

1.抽取式自动文本摘要
- 本文自动文本摘要实现的依据就是词频统计。
- 文章是由句子组成的,文章的信息都包含在句子中,有些句子包含的信息多,有些句子包含的信息少。
- 句子的信息量用”关键词”来衡量。如果包含的关键词越多,就说明这个句子越重要。
- “自动摘要”就是要找出那些包含信息最多的句子,也就是包含关键字最多的句子。
- 而通过统计句子中关键字的频率的大小,进而进行排序,通过对排序的词频列表对文档中句子逐个进行打分,进而把打分高的句子找出来,就是我们要的摘要。
2.原理
这种方法最早出自The Automatic Creation of Literature Abstracts,其主要原理在于将关键词进行聚类,得到的”簇”表示的就是我们关键词的聚集,最终我们将”簇”认为是关键词的句子片段。
最后我们根据每句话中的关键词的词频来对我们这句话对应于topic的关联程度进行评估。
3.工程实现
3.1.1 数据集展示


; 3.1.2 文本展示
APW19981101.0843 NEWS NEWSWIRE
In Honduras, at least 231 deaths
have been blamed on Mitch, the National Emergency Commission said
Saturday. El Salvador _ where 140 people died in flash floods _
declared a state of emergency Saturday, as did Guatemala, where 21
people died when floods swept away their homes. Mexico reported one
death from Mitch last Monday. In the Caribbean, the U.S. Coast Guard
widened a search for a tourist schooner with 31 people aboard that
hasn’t been heard from since Tuesday. By late Sunday, Mitch’s winds,
once near 180 mph (290 kph), had dropped to near 30 mph (50 kph), and
the storm _ now classified as a tropical depression _ was near
Tapachula, on Mexico’s southern Pacific coast near the Guatemalan
border. Mitch was moving west at 8 mph (13 kph) and was dissipating
but threatened to strengthen again if it moved back out to sea.
3.2 数据预处理
3.2.1 词干化
- 词干化:是抽取词的词干或词根形式(不一定能够表达完整语义)
- 原理:词干提取主要是采用”缩减”的方法,将词转换为词干,如将”cats”处理为”cat”,将”effective”处理为”effect”。
- 实现方法:词干提取的实现方法主要利用规则变化进行词缀的去除和缩减,从而达到词的简化效果。
- 缺陷:词干提取的结果可能并不是完整的、具有意义的词,而只是词的一部分,如”revival”词干提取的结果为”reviv”,”ailiner”词干提取的结果为”airlin”
- 改进:作者拟使用 词还原(lemmatization)来代替词干化。
3.2.2 停用词
- 构建停用词列表:作者使用的是通过计算文档频率DF来判定一个词是否为停用词,如果一个词在文档集中出现的频率太高,那么可以认为这种词不会具有太大的表征意义,可以过滤。而对于过于低频的,也可以酌情丢掉。
- 停用词剔除:在文本匹配过程中,以单词为元,进行元对库,如果该元存在于停用词库中,则进行剔除。
3.2.3 句子切分
- 正则表达式:
‘(?
- 效果:将按照之前两步(停用词剔除和词干化)处理之后的文章,按照”.”、”?”、”!” 将句子切分,并剔除句子内部的所有标点符号。
3.2.4 数据预处理Python实现
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import nltk
from nltk.stem.porter import PorterStemmer
def stop_words(inpsen, mode='test'):
if mode == 'test':
example_sent = "This is a sample sentence, showing off the stop words filtration."
