

-
引言
-
摘要
实体和关系联合提取的目的是利用单一模型检测实体对及其关系。以往的工作通常采用先提取后分类或统一标注的方式来解决这个问题。但是,这些方法在提取实体和关系的过程中要么存在冗余实体对,要么忽略了重要的内部结构。针对这些局限性,本文首先将联合抽取任务分解为两个相互关联的子任务,即HE抽取和TER抽取。前一个子任务是区分所有可能涉及到目标关系的头实体,后一个子任务是识别每个提取的头实体对应的尾实体和关系。然后,基于我们提出的基于span的标记方案,将这两个子任务进一步分解为多个序列标记问题,并采用分层边界标记和多跨解码算法方便地解决这些问题。由于合理的分解策略,该模型能够充分捕捉到不同步骤之间的语义依赖关系,同时减少了来自无关实体对的噪声。实验结果表明,我们的方法比之前的工作性能提高了5.2%、5.9%和21.5% (F1得分),在三个公共数据集上达到了一个新的最高水平。
-
动机
-
传统的流水线方法首先识别实体,然后为每一对可能提取的实体选择一个关系。这样的框架使任务易于执行,但忽略了这两个子任务之间的底层交互。
- 现有的联合模型该对重叠关系的识别不够优雅,这可能导致在处理具有重叠关系的句子时记忆效果不佳。
-
如果一个模型不能完全感知头实体的语义,那么提取相应的尾实体和关系就不可靠。
-
贡献
本文提出一种新颖的分解策略。以一个句子开始,我们首先明智地识别所有可能的候选人head-entities参与目标的关系,然后对每个提取的头实体标注对应的尾实体和关系。我们称前者为头实体(HE)提取,后者为尾实体和关系(TER)提取。这样extract-then-label (ETL)范式可以理解分解三联体提取的联合概率条件概率p ( h , t , t ∣ S ) = p ( h ∣ S ) p ( r , t ∣ h , S ) p (h,t,t | S ) = p (h | S) p (r, t | h, S)p (h ,t ,t ∣S )=p (h ∣S )p (r ,t ∣h ,S ),( h , r , t ) (h, r, t)(h ,r ,t )是一个三联体的句子。此外,与先提取后分类的方法相比,我们的范式不再在第一步提取所有实体,只识别可能参与目标三胞胎的头实体,从而减轻了冗余实体对的影响。
利用基于span的标记方案进一步分解了HE和TER抽取。具体来说,对于HE提取,实体类型在每个头实体的开始和结束位置标记。对于TER提取,我们在与给定头实体有关系的所有尾实体的开始和结束位置注释关系类型。为了增强边界位置之间的关联,我们提出了一个分层的边界标记器,它将起始点和结束点标记出来。
总之, 对于有m个head-entities的句子,整个任务被解构为2 + 2m个序列标记子任务,前2个为HE标记子任务,另外2m为TER标记子任务。
- 标记策略
我们首先介绍了我们的标记策略,在此基础上将联合抽取任务转化为多个序列标记问题。然后详细介绍了分层边界标记器,这是该方法的基本标记模块。
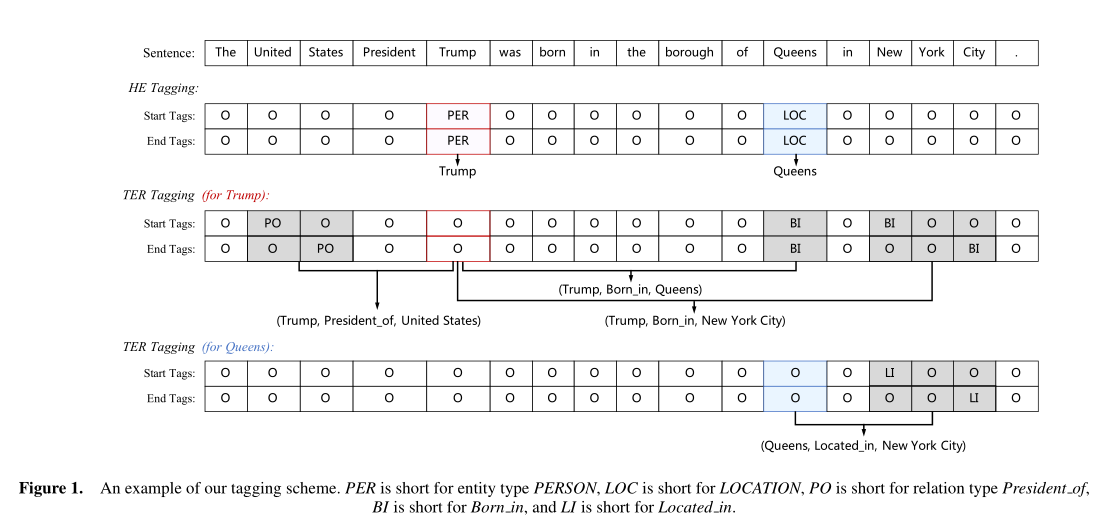

