

个人的学习记录,有参考
Abstract
使人类区别于现代基于学习的计算机视觉算法的一个特征是获得关于世界的知识并使用该知识推理关于视觉世界的能力。人类可以了解物体的特征以及它们之间发生的关系,从而学习各种各样的视觉概念,并且可以通过很少的例子学习。本文研究了知识图谱形式的结构化先验知识在图像分类中的应用,表明利用结构化先验知识可以提高图像分类的性能。我们基于最近关于图的端到端学习的工作,引入 Graph Search Neural Network,作为将大知识图谱有效地结合到视觉分类pipeline中的方法。我们在一些实验中表明,我们的方法在多标签分类中优于标准神经网络。
1.Introduction
我们的世界包含人类理解的数百万视觉概念。这些常常是模棱两可的(番茄可以是红色或绿色),重叠的(交通工具包括汽车和飞机),并且有数十或数百个子类别(数千种特定种类的昆虫)。虽然一些视觉概念非常常见,如人或车,但大多数类别的例子较少,形成长尾分布。然而,即使只显示了几个甚至一个例子,人类仍然具有非常显著的能力来高精度地识别这些类别。相比之下,虽然现代的基于学习的方法可以高精度地识别某些类别,但是通常需要为这些类别中的每个类别提供数千个标记的示例。考虑到视觉概念空间大、复杂而且动态,这种为每个概念构建大型数据集的方法是不可扩展的。因此,我们需要寻找目前人类拥有而机器没有的方法。
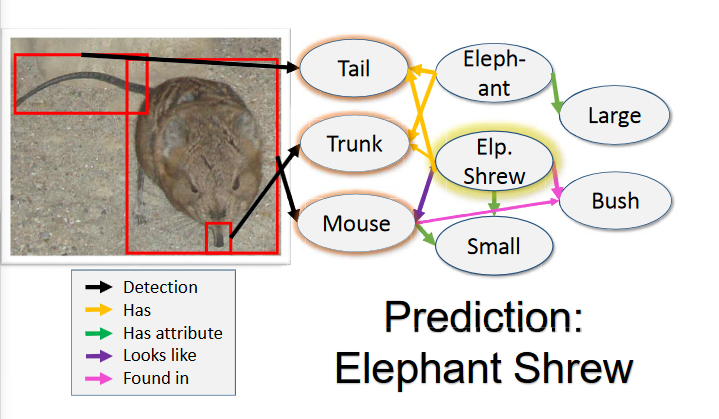
解决方法之一就是构建知识和推理。人类不仅仅是基于外观的分类,我们通过经验和语言获取关于这个世界的知识。在每天的生活中我们都依靠这种知识来分辨物体。礼物,我们或许在一本书中看到过关于”象鼩”(就是图中 的那个像老鼠但是不是老鼠的动物,)(或许仅仅是看来一眼),我们就获得了辨别它的一个能力。图一展示了我们在这个问题中是如何使用我们的知识去判别的。我们可能知道”象鼩”看起来像老鼠,有一个鼻子和尾巴,产于非洲,常见于灌木林。利用这些信息,我们在野外看见它时就能加以辨别。我们一眼就能辨别出来(我们看见一个像老鼠一样的动物,它有鼻子和尾巴),通过回忆知识(思考我们听过的动物和它们的特短板,栖息地)然后推理分析(这是一个”象鼩”因为它有一个鼻子和尾巴,看起来像老鼠,但是老鼠和大象都不会有这些特点)。使用这些信息,即使我们只在图片上看过它一两眼,就能对它进行分辨。
在图上或者神经网络训练的图中,端到端(备注:端到端指输入是原始数据,输出是最终结果)的学习已经有很多工作。大多数方法要么从图中提取特征,要么学习在节点之间传递证据的传播模型,该模型以边缘的类型为条件。一个例子是Gated Graph Neural Network,它以任意的图作为输入。给定特定于任务的一些初始化,它学习如何传播信息并预测图中每个节点的输出。该方法已被证明可以解决基本的逻辑任务和程序验证
我们的工作改进了该模型,并将端到端的图形神经网络应用于多标签图像分类。我们引入图形搜索神经网络(Graph Search Neural Network,GSNN),它利用图像中的特征对图形进行有效的注释,选择输入图的相关子集,并预测表示视觉概念的节点上的输出。然后使用这些输出状态对图像中的对象进行分类。GSNN学习传播模型,该模型推理不同类型的关系和概念,以便在节点上产生输出,然后用于图像分类。我们的新架构减轻了GGNN在大图上的计算问题,这允许我们的模型被有效地训练并用于使用大知识图谱的图像任务。我们展示了我们的模型在推理概念中是如何有效的,以改善图像分类任务。重要的是,我们的GSNN模型还能够通过跟踪信息在图中如何传播来提供关于分类的说明。
这项工作的主要贡献是:(a)引入GSNN,作为将潜在大知识图谱合并到端到端学习系统中的一种方法,该系统在大图的计算上是可行的;(b)使用噪声知识图谱进行图像分类的框架;(c)通过使用传播模型来解释我们的图像分类的能力。我们的方法大大优于多标签分类的baselines。

2 .Realted Work
