

细胞是人体的基本结构和功能单元。实际上,人体的所有细胞都拥有相同的基因组,但是它们在表征和功能上展现出丰富多彩的异质性。这些异质性包含了细胞的转录组、表观基因组以及蛋白质特征的丰富模式和变异。构建一个具有分子属性的,包含人体各类器官细胞的人体细胞图谱对理解人体非常重要,并且这将给研究人体健康和疾病提供一个重要的依据。这对科学研究很重要,甚至比人体基因组工程更加重要。随着单细胞组技术,尤其是RNA序列技术的蓬勃发展,人类开始了雄心壮志的计划,比如人体细胞图谱(HCA)、人体细胞分子编程(HuBMAP)和人体细胞成长图(HDCA),从而构建完整的人体细胞图谱。同时,技术的快速普及使得全世界的实验室比大的联营企业更快地产生单细胞数据。组装分散的数据成给构建细胞图谱的另一种方法。
细胞图谱的组装面临重大的信息挑战。这些挑战主要来源于复杂的人体细胞系统,以及如何组装分散的数据。
第一个挑战数据在深度以及宽度上的尺寸问题。人类的基因有3 × 1 0 9 3\times 10^9 3 ×1 0 9个核苷酸和或者碱基。在人体基因组工程中,序列片段会被映射到一维的主干中。细胞是人体细胞图谱的基本单元,一个成年人类的细胞数量大概是1 0 13 − 14 10^{13-14}1 0 1 3 −1 4。每一个细胞都包含了一个基因组和各种基因的表达产物。现有的scRNA-seq技术测量了细胞中蛋白质编码基因的表达能力。随着未来包括选择性剪接转录、非编码转录以及表观基因组特征,如甲基化和染色体开放程度,每个细胞的特征数可能大于1 0 6 10^6 1 0 6。一个存储基因组信息的数据表尺寸一般不超过1 0 9 × 1 0 2 − 3 10^9\times 10^{2-3}1 0 9 ×1 0 2 −3。但是对一个完整的人体细胞图谱,它的尺寸可能最终会达到1 0 13 − 14 × 1 0 6 × 7 10^{13-14}\times 10^{6\times 7}1 0 1 3 −1 4 ×1 0 6 ×7。所有的数据都是不可替代的理论是有争议的,但是判断哪些数据可以被丢弃还为时尚早。即使在去除了冗余之后,细胞图谱的的数据尺寸仍然在宽度和深度上远大于基因组的数据大小,可能传统的关系数据库技术无法满足。
第二个挑战在于缺少一个统一的细胞索引。人类基因组有一个自然地一维索引,所有的信息都是通过它组织起来的。一些科学家认为解剖学的几何形状是人类细胞的一个自然索引,并且提出开发一个通用的坐标框架(CCF)来对齐个体之间的几何形状。这不是简单的任务,并且CCF在多大程度上可以作为图谱的索引是值得怀疑的,因为器官中特定细胞的几何位置不是确定的,在微观水平上也不是注定的。由HuBMAP联盟提出的ASCT+ B表建议使用解剖结构,细胞类型以及生物标记作为所有细胞的索引。人体的复杂性需要一个多颗粒的指标系统。该系统的内容和体积应该是可扩展的,因为目前关于复杂单元系统的知识仍然有限。
