

知识图谱嵌入(KGE):方法和应用的综述
1. 知识图谱(KG)
- 由实体(节点)和关系(不同类型的边)组成的多关系图。
- 每条边都表示为形式(头实体、关系、尾实体)的三个部分,也称为事实
1.1 问题
- 这类三元组的底层符号特性通常使KGs很难操作
1.2 解决:
- 提出了一种新的研究方向——知识图谱嵌入。
1.3 关键思想
- 嵌入KG的组件,包括将实体和关系转化为连续的向量空间,从而简化操作,同时保留KG的原有的结构。
2. 融合事实信息
2.1 平移距离模型
- 平移距离模型利用了基于距离的评分函数,通过两个实体之间的距离对事实的合理性进行度量。


; 2.1.1 TransE模型
- 平移不变现象

- TransE模型:将知识库中的关系看作实体间的某种平移向量。
- 对于每个事实三元组(h,r,t),TransE模型将实体和关系表示为同一空间中,把关系向量r看作为头实体向量h和尾实体向量t之间的平移即 h + r ≈ t h+r≈t h +r ≈t。
- 可以将r,看作从h到t的翻译
- 知识库中的实体关系类型可分为 一对一 、一对多 、 多对一 、多对多4 种类型,而复杂关系主要指的是 一对多 、 多对一 、多对多的 3 种关系类型。优点
- TransE模型的参数较少,计算的复杂度显著降低,并且在大规模稀疏知识库上也同样具有较好的性能与可扩展性。缺点
- TransE模型不能用在处理复杂关系上。
2.1.2 TransH模型
- 为了解决TransE模型在处理一对多 、 多对一 、多对多复杂关系时的局限性。
- TransH模型提出让一个实体在不同的关系下拥有不同的表示。
- 对于关系r,TransH模型同时使用平移向量r和超平面的法向量w_r来表示它。对于一个三元组(h, r, t) , TransH首先将头实体向量h和尾实体向量r,沿法线wr,影到关系r对应的超平面上,用h⊥和t⊥表示如下:

- TransH 使不同的实体在不同的关系下拥有了不同的表示形式,但由于实体向量被投影到了关系的语义空间中,故它们具有相同的维度; 缺点:
- 虽然TransH模型使每个实体在不同关系下拥有了不同的表示,它仍然假设实体和关系处于相同的语义空间中,这一定程度上限制了TransH的表示能力。
2.1.3 TransR模型
- TransR模型认为,一个实体是多种属性的综合体,不同关系关注实体的不同属性。
- 不同的关系拥有不同的语义空间。
- 对于每一个关系r,TransR定义投影矩阵Mr,将实体向量从实体空间投影到关系r的子空间,用h⊥和t⊥表示如下:

- 然后使 h ⊥ + r ≈ t ⊥ h⊥+r≈t⊥h ⊥+r ≈t ⊥; 缺点:
- 在同一个关系下:头、尾实体共享相同的投影矩阵。然而,一个关系的头、尾实体的类型或属性可能差异巨大。例如,对于三元组(美国,总统,奥巴马),美国和奥巴马的类型完全不同,一个是国家,一个是人物。
- 从实体空间到关系空间的投影是实体和关系之间的交互过程,因此TransR让投影矩阵仅与关系有关是不合理的。
- 与TransE和TransH相比,TransR由于引入了空间投影,使得TransR模型参数急剧增加,计算复杂度大大提高。
2.1.4 TransD模型
- 给定三元组(h, r, t) , TransD模型设置了2个分别将头实体和尾实体投影到关系空间的投影矩阵Mr1和Mr2。具体定义如下:

- 尾实体用h⊥和t⊥表示如下:

; 2.1.5 TranSparse模型
- TranSparse是通过在投影矩阵上强化稀疏性来简化TransR的工作。它有两个版本:TranSparse (共享)和TranSparse (单独)。
- TranSparse (共享)对每个关系r使用相同的稀疏投影矩阵M r ( t h e t a r ) M_r(theta_r)M r (t h e t a r ) 即:

- TranSparse (单独)对于头实体和尾实体分别使用2个不同的投影矩阵M r 1 ( t h e t a r 1 M_r1(theta_r1 M r 1 (t h e t a r 1)和M r 2 ( t h e t a r 2 ) M_r2(theta_r2)M r 2 (t h e t a r 2 )。

- 这里的t h e t a r theta_r t h e t a r 、t h e t a r 1 theta_r1 t h e t a r 1和t h e t a r 2 theta_r2 t h e t a r 2表示这些投影矩阵的稀疏度。优点:
- TransSparse模型通过引入稀疏投影矩阵,TransSparse模型减少了参数个数。
2.1.6 TransM模型
- 除了允许实体在涉及不同关系时具有不同的嵌入之外,提高TransE模型性能可以从降低h+r≈t的要求研究开始。TransM模型将为每个事实(h,r,t)分配特定的关系权重theta_r。
- 通过对一对多、多对一和多对多分配较小的权重,TransM模型使得t在上述的复杂关系中离h+r更远。
2.1.7 ManifoldE模型
- ManifoldE模型对于每个事实三元组( h , r , t ) (h,r,t)(h ,r ,t )将h + r ≈ t h+r≈t h +r ≈t转换为(h+r-t)的L2范式约等于theta_r的平方。
- ManifoldE把t近似地位于流形体上,即一个以h+r为中心半径为theta_r的超球体,而不是接近h+r的精确点。
2.1.8 TransF模型
- TransF只需要t与h+r位于同一个方向,同时h与t-r也位于同一个方向。
2.1.9 TransA模型
- TransA模型为每个关系r引入一个对称的非负矩阵Mr,并使用自适应马氏距离定义评分函数。
- 通过学习距离度量Mr, TransA在处理复杂关系时更加灵活。问题:
- 评分函数只采用L1或L2距离,灵活性不够。
- 评分函数过于简单,实体和关系向量的每一维等同考虑。解决
- 提出TransA模型,将评分函数中的距离度量改用马氏距离,并为每一维学习不同的权重。示例
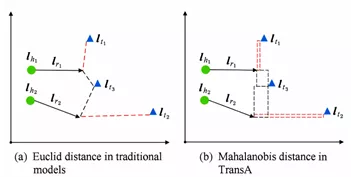
- 如下图所示,( h 1 , r 1 , t 1 ) ( h_1, r_1, t_1)(h 1 ,r 1 ,t 1 )和( h 2 , r 2 , t 2 ) (h_2,r_2,t_2)(h 2 ,r 2 ,t 2 )两个合法的事实三元组,t3是错误的尾实体。如果使用欧氏距离,如图(a)所示,错误的实体t3会被预测出来。而如图(b)所示,TransA模型通过对向量不同维度进行加权,正确的实体由于在x轴或者y轴上距离较近,从而能够被正确预测。
; 2.2 高斯嵌入模型
3 语义匹配模型
- 使用基于相似度的评分函数
博客参考:https://mp.weixin.qq.com/s/6RP3OguFqK8PxfBUz6gu2Q
Original: https://blog.csdn.net/qq_39827677/article/details/109092168
Author: 没有胡子的猫
Title: 知识图谱嵌入(KGE):方法和应用的综述(持续更新)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558034/
转载文章受原作者版权保护。转载请注明原作者出处!