研究知识图谱并且使用图谱进行图像推理近来已经成为研究图像的热点。为了能够对图像进行分析推理,已经提出来几个方法。例如,参考文献[38]中搜集一个知识库然后要求这个知识库去做做一阶前平衡推理来预测负担。【20】中建立一个不同种类的例子图,使用空间关系去实现上下文的推理。例如【17】中的方法使用在途中随意的走动头学习边缘的模式,当实现走路时,并且在知识图谱中学习新的边缘。还有一些研究使用知识库进行图像检索【12】或是回答视觉查询【39】。但是这些工作都基于建立然后查询知识库,而不是使用已存在的知识库作为边信息去实现一些视觉任务。
然而,这些方法中没有一个是通过端到端的方式进行学习,而且图中的传播模型大多是手绘的。近来,从知识图谱中通过神经网络和其他端到端的学习系统去实现推理已经成为研究的活跃点.一些工作中把图作为卷积输入的一种特殊情况,不同于将帧输入与网格中的帧相联系,输入是图,依赖于要么是一些全局图结构,要么是一些预处理的图边缘2,6,11,25]然而,这些方法中的大多数都输在晓得,干净的诸如分子这样的数据集上训练的。在视觉问题中,这些图编码上下文关系和常识关系,并且明显更大和更嘈杂。
LI和Zemel提出来GGNN【18】在图结构数据上使用神经网络,我们提出的GSNN是基于GGNN。通过变化GNN应用到不同的领域都取得了一些成就。例如化学中的QSPR分析,子图匹配以及其它一些在小数据集上的图像处理。GGNN是一个端到端的网络,他采取直接输入一张图,输出的结果要么是基于整张图的分类,要么是基于每个结点的输出。例如,对于图可达性的问题,GGNN给出了一张图,一个起始节点和终止节点,GGNN将输出是否可以从起点处到达终点,展示了图中逻辑任务的结果,和诸如程序验证这样更复杂的任务
对于对图中定义的不同种类的核也值得研究,诸如字母核,Weisfeiler-Lehman 图核【32】,【27】【26】【1】。挖掘共同的图结构有很多种方法。然而,这些方法都只对基于核的方法诸如SVM这样的方法有用,对图像中的神经网络效果不好。
我们的工作和【8】中的分布方法也相关,例如【16】使用固定的二进制分布去实现zero-shot prediction.他是用种类间的分布去防止在半监督学习下的语义曲解,这种方法自动的探索分布,并且使用它们去获得一个更好的分类。
我们的工作也使用知识图谱中的分布关系,而且使用图中直接的物体与推理,而不是直接使用物体分布。
3. Methodology
3.1 Graph Gated Neural Network
给定N个节点的图,我们希望产生一些输出,这些输出可以是每个图节点
, , … 的输出,也可以是全局输出。这是通过学习一个类似于LSTM的传播模型来实现的。对于图v中的每一个节点,在每一个时间t,都有一个隐状态。从t=0时刻开始,初始隐状态依赖于问题。例如,为了学习图的可达性,隐状态可能是一个二位向量,表明是源节点或者是目标节点。对于视觉知识图谱的推理,可以是一位,表示类别的置信度,基于一个对象检测器或者分类器。
接下来我们使用图结构,编码在矩阵A中,矩阵A用于检索相邻节点的隐藏状态,基于相邻节点之间的边缘类型。然后通过类似于LSTM的门控更新模块来更新隐藏状态。这个传播网络的基本递归是:
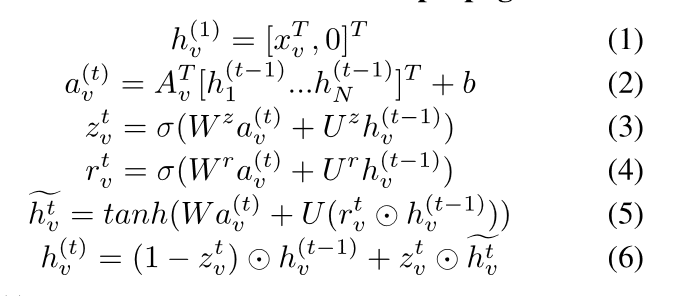
其中
是节点v在时刻t的隐状态,是问题的特定注释,是节点a的图邻接矩阵,W和U是学习参数。等式(1)是具有和空维度的隐状态的初始化,等式(2)展示了来自相邻节点的迭代更新,等式(3-6)结合相邻节点的信息和节点的当前隐藏状态来计算下一个隐藏状态。
T步之后,我们得到了最后一个隐状态。节点级别的输出可以被计算为:

g是一个全连接网络,全连接层是输出层,
是节点的初始注释。
3.2 Graph Search Neural Network
GGNN在图像任务中最大的问题是计算可扩展性。例如,NEIL有2000多个概念,NELL有200多万的confident beliefs。即使我们的任务剪枝之后,这些图表仍然是巨大的。N个节点的标准GGNN,正向传播复杂度是O(
),逆向传播是O(), 其中t是传播次数。我们对合成图上的GGNNs执行简单的实验,发现在大约500个节点之后,即使做出大量的参数假设,一个实例的前向和后向传递会花费1秒钟的时间。在2000个节点上,单个图像需要花费超过一分钟的时间。使用GGNN是不可行的。