第三个挑战是标注细胞时缺乏一致性。细胞类型和细胞的状态是细胞图谱研究中两个主要的概念,但是它们在许多研究中没有严格的定义。在不同的,甚至是相同的研究中,它们使用的标记不一致。当考虑到发展或者刺激-反应过程中的动力学时,不确定性和不一致性进一步增加。需要一个可扩展的统一结构实体与索引系统相结合,以将数据组装成图谱,使得数据在程序集中可复用。
一个理想的细胞图谱应该将所有器官的数据组装到一个统一的存储库中,如下图所示,而不是一个数据集的集合。
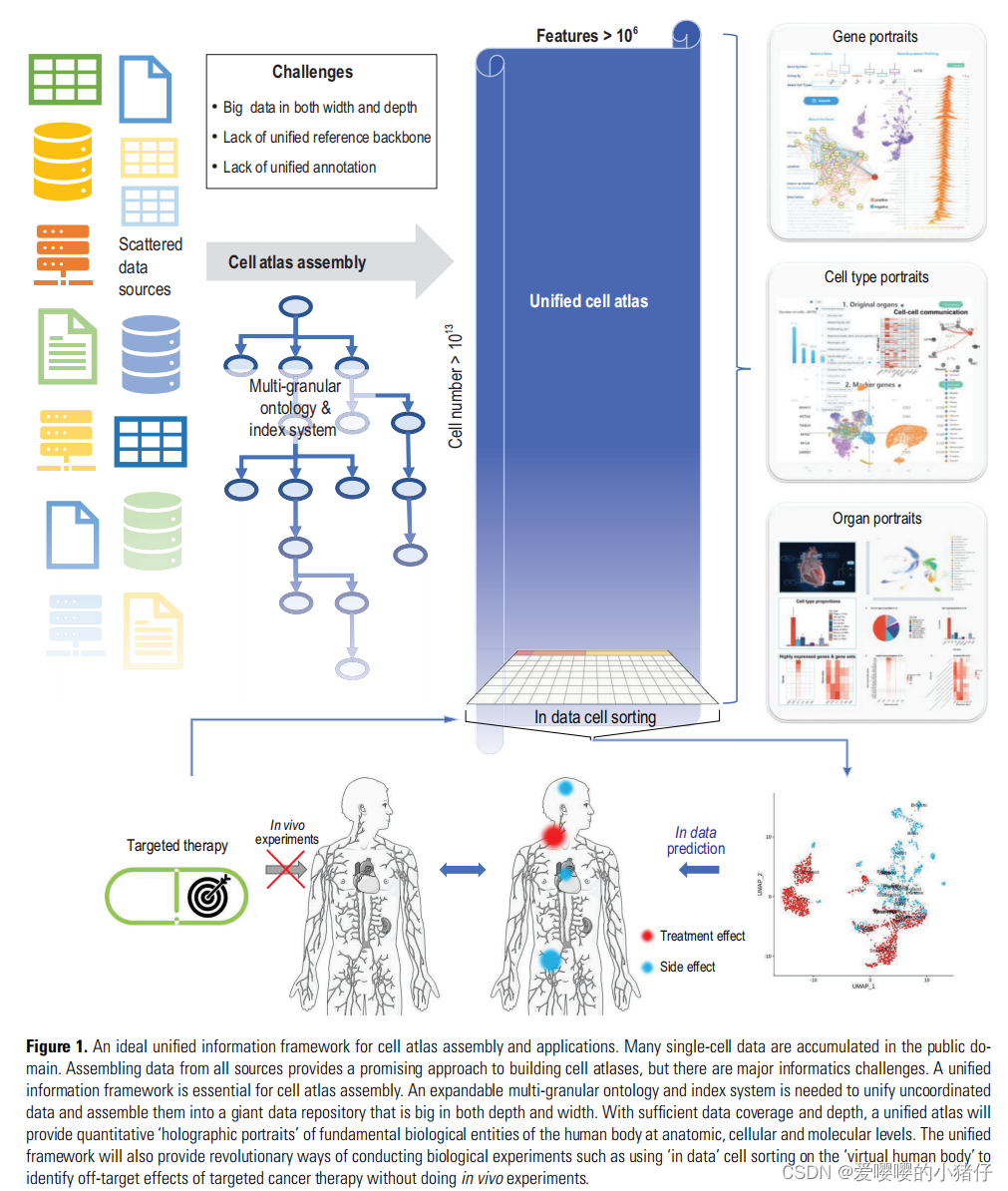

一个统一的信息框架是很重要的。它应该包含了一个基础设施,可以存储和检索理想的无限大小和维度的所有数据,一个潜在的信息图或者网络,可以整合并且有效地表征细胞的解剖学、细胞学和功能属性以及系统的多种标记。统一的框架应该可以给细胞的各种属性添加索引,并且可以从不同的资源中方便有效地浏览、搜索和反复使用所有以及特定细胞或者子图谱的特征。人们一直在努力搜集单细胞数据,并且建立对这些数据的综合用途,但是一个统一的信息框架仍然是缺失的。大多数大规模的生物信息学数据库,如NCBI中的那些数据库,都是根据所提交的顺序组织索引文件,而不是根据数据之间的内在关系。在人类掌握和使用综合数据中的一个重大进步就是地理信息系统(GIS)的使用,GIS捕捉、存储并且展示了不同数据和地球表面位置的关联信息。细胞图谱的统一信息框架应该像一个超级GIS,它可以包含与人体细胞相关的微观、介观和宏观数据,以及一个活的GIS系统,它可以代表超越空间地图的多方面功能数据和关系。
为了探索可行的解决方式,我们提出了一种联合的信息框架,集成细胞图谱(ECA),作为解决这些挑战的统一细胞图谱原型。它包含了一个用来管理大数据的宽列统一大表(uGT),一个用来索引和标注细胞的统一层次标注框架(uHAF)以及一个搜索引擎ECAUGT,用来在uGT中实现逻辑搜索。该框架允许细胞在所有可能被用于坐标的特征上都有统一的索引,包括在多个尺度的空间和时间特征上。
利用该框架,通过组装覆盖了38个器官的分散scRNA-seq数据以及超过100万个的细胞数据,构建了人类集合细胞图谱(hECA)的主要版本。和最终目标相比,这个版本还是很浅显的,但是它已经展示而来统一信息框架的力量和潜力。它在内部服务器上的实现可以扩大几个大小,在未来能够包含数十亿个具有百万特征的细胞数据。
这种统一的细胞图谱不仅具有基本的应用,如查询细胞的注释,而且创建了一个全新的方案,从各个角度描述图谱中的生物实体(解剖单位、细胞类型和基因)。一种细胞类型不再仅仅是少数标记基因的向上或向下表达,而是以所有相关基因的表达分布、所有器官的参与以及与其他细胞类型的相互作用为特征。当发育或刺激-反应数据可用时,也将把谱系和瞬态信息包括在内。同样,一个基因的特征是其在所有细胞类型、亚型和器官中的表达分布、其时空模式及其与其他基因的关系。随着数据类型和覆盖范围的增加,这将最终增加我们对生物实体的理解,从粗略的”快照”到定量的”全息肖像”。