对于每个识别出的头实体,TER提取也分解为两个序列标记子任务,利用跨度边界提取尾实体并同时预测关系。第一个序列标记子任务主要标记尾实体的开始字标记的关系类型,第二个子任务标记结束字标记的关系类型。
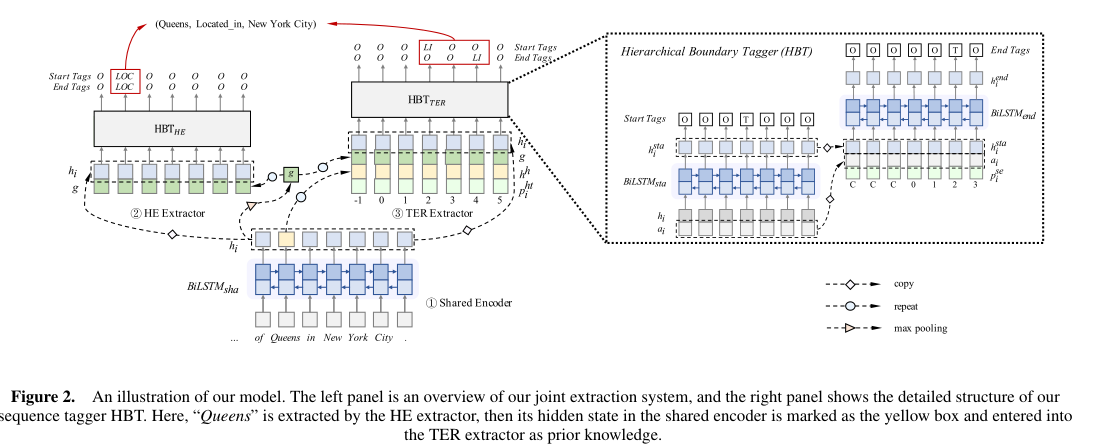
在本工作中,我们选择了B i L S T M BiLSTM B i L S T M作为基本编码器。在形式上,在标注开始位置时,单词x i x_i x i 的标签被预测为下式:

x i x_i x i 的结束标签可以通过下式计算:

如式子所示,我们模型在预测结束位置时能够感知起始位置的隐藏状态。其次,受使用的位置编码向量的启发,我们将嵌入p i s e p^{se}_i p i s e 的位置作为BiLSTM层的附加输入。通过在可训练的位置嵌入矩阵中查找位置嵌入矩阵,可以得到可训练的位置嵌入矩阵:

这里的∗是当前索引之前最近的起始位置,p i s e p^{se}_i p i s e 是x i x_i x i 和s ∗ s^*s ∗之间的相对距离。
我们将HBT的训练损失(待最小化)定义为真实开始标签和结束标签的负对数概率之和。


; 5. 抽取模型
利用基于span的标记方案和分层边界标记器,我们提出了一种端到端神经结构来联合提取实体和重叠关系,首先使用共享的BiLSTM编码器对句子进行编码。在此基础上,构造了一个提取头实体的提取器。对于每一个提取出来的头实体,利用头实体的语义和位置信息触发TER提取器,检测相应的尾实体和关系。

; 5.2 HE Extractor
提取器的目的是区分候选头实体,排除不相关的头实体。

5.3 TER Extractor
与提取器相似,TER提取器也使用和全局向量的基本表示作为输入特征。然而,仅仅连接g g g不足以检测尾实体以及与特定头实体的关系。执行TER提取所需的关键信息包括:(1)尾实体内的单词;(2)依赖的头实体;(3)表明关系的上下文;(4)尾实体与头实体之间的距离。基于这些考虑,我们提出了位置感知、头-实体感知和上下文感知的表示:


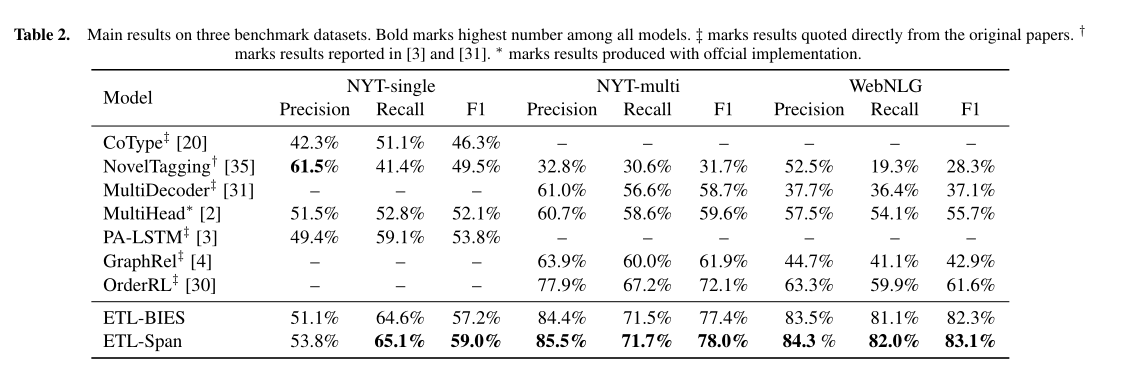
; 6. 实验结果
- 代码实现
Original: https://blog.csdn.net/qq_38556984/article/details/109092842
Author: fond_dependent
Title: Joint Extraction of Entities and Relations Based on a Novel Decomposition Strategy (ECAI2020)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558184/
转载文章受原作者版权保护。转载请注明原作者出处!