我们对这个问题的解决方法是Graph Search Neural Network(GSNN)。顾名思义,我们的想法是,与其同时对图的所有节点执行我们的周期性更新,不如根据我们的输入从一些初始节点开始,并且只选择扩展对最终输出有用的节点。因此,我们只在图的子集进行更新。那么,我们如何选择节点的子集来初始化图呢?在训练和测试期间,我们确定图的初始节点,基于由对象检测器或分类器确定的概念存在的可能性。我们的实验使用更快的R-CNN对于80个COCO类别中的每一个。对于一些选定的阈值的分数,我们选择图中的相应节点作为初始的活节点集合。
一旦确定了初始节点,我们将邻接于初始节点的节点添加到活动集。给定初始节点,我们首先将初始节点的beliefs传播到所有相邻节点(we want to first propagate the beliefs about our initial nodes to all of the adjacent nodes.)。在第一步之后,我们需要一种方法来决定接下来要扩展哪些节点。因此,我们学习了每个节点评分函数,它估计节点是多么重要。在每个传播步骤之后,对于我们当前图中的每个节点,我们预测重要性得分:

其中gi是一个学习网络,即重要性网络。
一旦我们有了
的值,我们将获取得分最高且从未被扩展的前p个节点,将它们添加到扩展集,并将那些节点的所有邻接节点添加到活动集。图二说明了这种扩展。
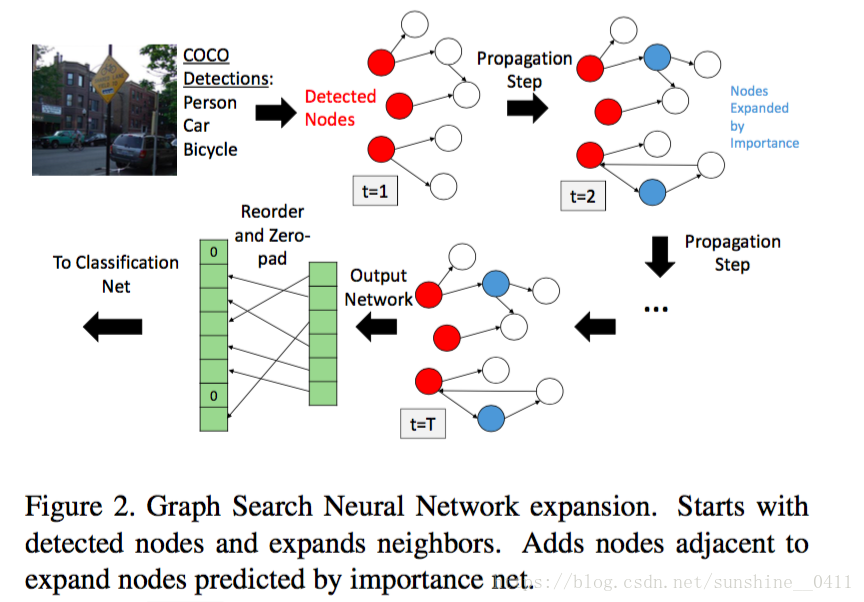
T=1时,仅检测到的节点被扩展。T=2时,我们基于重要性值扩展选择节点,并将它们的邻居添加到图中。在最后一步T,我们计算the per-node-output, the re-order and the zero-pad,输出到最终分类网络。
为了训练重要性网络,我们为给定的图像在图中的每个节点分配重要性值。对应事实概念的节点重要度为1,这些节点的邻居被分配一个γ值。隔一个的节点具有值
γ2(γ的平方)等。 这个想法是最接近最终输出的节点是最重要的扩展。
现在我们有一个端到端网络,它接受一组初始节点和注释作为输入,并且输出图中每个活动节点的输出。它由三个网络组成:传播网络、重要性网络和输出网络。图像问题的最终损失可以反向传播,从pipeline的最终输出,通过输出网络。重要性损失通过每个重要性输出反向传播。Figure3展示了GSNN的架构。
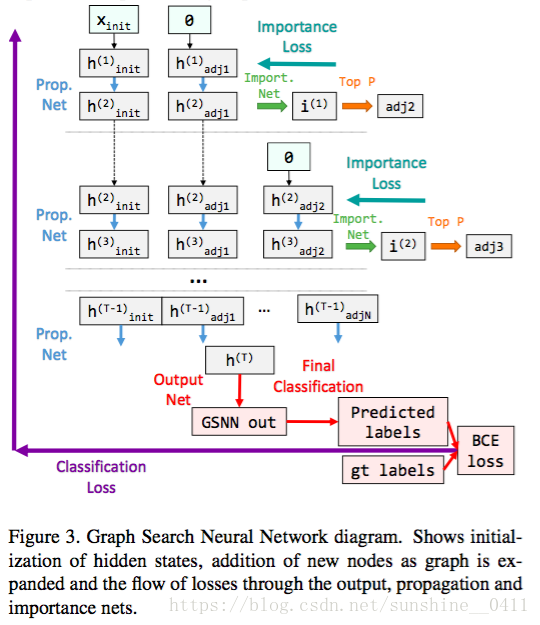
图的解释:
: the detection confidences
: the hidden states of the initially detected nodes, 初始化为
: 初始化邻接结点的隐藏状态
被用来预测重要性得分,重要性得分用来挑选接下来哪些结点被加入adj2中
初始化
=0, 通过传播网络更新隐状态
T步后,我们用所有的累积隐藏状态
来预测所有活动节点的GSNN输出。
在反向传播过程中,二进制交叉熵(BCE)损失通过输出层反向反馈,而重要损失通过重要度网络反馈以更新网络参数。
最后一个细节是将”节点偏置”添加到GSNN中。在GGNN中,每个节点的输出函数g(hv,xv)接受节点v的隐藏状态和初始注释来计算其输出。从某种意义上说,它对节点的意义是不可知的。也就是说,在训练或测试时,GSNN可能获得它从未见过的图表,和每个结点的初始注释xv(or并为每个节点提供一些初始注释xv?)。然后,它使用图的结构通过网络传播这些注释,然后计算输出。图的节点可以表示从人际关系到计算机程序的任何东西。然而,在我们的图网络中,特定节点表示”马”或”猫”的事实可能相关,并且我们还可以将自己约束为图像概念上的静态图。因此,我们引入节点偏置项,对于我们的图中的每个节点,都有一些学习的值。我们的输出方程现在是G(HV,XV,NV),其中NV是与整个图中的特定节点V相联系的偏置项。这个值被存储在一个表中,并且它的值通过反向传播来更新。
3、Image pipeline and baselines