统一的细胞图谱可以将许多生物实验转化为计算机代码。我们使用典型的细胞分选生物学实验来研究一个统一的细胞图谱如何彻底改变生物实验。细胞分选是一种实验技术,从人体样本(体内)或培养细胞(体外)中选择具有所需特性的细胞。这对许多科学研究都是至关重要的。可用于选择细胞的特征的数量和类型受到限制,从多个体内样本中分类细胞是劳动密集型的,而且往往是不可行的。
一个统一的细胞图谱可以允许用户使用组合逻辑条件对几乎所有特征进行搜索细胞,包括一个或多个基因的表达、细胞类型或亚型、来源器官和供体的元数据(性别、年龄、健康状况等)。一个最终统一的图谱将成为数据空间中细胞的”虚拟人体”。搜索具有任何期望属性的细胞都可以通过探索虚拟体的计算机代码来实现。我们将此方案命名为”在数据中”的细胞排序,因为它选择了数据体中的细胞。在最近的工作中,如Sfiara和HCA数据协调平台(DCP)(https://data.humancellatlas.org)中也提出了类似的想法,用于使用注释标签或表达值的标准筛选单细胞数据,但它们主要集中于数据集的选择,而不是细胞。
在目前有限的数据覆盖范围的基础上,我们在hECA中进行了实验来研究该方案。例如,我们研究了一种嵌合抗原受体t细胞(CAR-T)靶向癌症治疗可能产生的副作用。我们对来自不同供体的多个器官中表达靶向蛋白的所有细胞进行了数据细胞分类。通过分析对这些细胞和宿主器官的影响,可以快速识别出脱靶器官。这些例子突出了在统一的图集中定制数据重用的能力,尽管当前的数据仍然有限。
已经有工作使用机器学习方法为查询单元提供注释,或基于细胞参考数据的集成估计批量数据中成员细胞类型的丰度。将大量分散的数据统一组装成一个图集,并通过对组装中想要的细胞进行数据排序来敏捷地构建定制的子图集,这也可以为这些方法提供更好的参考。
科学界在建立细胞图谱方面表现出了巨大的热情。然而,大多数实验室的兴趣都集中在使用单细胞技术的特定问题上。如果能够很好地解决主要的信息学挑战,它们不断产生的大量数据将成为以自下而上的方式组装细胞图谱的重要来源。ECA是在这个方向上的第一次尝试。它提供了一个原型来展示一个统一的信息框架从所有来源的数据构建一个细胞图谱的有前途的策略。
Original: https://blog.csdn.net/weixin_43199832/article/details/125658359
Author: 爱嘤嘤的小猪仔
Title: Toward a unified information framework for cell atlas assembly论文笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558387/
转载文章受原作者版权保护。转载请注明原作者出处!