else :
example_sent = inpsen
stop_words = set(stopwords.words('english'))
word_tokens = word_tokenize(example_sent)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
return filtered_sentence
def word_porter(inpsen, mode='test'):
porter_stemmer = PorterStemmer()
if mode == 'test':
word_data = "It originated from the idea that there are readers who prefer learning new skills from the comforts of their drawing rooms"
else :
word_data = inpsen
nltk_tokens = nltk.word_tokenize(word_data)
res = [porter_stemmer.stem(w) for w in nltk_tokens]
return res
def Txt2Sent(text, mode='punctuation'):
sent, sentlist = '', []
for alpha in text :
if alpha in ['.', '?', '!'] :
if mode == 'punctuation' :
sent += alpha
sentlist.append(sent)
sent = ''
else :
sent += alpha
return sentlist
def list2str(lis):
res = ''
for w in lis :
res += (w + ' ')
return res
class datapremain():
def DataPreMain(self, text, mode='train'):
if mode == 'train':
ported_word = word_porter(text, mode='using')
ported_str = list2str(ported_word)
final = stop_words(ported_str, mode='using')
final_str = list2str(final)
sent_lis = Txt2Sent(final_str)
else :
sent_lis = Txt2Sent(text, mode='punctuation')
return sent_lis
3.3 Sent2Vec
3.3.1TF-IDF



Python实现:
def tf_idf(target_word, target_text):
tf, idf = 0, 0
target_str = ''
for sent in target_text :
target_str += (sent)
target_text = target_str.split(' ')
for word in target_text :
if word == target_word :
tf += 1
tf /= len(target_text)
for text in dox :
text = text.split(' ')
if target_word in text :
idf += 1
idf = np.log(len(doc) / (idf + 1))
return tf * idf
3.3.2 Sent2Vec
- 构建一个矩阵,矩阵的每一行表示一个句子(预处理过的),矩阵的每一个元素表示的是当前单词的Tf-Idf值。
- Python实现:
def Sent2Vec():
doc_mat = np.zeros((len(doc), 55))
row = -1
for text in docs :
for sent in text :
row += 1
for num, word in enumerate(sent.split(' ')):
doc_mat[row][num] = tf_idf(word, text)
return doc_mat
3.4 句子之间的相似度计算
- 余弦相似度:余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
- 计算公式

- Python实现:
def counter_cosine_similarity(c1, c2):
if not c2:
c2.append('hhh')
c1 = Counter(c1)
c2 = Counter(c2)
terms = set(c1).union(c2)
dotprod = sum(c1.get(k, 0) * c2.get(k, 0) for k in terms)
magA = math.sqrt(sum(c1.get(k, 0)**2 for k in terms))
magB = math.sqrt(sum(c2.get(k, 0)**2 for k in terms))
result = dotprod / (magA * magB)
final = cosine_similarity_backprocess(result)
return final
3.5 相似度聚类
3.5.1 K-Means

class KMEans(object):
def __init__(self):
super(KMEans, self).__init__()
self.features, self.label = np.array([]), np.array([])
self.centroids_index, self.centroids = np.array([]), np.array([])
self.distance_sum, self.label_validation, self.clusters, self.acc_list = [], [], [], []
def read_data(self, path):
df = pd.read_csv(path)
columns_name = df.columns.values
self.features = np.zeros((len(df[columns_name[0]].values), len(columns_name[:-1])))
self.label = np.zeros(len(df[columns_name[0]].values))
self.label_validation = np.zeros_like(self.label)
for feature in range(self.features.shape[0]):
for elem in range(self.features.shape[1]):
self.features[feature][elem] = np.float32(df[columns_name[elem]].values[feature])
if elem == self.features.shape[1]-1:
self.label[feature] = df[columns_name[elem + 1]].values[feature]
