就会有很长的”尾巴”,尾巴上都是一些出现频率不高的问句。
如果数据集大部分都是相似的问句,这就会导致数据集的特征比较单一,学习的模型泛化能力不强。这就可能需要使用一些其他的算法来增强模型的泛化能力。
7. 参考文献
[1] 王智悦,于清,王楠,王耀国. 基于知识图谱的智能问答研究综述[J]. 计算机工程与应用,2020, 56(23).
Original: https://blog.csdn.net/weixin_44533255/article/details/120696486
Author: boom boom boom
Title: 知识问答领域方法概述
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558578/
转载文章受原作者版权保护。转载请注明原作者出处!