对于视觉问题,我们面临的另一个问题是如何将图形网络合并到image pipeline中。对于分类,这是相当简单的。我们获取图网络的输出,对其进行reorder,以便节点总是以相同的顺序出现在最终网络中,并且zero pad任何未扩展的节点。因此,如果我们有一个具有316个输出节点的图,并且每个节点预测一个5维隐藏变量,那么我们从图中创建一个1580维的特征向量。我们还将这个特征向量和a fine-tuned VGG-16 network的fc7 layer (4096-dim) 和由更快的R-CNN(80-dim)预测的每个COCO类别的最高得分连接起来。这个5676维的特征向量送到一层的最终分类网络中训练。
对于baseline,我们比较了:(1) VGG Baseline – feed just fc7 into final classification net; (2) Detection Baseline – feed fc7 and top COCO scores into final classification net.
4 Results
4.1 Datasets
我们希望实验数据集表达了复杂、有噪声的视觉世界,有许多不同种类的对象,标签可能模糊或重叠,并且是长尾分布。本实验使用Visual Genome dataset v1.0
视觉基因组包含超过100,000个自然图像,每个图像上都有由人标注的物体标签,属性,和其他物体之间的关系。注释者无需使用预定义列表就可以找到图像中的任意物体,所以,数以万计的种类标签更加普遍而且大多都有很多例子。一张图中平均有21个标签,所以针对诸如ImageNet【29】或PASCAL【7】这样的数据集,我们需要考虑的场景会更加复杂。视觉基因组也带有很多物体与物体关系以及物体间属性的标签,我们在GSNN中都有使用。
在我们的实验中,我们通过视觉基因组制作了一个子集,我们称其为VGML,在VGML中,我们采用数据集中200个最常见的物体,100个最常见的属性,还为316个视觉概念添加了不在这300个对象和属性中的任何COCO类别。我们的任务是多标签分类:对于每个图像预测316个总类别中的哪个子集出现在场景中。随机将图片分成80-20训练集/测试集。由于我们使用了来自COCO的预先训练的检测器,所以我们确保没有一个测试图像与我们的检测器的训练图像重叠。
我们还在更标准的COCO数据集上评估我们的方法,以表明我们的方法在多个数据集上有用,并且我们的方法不依赖于专门为我们的数据集构建的图。我们在多标签集中进行训练和测试,并对微型集进行评估。
4.2 Building the Knowledge Graph 构建知识图谱
我们也使用Visual Genome作为我们知识图谱的来源。Using only the train split,(仅用于训练时的分割?) 我们使用数据集中最常见的对象-属性和对象-对象关系来构建连接概念的知识图谱。具体地说,我们计算在训练集中出现对象/对象关系或对象/属性对的频率,并剪掉任何少于200个实例的边。这给我们留下了关于每个边缘是共同关系的图像的图表。我们的想法是,我们会得到非常常见的关系(如草是绿色或人穿衣服),但不是罕见的关系,只出现在单一的图像(如人骑斑马)。
Visual Genome graphs对我们的问题是有用的,因为它们包含对象之间的场景级关系,例如人穿裤子或消防栓是红色的,因此可以推断场景中的内容。然而,它不包含有用的语义关系。例如,如果我们的视觉系统”看到了”一条狗,而我们的标签是动物,如果能知道狗是动物的一种对分类是有帮助的。为了解决这个问题,我们还创建了一个融合了Visual Genome Graphs与WordNet的图。使用[10]中的WordNet子集,我们首先收集WordNet中不在输出标签中的新节点,包括那些直接连接到输出标签并因此可能相关的节点,并将它们添加到组合图中。然后,我们将这些节点之间的所有WordNet边缘添加到组合图形中。
4.3 Training details
我们共同训练pipeline的所有部分(除了detectors)。GSNN使用ADAM【13】,其他所有模型使用SGD。对于fc7之前的VGG网络,我们使用0.05、0.005的初始学习率,每10次减少0.1倍,L2惩罚为1e-6,动量为0.5。。。。设置GSNN的hidden state size为10,γ为0.3,T为3.初始预支为0.5,expand number P wei 5,GSNN 是S型激励的单层网络,我们训练的所有的网络都使用batch size 为16.