self.label_validation[feature] = np.int(self.label[feature])
return(self.features, range(1, len(self.label) + 1))
def calculate_distance(self, p1, p2):
dis = 0
for elem in range(self.features.shape[1]):
dis += np.square(np.int(p1[elem]) - np.int(p2[elem]))
return np.sqrt(dis)
def gen_init_centroids(self, K):
self.centroids = np.zeros((K, self.features.shape[1]))
self.centroids_index = np.random.randint(low=1, high=self.features.shape[0], size=K)
for i in range(len(self.centroids_index)):
self.centroids[i] = self.features[self.centroids_index[i]]
def fit_model(self, K):
self.gen_init_centroids(K)
epoches = 10
self.acc_list = []
self.distance_sum = []
for epoch in range(epoches):
self.distance_sum.append(0)
print('test')
self.clusters = [[] for x in range(K)]
for elem in range(self.features.shape[0]):
dis_list = []
for centorid in self.centroids:
dis_list.append(self.calculate_distance(centorid, self.features[elem]))
self.label[elem] = dis_list.index(min(dis_list))
self.distance_sum[-1] += min(dis_list)
self.clusters[int(self.label[elem])].append(elem)
clusters_mean = np.zeros((K, self.features.shape[1]))
for k in range(K):
sum = [[0] for i in range(self.features.shape[1])]
for f in range(self.features.shape[1]):
for p in self.clusters[k]:
sum[f] += self.features[p][f]
for f in range(len(sum)):
clusters_mean[k][f] = (sum[f][0]) / len(self.clusters[k])
self.centroids[k] = clusters_mean[k]
self.acc_list.append(self.encode_loss(K))
return self.clusters
3.6 Rouge评测
- Rouge评测
ROUGE是由ISI的Lin和Hovy提出的一种自动摘要评价方法,现被广泛应用于DUC1(Document Understanding Conference)的摘要评测任务中。
ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。ROUGE准则由一系列的评价方法组成,包括ROUGE-1,ROUGE-2,ROUGE-3,ROUGE-4,以及ROUGE-Skipped-N-gram等,1、2、3、4分别代表基于1元词到4元词以有跳跃的N-gram模型。在自动文摘相关研究中,一般根据自己的具体研究内容选择合适的N元语法ROUGE方法。 - 计算公式:
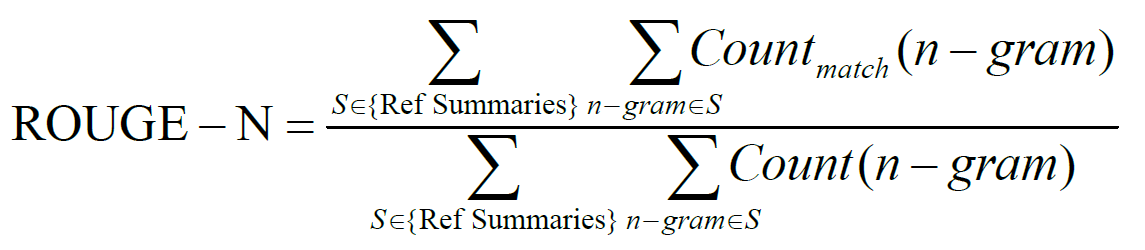
不难看出,ROUGE公式是由召回率的计算公式演变而来的,分子可以看作”检出的相关文档数目”,即系统生成摘要与标准摘要相匹配的N-gram个数,分母可以看作”相关文档数目”,即标准摘要中所有的N-gram个数。 - Python 实现:
def rouge(a, b):
rouge = Rouge()
rouge_score = rouge.get_scores(a, b, avg=True)
rouge_score1 = rouge.get_scores(a, b)
r1 = rouge_score["rouge-1"]
r2 = rouge_score["rouge-2"]
rl = rouge_score["rouge-l"]
return r1, r2, rl
4. 摘要生成
4.1 Baseline
- 根据一个topic的10个文章中,每一篇文章的第一句话组成摘要。
- 结果展示:
Honduras braced for potential catastrophe Tuesday as Hurricane Mitch
roared through the northwest Caribbean, churning up high waves and
intense rain that sent coastal residents scurrying for safer ground.
Hurricane Mitch paused in its whirl through the western Caribbean
on Wednesday to punish Honduras with 120-mph (205-kph) winds, topping
trees, sweeping away bridges, flooding neighborhoods and killing at
least 32 people.
Hurricane Mitch cut through the Honduran coast like a ripsaw Thursday,
its devastating winds whirling for a third day through resort islands
and mainland communities.
At least 231 people have been confirmed dead in Honduras from former-hurricane
Mitch, bringing the storm’s death toll in the region to 357, the National
Emergency Commission said Saturday.
In Honduras, at least 231 deaths have been blamed on Mitch, the National
Emergency Commission said Saturday.
Nicaraguan Vice President Enrique Bolanos said Sunday night that between
1,000 and 1,500 people were buried in a 32-square mile (82.
