

参考文献:Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks
摘要
在远程监督关系提取中,提出两个问题。
- 第一,首先,在这种方法中,启发式地将一个已经存在的知识库与文本对齐,并将对齐结果作为标记数据处理。但由于错误标签的存在,启发式的标记是错误的。
- 第二,传统模型进行特征提取过程中产生的噪声会导致性能下降。
针对以上两个问题,本论文提出了PCNN(多实例学习的分段卷积神经网络)。
- 为了解决第一个问题,远程监督关系抽取被处理为多实例问题。在多实例问题中,训练集由许多包组成,每个包有许多实例。包的标签是已知的,但是包中实例的标签是未知的。在包层我们设计了一个目标函数,学习过程中考虑了实例标签的不确定性,从而缓解了错误标签的问题。
- 为了解决第二个问题,采用最大池化进行分段卷积,自动学习关系特征。其中最大池化是用于确定最重要的特征。
引言
在关系抽取中的一个难点是训练集的建立。一般是通过远程监督来完成的。
远距离监督(Mintz et al., 2009),该方法假设,如果两个实体在一个已知知识库中有关系,那么所有提到这两个实体的句子都会以某种方式表达这种关系
远程监督策略的缺点:
- 该方法太绝对,容易导致错误的标注
- 使用传统的模型会导致错误的传播和积累,越长句子,错误标注导致错误传播的几率越大。
这个方法是对2014年Zeng et al提出方法的改进,原来的方法虽然已被证明是在文本处理上是有效的,但它过快地缩小了隐藏层的大小,无法捕获两个实体之间的结构信息
例如”Steve Jobs was the co-founder and CEO of Apple and formerfy Pixar.”,为了确定”Steve Jobs”与”Apple”的关系,我们需要明确实体,并且抽取实体之间的结构特征。有几种试图通过结构信息进行建模的方法。这些方法考虑了句子的内部与外部特征。根据这两个实体,句子实质可被划分为三个部分。内部上下文包括两个实体内部的字符,外部上下文包括两个实体周围的字符。显而易见,简单的最大池化不能满足捕捉结构信息的需要。为了捕捉结构信息和其他潜在信息,在此基础上,我们将卷积结果分为三段,并设计了分段最大池化层代替单一最大池化层。分段最大池程序返回每个片段中的最大值,而不是整个句子中的单个最大值。因此,与传统的方法相比,该方法有望表现出更好的性能。
本文的贡献总结如下:
- 我们探讨了在不需要手工设计特征的情况下进行远程监督关系提取的可行性。PCNNS被提出来自动学习特征,而不需要复杂的NLP预处理。
- 为了解决错误的标签问题,我们开发了创新的解决方案,将多实例学习纳入到远程监督关系提取的PCNNS中。
- 在该网络中,我们设计了分段最大池化层,以捕获两个实体之间的结构信息。
相关工作
监督学习是众多方法中,表现相对好的。但如何得到合适的标记样本,是一个问题。上面提出的远程监督的方法,会导致错误的标记。为了解决这个问题,多实例远程监督方法被提出。多实例学习中,标签的不确定性被考虑,多实例学习的重点是区分bags。
这个方法已经被证明是有效的,但是结果的好坏很大程度上取决于特征。大多数现有的研究都集中在提取特征来识别两个实体之间的关系。过去的方法主要分为两类:以特征为基础的方法和以核(kernel)为基础的方法。与第一种方法相比,第二种方法不需要进行特征提取。有几个核已经被提出:the convolution tree kernel、the subsequence kernel、the dependency tree kernel