4.4 Quantitative Evaluation定量分析
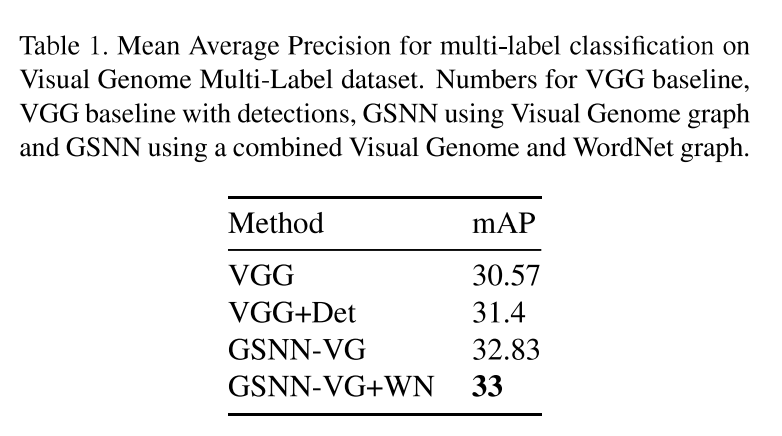
表1中展示了我们的方法对于视觉基因多标签分类的结果,在实验中,combined Visual Genome和WordNet图的效果好于Visual Genome图,这表明从 WordNet中获取的外部语义知识和基于知识图谱实现明确的推理使我们的模型相较其他模型表现得更好。
我们也做了关于训练集大小对效果影响的实验。图4展示了在Visual Genome上的实验结果,将整个训练集范围大小不同的训练集,一直分到500个例子。对于这些实验选择的自给是随机的,但是每个训练集是大集合的子集,例如,1000个集合中的例子都在2000个集合中,我们了解到,直到包含1000个例子的集合时,基于GSNN的方法才优于baseline,在500-1000之间时,所有的方法效果相仿,给定Visual Genome中长尾特征时,似乎对于少于2000个例子时,任何方法都没有足够多的例子去检测很多种类。实验表明我们的方法在少量数据集时依旧能有些提升。
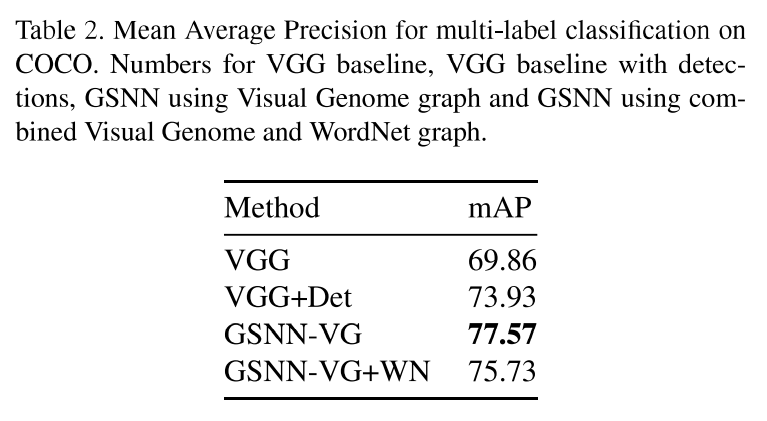
在表2 中,我们显示了在COCO多标签数据集上的效果,能看出,使用知识图谱明显好于使用VisualGenome。原因可能是VisualGenome知识图谱提供了重要信息,促进了在COCO数据集本身上的实现效果。在之前的VisualGenome实验中,大多数图信息包含在标签和图本身之上。另一个有意思的结果是VisualGenome图优于COCO的结合图,尽管他们都优于baseline。原因可能是原始的VGML图较组合图更小,更干净,包含更多的相关信息。此外,在VGML实验中,WordNet对于逻辑分析以增进效果提供了新的补充信息
一个可能的问题是,如果80个COCO检测器和初始检测,Garph推理对集合的过度依赖.因此,我们做了消融实验去研究我们的方法对于所有的初始检测的敏感度。我们重新做了COCO实验,使用两组不同的COCO检测器子集。第一个子集是偶数,第二个是技术。我们从表3中可看出GSNN方法再次优于baselines.
