

Yunmo Chen1
Tongfei Chen1
Seth Ebner1
Aaron Steven White2
Benjamin Van Durme1
1Johns Hopkins University
2University of Rochester
{yunmo,tongfei,seth,vandurme}@jhu.edu
aaron.white@rochester.edu
精简总结
本文提出了一种事件抽取模型,使用从注释手册中提取的漂白语句来抽取事件信息。
1 介绍
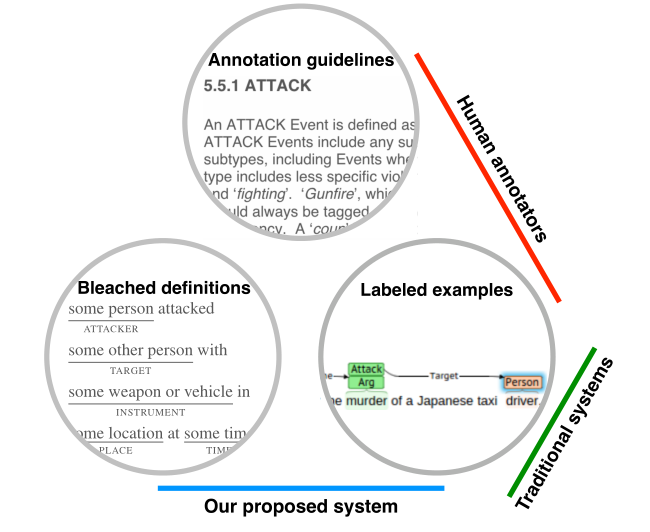
本文旨在解决人工标注和机器在信息提取中的脱节,如下图所示,人类注释者使用注释指南和有限的说明性示例,传统系统使用大量标记的示例,我们的系统使用漂白的语句(源自注释指南)和标记的示例。

本文选用ACE2005数据集进行实验,
主要贡献有
- 一种新的事件提取方法,通过漂白语句考虑注释准则;
- 一个多跨度选择模型,证明事件提取方法以及零镜头和少镜头设置的可行性。
; 2 背景
传统的事件抽取工作分为三个子任务,
- 事件触发词检测
- 实体提及检测:检测事件的所有潜在参数
- 自变量角色预测:其中检测到的自变量和触发词之间的关系相对于每个事件类型的定义的角色集被识别
先前的工作主要采用流水线的方法或者过于关注基于黄金实体提及范围:
- 基于特征的方法:(Ji and Grishman,2008; Liao and Grishman, 2010; McClosky et al.,
2011; Huang and Riloff, 2012; Li et al., 2013, inter alia) - 基于神经网络的方法:(Nguyen and Grish-man, 2015; Chen et al., 2015, 2017; Nguyen and
Grishman, 2018; Sha et al., 2018, inter alia)
流水线方法存在错误传播的问题,前一子任务的错误往往被传播给后一子任务,所以尝试了三个子任务的联合建模。
- Yang and Mitchell (2016)尝试用手工制作的特性来联合建模这三个组件,但是仍然需要分别检测实体提及和事件触发。
- Nguyen and Nguyen (2019) 使用具有共享底层表示的神经网络联合建模这三项任务。
3和4中提出的模型是本文使用的基线。
Huang et al. (2018)通过为每个事件类型规定一个图结构,并找到其学习表示与解析的AMR 。(Banarescu等人,2013)文本结构的学习表示最匹配的事件类型图结构,来实现零触发事件提取。相比之下,我们的方法放弃了显式的图形结构语义表示,如AMR。
3 公式化
漂白语句的组成:
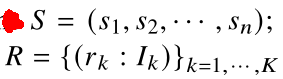
S表示语句的标签
rk表示事先定义好的角色
Ik表示对应角色的索引
举例说明:


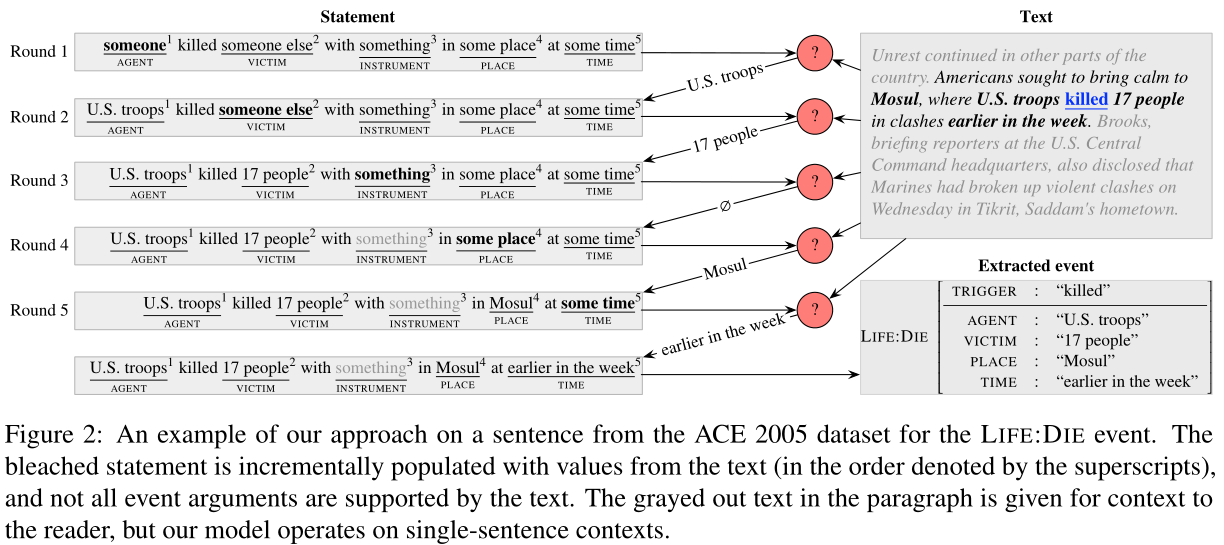
总体来说,本任务是给定一个漂白语句S、占位符字典R和文本标签T,返回一个字典R^,其包含事件触发词和提取的参数。见图2右下角
; 4 方法
给出一个漂白语句,但是非并行地填充占位符,却是以一种强制的规则来从左到右递增地填充。
if 漂白语句A == 空:
找不到对应的文本标签
if 漂泊语句A != 空:
用抽取的标签替代占位符
可能存在多个参数匹配同一个占位符
5 模型
1、 BERT模型
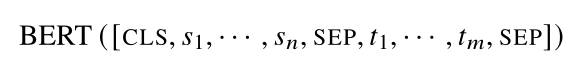
2、多参数选择器
本文的方法与MRC有两个不同:
- 查询不是一个自然语言的问题,而是对一个自然语言的完形填空问题
- 可能有多个参数填充到一个空白处,传统的只能填充一个参数
为解决上面的两个问题,本文提出了算法1

我们强制要求所有提取的跨度都来自文本中的同一个句子,但通常不需要强制要求。此外,我们的模型在单句上下文中运行,因此不考虑其他句子中的可用信息。
; 6 实验
6.1 评估指标
- 触发器识别:如果触发器的跨度偏移与参考触发器完全匹配,则触发器被正确识别;
- 触发器分类:如果触发器的跨度偏移和事件子类型与参考触发器完全匹配,则触发器被正确分类;
- 参数识别:如果一个参数的跨度偏移量和对应的事件子类型与引用参数完全匹配,则该参数被正确识别;
- 参数分类:如果一个参数的跨度偏移量、对应的事件子类型和参数角色与引用参数完全匹配,则该参数被正确分类。
对于以上每个度量,使用精度( P)、召回率( R)和F-measure (F1)来评估性能。
6.2 流程
在SQuAD 2.0数据集上预训练后,在ACE2005上进行微调,在保持其他超参数不变的情况下,我们将学习速率设置为1×10^-5,将训练周期数设置为8。在微调期间,我们采用负采样并将负采样速率设置为30%。
除了对ACE 2005的完整训练集进行微调之外,我们还考虑了一个单一流派的”部分”训练设置,其中模型仅在完整训练集的新闻线部分出现的58个文档上进行训练。
总结
我们提出了一种事件提取的方法,它使用漂白的语句来提供一个模型来访问注释手册中包含的信息。我们的模型用从文本中提取的值来逐步细化语句。我们还证明了对罕见或根本没有的事件类型进行预测的可行性。未来的工作可以将我们的方法应用于n-ary关系抽取。
Original: https://blog.csdn.net/weixin_42324313/article/details/115295191
Author: Fly-U
Title: Reading the Manual: Event Extraction as Definition Comprehension
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558278/
转载文章受原作者版权保护。转载请注明原作者出处!