Zhang和Zhou(2006)成功地将多实例学习纳入了传统的反向传播(BP)和径向基函数(RBF)网络中,并通过最小化平方和误差函数来优化这些网络。与他们的方法不同,我们根据交叉熵原理定义目标函数。
方法论
我们提出了创新的解决方案,将多实例学习合并到卷积神经网络来完成这项任务。提出了一种不需要复杂的NLP预处理的特征自动学习算法。过程包含如下四部分。
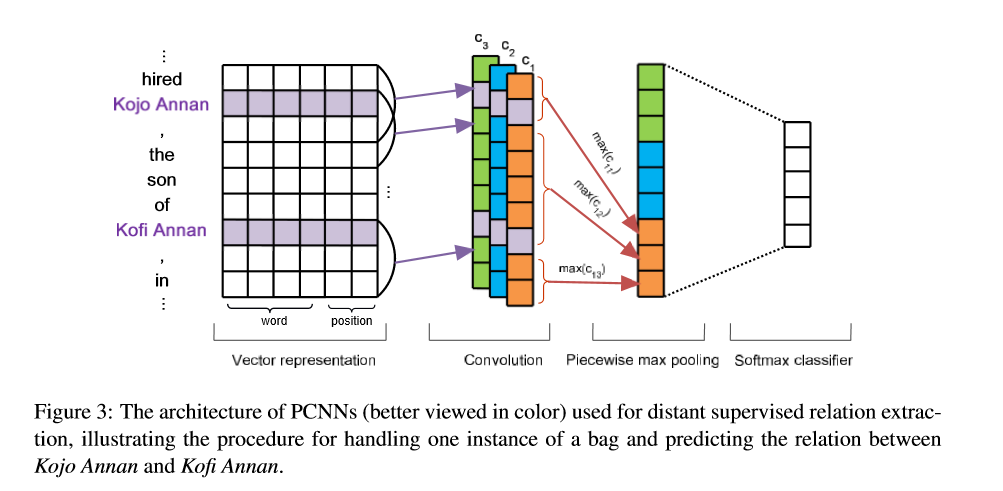

; 1、Vector representation
网络的输入是原始单词标记。在使用神经网络的时候,我们将单词标记转化为一个低维的向量。在我们的方法中,每个输入的单词标记通过查找预先训练好的word embeddings被转换成一个向量。除此之外,我们使用PFs(position features)来指定实体对,并通过查找位置嵌入来将实体对转换为向量。
1.1、word embeddings
单词嵌入是单词的分布表示,它将文本中的每个单词映射到一个k维实值向量。
1.2、position embedding
在关系抽取中,我们把标签分配给实体对。PF定义为当前单词到e1和e2的相对距离的组合(建议得到距离后最好统一除以句子的长度,进行数值归一)
2、Convolution
在关系抽取中,被标记为包含目标实体的输入句子只对应于一个关系类型;它不会去预测每个单词的标签。因此,利用所有特征进行预测是必须的。这个卷积方法就是一个自然融合所有特征的方法。
卷积是一个权重向量 w和输入序列 q直接的操作。权重 w被看作是卷积的滤波器。例如Figure3,假设权重向量 w的长度为3, q序列的长度为 S。一般q i , j q_{i,j}q i ,j 指的是序列 q的第i个元素到第j个元素。
如Figure3所示,
- Vector representation->Convolution,该过程设置了3个卷积核(权重矩阵),获得了c1,c2,c3三个卷积层向量
3、Piecewise Max Pooling(分段最大池化)
输出矩阵 C的大小取决于输入网络的句子被分割序列的长度。然而,为了应对接下来的网络层,必须将卷积层提取的结果统一成一致的尺寸。一般用池化的方式完成该操作,通过捕捉每个窗口中值最高的或者权重最大的特征来解决。(个人认为,这个说法是错误的,实质上传统池化只是用来捕获重要特征,滤掉不重要特征,降低计算维度,而没有将卷积输入统一的任务。在图像处理中,一般是入模型之前通过resize函数统一图片尺寸,在自然语言处理模型中,将输入长度统一的任务是在入模型之前就完成的,一般通过句子直接截取的方式完成)传统的池化操作,不能满足关系提取的需求。正如上面部分所描述的那样,传统的最大池化降低卷积层输出维度的速度过快,对关系提取特征的捕捉太粗糙。除此之外,传统池化方法也不能满足对两实体结构信息捕捉的需要。在关系提取任务中,一个输入句子基于输入实体能够被划分成三部分。正如Figure3所示,卷积层的每层输出也会被对应分为三部{ c i 1 , c i 1 , c i 1 } {c_{i1},c_{i1},c_{i1}}{c i 1 ,c i 1 ,c i 1 }
- Convolution->Piecewise max pooling pooling,该过程首先,是将卷积层每层输出映射成一个三维向量;然后,将三个三维向量拉直成1个9维向量;最后经过非线性激活函数tanh(双曲正切)将值映射至-1到1上
4、Softmax Output
该层通过输入上层的9维向量g,可以输出该句子对每种关系的置信度或者类似于每种关系的概率。