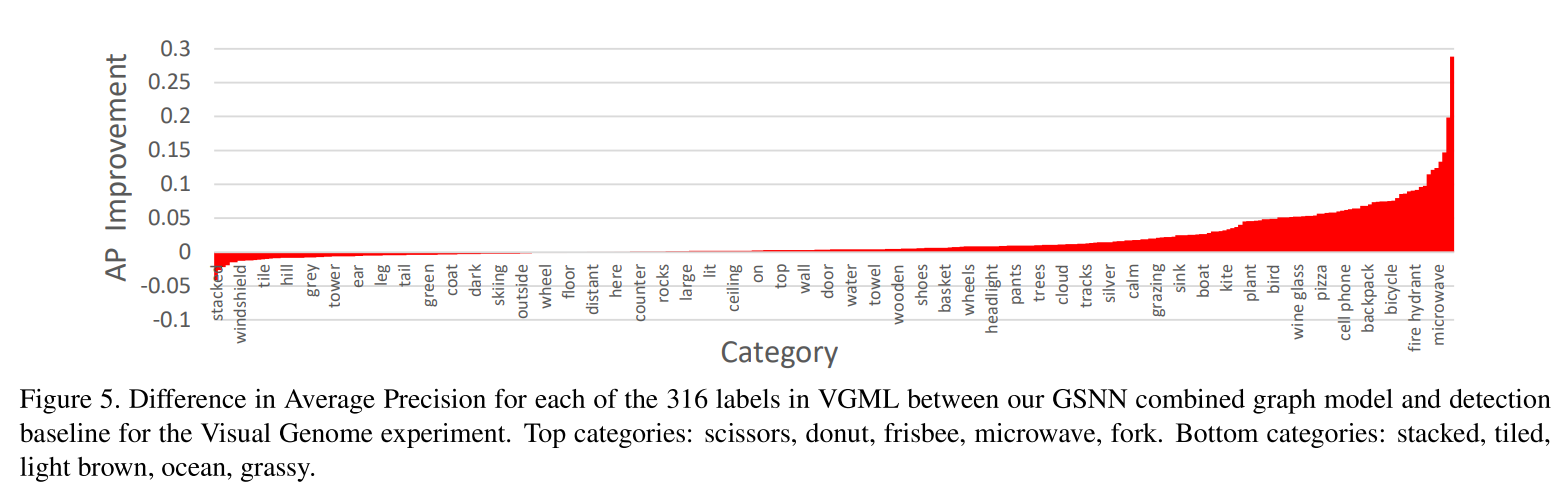
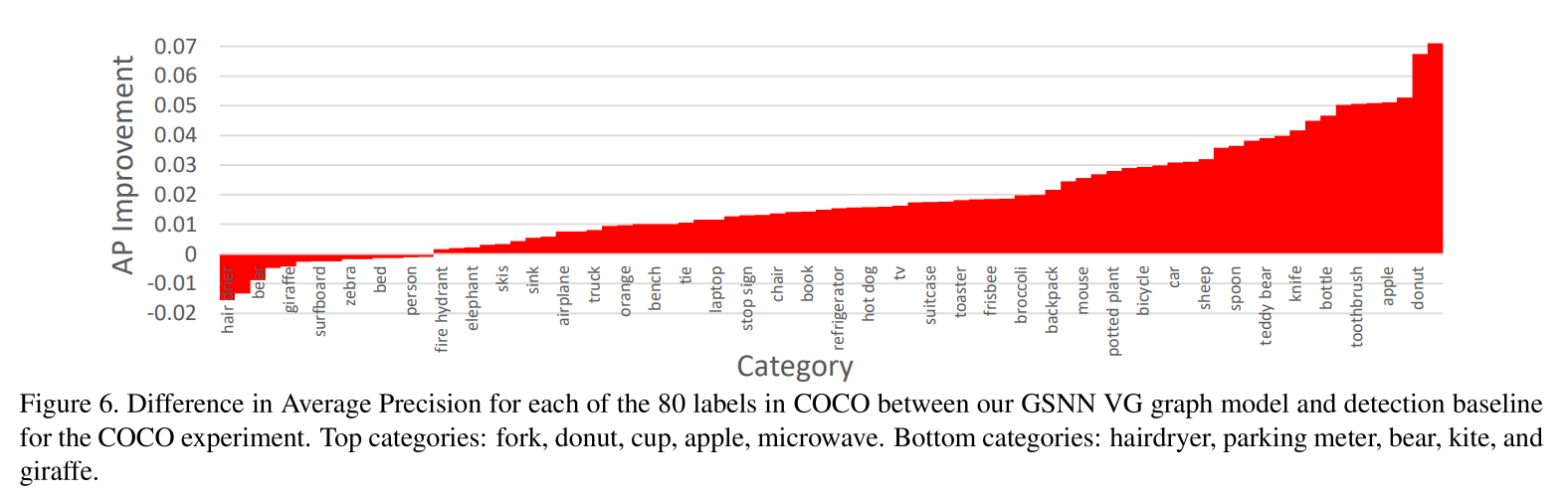
作为一个可能的假设,我们的方法并不对所有的种类都表现的很好,而是对一些种类效果更好一些更糟。图5显示了对于每个种类,在组合图上我们的GSNN模型和检测VGML实验的baseline之间预测的平均差异。图6是在COCO实验上的检测。对于一些类别效果很好,例如在我们的VGML实验中的”fork”检测和基于COCO实验中的”scissors”检测。这些以及一些其他良好的检测效果对于”knife”和”toothbrush”似乎表明图像推理对于图中的小物体的检测尤其有用。在下一节,我们分析GSNN方法在一些例子上的效果,更好的展示GSNN模型是如何工作的,以及为什么它在一些例子中表现好,而在另外一些中表现不好。
4.4 Qualitive Evaluation 质量评估
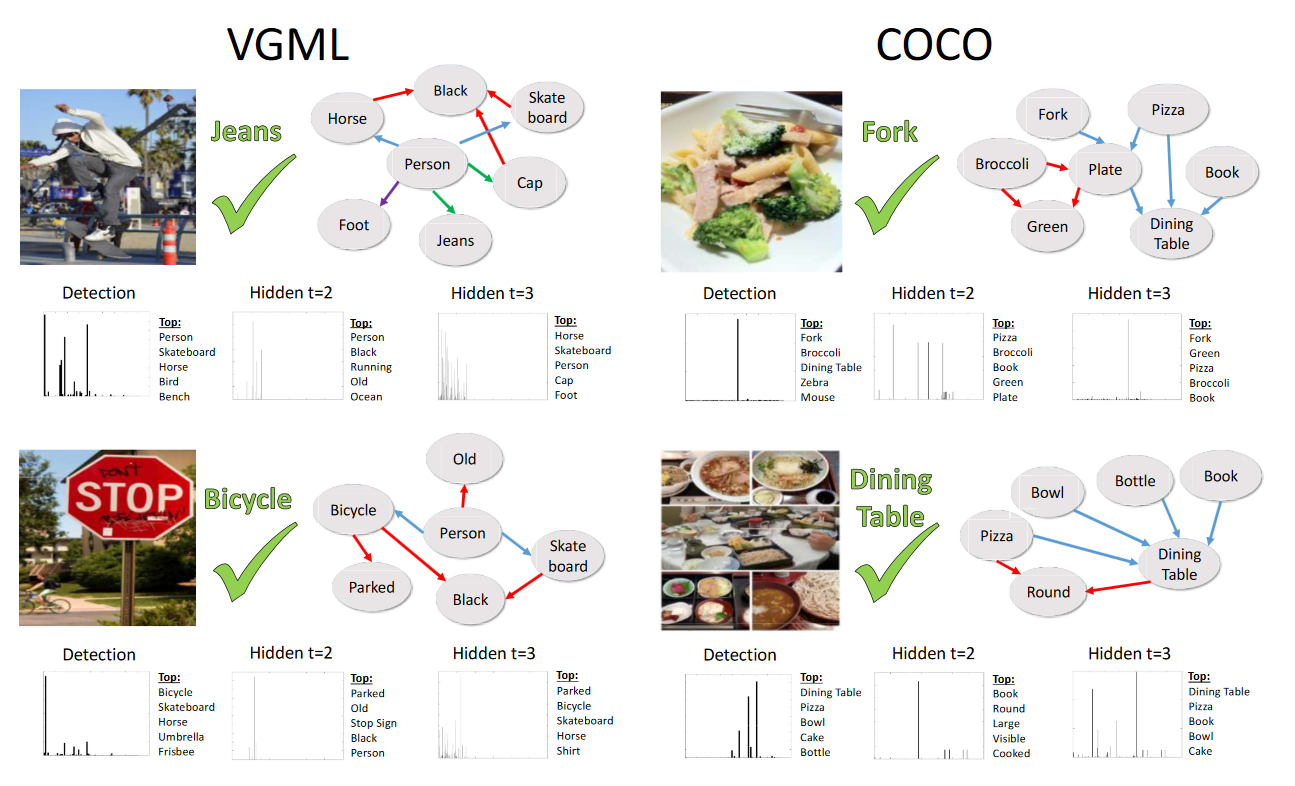
在这一部分,我们展示了对于VGML实验中GSNN组合图模型,和COCO实验中VisualGenome图对于灵敏度的分析。特别的,我们分别检测了一些在GSNN下优于和劣于baseline的种类,以待更好的得知为什么一些种类的效果更好。
图7展示了对于VGML实验和COCO实验的图灵敏度分析,GSNN中4个例子效果更好,2个不好。每个例子都展示了图像,我们分析的潜在事实输出,以及关于图或检测的隐含说明的灵敏度。我们也展示了部分扩展图,去表明GSNN使用的关系。
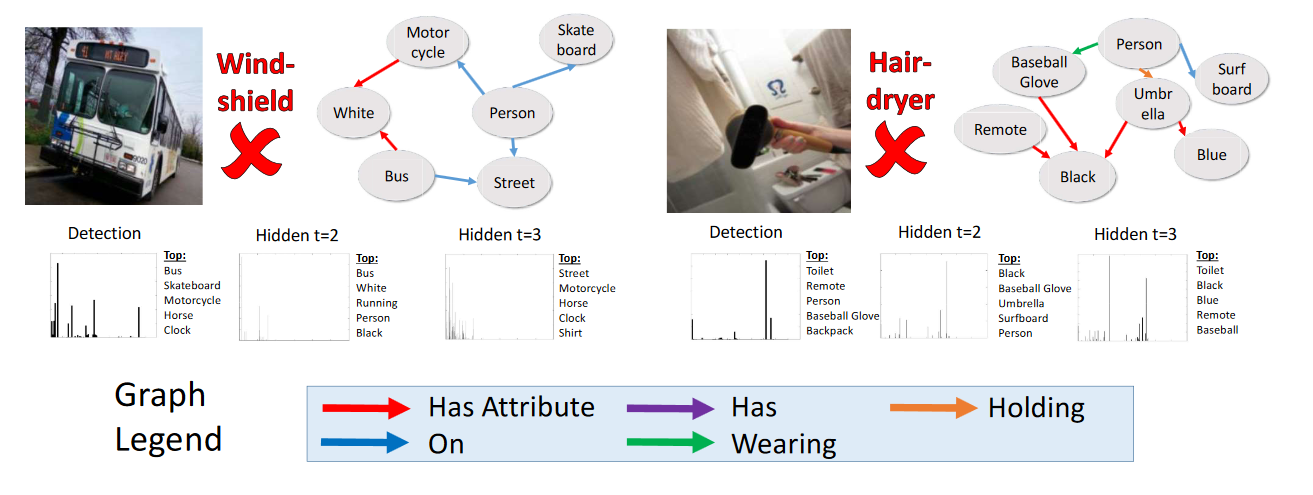
对于VGML实验,图7中在左一对人进行检测,GSNN能够推理出牛仔衣,因为人穿牛仔衣,通过使用”wearing”这个属性边。它对于滑板和马也是敏感的,这些中的每一个都与人牛仔衣有一个二阶联系,所以它抓取了事实,人们通常在骑马或者滑滑板时穿牛仔衣。注意,灵敏度并不和实际的检测目标相一致,这与马拥有高灵敏度并不冲突。左边的第二行展示了一个对于自行车的检测成功例子,使用人和滑板的检测,基于人在自行车或滑板”上”这个事实。最后一行展示了关于挡风玻璃的失败案例,它正确的和公交车相联系,但是因为知识图谱中缺少公交车和挡风玻璃的之间的一个联系,图谱网络不能够展示出比baseline检测更好的效果。在右边,是COCO实验,第一行显示的fork是和检测目标fork高度相关联,这并不惊奇。然后,它能够加强与broccoli和餐桌之间的联系,在图中他们都是与fork的二阶联系。相似的,中间的例子展示了和pizza,bowl,bottle都在dining-table “上”之间的图联系,以此增强了dining table的检测。右下角的图显示了另一个失败案例,能够获取到toilet和hair dryer之间的联系(都是在bathroom里),但是在图中缺少联系,这导致了GSNN的效果不如baseline.

5.Conclusion
在这篇文章中,我们提出了GSNN作为一种有效使用知识图谱作为额外信息去提高图像分类的方法。我们提供了分析,检查通过GSNN的信息流,并提供了为什么我们的模型提高性能的洞察力,希望我们的工作能将符号推理引入传统的前馈计算机视觉框架。
GSNN和我们用来解决图像问题的框架是完全普遍的。我们的下一步是将GSNN应用到其他的视觉任务中,例如探测,视觉问题回答,图像字幕。另一个有趣的方向将是用诸如NEIL这样的系统结合本工作的步骤,构建一个系统,此系统能构建知识图谱,后进行缩减以获得一个可用于图像处理的更加准确,更加实用的图。
致谢:省略
Original: https://blog.csdn.net/qydsb/article/details/111221362
Author: qydsb
Title: The More You Know: Using Knowledge Graphs for Image Classification ——用知识图谱进行图像分类论文
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557649/
转载文章受原作者版权保护。转载请注明原作者出处!