- Piecewise max pooling->Softmax classifier,以9维向量为输入进行softmax处理
5、多实例学习
为了缓解错误标签的问题,我们对PCNN网络使用多实例训练。
- 将网络的输入看成T个bags,袋中为{M1,M2,…,MT}
- 第i个bag中包含qi个元素,分别为{m(i,1),m(i,2),…m(i,qi)}
从客观上讲,多实例学习是去预测不可见bags的标签。在本文中,认为一个bag中的所有样本都是独立的。每给出一个m(i,j),网络就会有一个o向量被输出。这里o值对应的第r个元素就是对应第r个关系的概率。
具体的学习算法如下
- 初始化参数
- 分割样本集为多个实例个数相同的mini_bags
- 在每个mini_bag中找到在当前参数条件下被判别为bag标签概率最大的样本,即在该参数下最符合该bag标签的样本。以此样本的损失来更新参数。
从以上算法可以看出,传统的反向传播依靠的是所有实例,而多实例学习的反向传播是基于bags的。因此,我们的方法抓住了远程监督关系提取的本质,就是其中许多训练实例不可避免的会被标错。当使用训练好的PCNN进行预测时,当且仅当网络在其至少一个实例上的输出被赋予正标签时,bag才被赋正标签。
试验
我们的试验就是想证明基于多实例训练的方式使用PCNN网络进行自动特征学习将会有一个更好的表现。我们首先选择数据集与评估矩阵。接着通过交叉验证的方式确定我们的参数。然后将我们的方法与一些传统的方法进行比较。最后我们评估分段最大池化和多实例学习的效果。
1、数据集和评估矩阵
- 数据集:该数据集是通过将Freebase关系与NYT语料库对齐而生成的
- 训练集是2005-2006年的语料
- 测试集是2007年语料
- 评估:
- 查全率/查准率曲线
- 人工评估,新发现了不少不在Freebase中的关系
2、实验设置
2.1、预训练词向量
在本文中,我们使用Skip-gram去训练基于NYT的词向量。Word2vec算法首先从训练文本数据中构建一个词汇表,然后学习词的向量表示。最终选择50的词向量。
2.2、参数设置

主要调优参数为卷积窗口大小w、特征映射数量n
调试策略:三折交叉验证、网格搜索
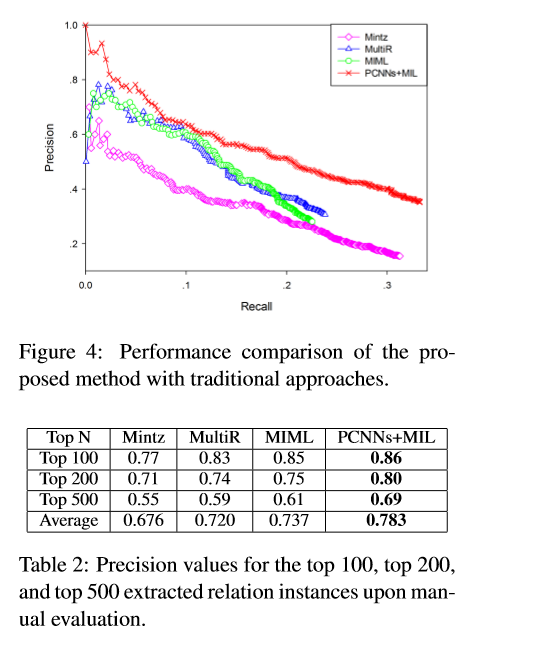
; 3、与传统方法比较——held-out比较与人工评估
传统模型选择:
- Mintz,是一个传统的基于远程监督的模型,该模型是在2009年由Mintz提出的。
- MultiR,是一个多实例学习模型,该模型是在2011年由Hoffmannet提出
- MIML,是一个多实例多标签模型,该模型是在2012年由Surdeanu提出
分段最大池化与多实例学习的影响
本文开发了一种关系抽取方法,该方法包含分段最大池化、基于远程监督的多实例学习两部分。两部分的效果如图5
- CNNs,是使用传统最大池化的卷积神经网络;
- PCNNs,是分段卷积神经网络;
结果可以看出分段卷积网络结果优于单纯的卷积神经网络。同时,与CNNs+MIL比较,PCNNs在召回率高于0.08时拥有更高的精确度。
Original: https://blog.csdn.net/weixin_43128028/article/details/108919201
Author: 人马座α星
Title: 多实例学习PCNN在关系抽取中的应用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558485/
转载文章受原作者版权保护。转载请注明原作者出处!