BRUSSELS, Belgium (AP) – The European Union on Tuesday approved 6.
Pope John Paul II appealed for aid Wednesday for the Central American
countries stricken by hurricane Mitch and said he feels close to the
thousands who are suffering.
Better information from Honduras’ ravaged countryside enabled officials
to lower the confirmed death toll from Hurricane Mitch from 7,000
to about 6,100 on Thursday, but leaders insisted the need for help
was growing.
Aid workers struggled Friday to reach survivors of Hurricane Mitch,
who are in danger of dying from starvation and disease in the wake
of the storm that officials estimate killed more than 10,000 people.
- Rouge 评测:
Average-RAverage-PAverage-FRouge-10.52293577981651370.220077220077220080.30978260452637646Rouge-20.30555555555555560.127906976744186050.18032786469228712Rouge-L0.45882352941176470.22543352601156070.3023255769770447
- Python实现:
def baseline(self, file, mode='BaseLine'):
abstract = ''
with open(file, 'r') as f:
data = f.readlines()
txt = ''
for row in data[5:-2]:
txt += row
for alpha in txt:
if alpha != '\n':
abstract += alpha
if alpha == '.' and mode == 'BaseLine':
break
return abstract
def baselineMain():
abstracts = ''
self.text = []
for text in self.PathList:
abstracts += self.baseline(path + '\\' + text, mode='BaseLine')
self.text.append(self.baseline(path + '\\' + text, mode='BaseLine'))
self.abstracts = abstracts
return abstracts, self.text
4.2 句子关联度排序摘要生成
- 算法流程:
- 停用词、词干化、句子切分、TF-IDF预处理;
- Topic中的10个文章,看为一个长句子;
- 切分好的短句子和长句子进行余弦相似度计算;
- 每一个短句子按照相似度进行排序;
- 第一次选定关联度最高的句子放入摘要;
- 之后按照关联度排序,选取关联度最高的句子和现有摘要进行关联度比对;
- 人工阈值设定:规定包含第1330(665 * 2)个单词的句子之前的所有句子与长句子的余弦相似度平均值作为关联阈值;
- 当此目前关联度最高的句子和现有摘要的余弦相似度大于阈值时,将此句子放入摘要;
- 当摘要字数达到665个单词的时候结束。
- 结果展示:
Nicaragua’s leftist Sandinistas, who maintained close relations
with Fidel Castro during their 1979-90 rule, had criticized the refusal by
President Arnoldo Aleman’s administration. Nicaraguan
leaders previously had refused Cuba’s offer of medical
help, saying it did not have the means to transport or support the doctors. Nicaragua
said Friday it will accept Cuba’s offer to send doctors as long as the communist
nation flies them in on its own helicopters and with their own supplies.‘s a coincidence that the ships
are there but they’ve got men and equipment that can
be put to work in an organized way,” said International Development Secretary Clare.
- Rouge评测:
Average-RAverage-PAverage-FRouge-10.429357798165137630.338095238095238080.43364485481483108Rouge-20.037253826387263620.058163895381835180.07692639273826712Rouge-L0.3529411764705885250.351162790697767440.352046778862590216
- Python实现:
def rank(sentmat, orignal, orignal_doc):
result = ''
rank_dict = {}
for num, sent in enumerate(sentmat):
rank_dict[num] = counter_cosine_similarity(sent, orignal)
values_list = list(rank_dict.values())
keys_list = list(rank_dict.keys())
for i in range(len(values_list)) :
for j in range(i, len(values_list)):
if values_list[i] values_list[j] :
mid, midloc = values_list[i], keys_list[i]
values_list[i], keys_list[i] = values_list[j], keys_list[j]
values_list[j], keys_list[j] = mid, midloc
i = 0
while len(result) 665 :
result += orignal_doc[keys_list[i]]
i += 1
return result
def main():
global aa, doc, docs, dox, orignal_str
path_list = os.listdir(root_path)
for i in range(len(path_list)):
path_list[i] = root_path + '\\' + path_list[i]
for path in path_list:
pre_abstract = aa.baseline(file=path, mode='using')
doc.append(pre_abstract.replace('\n', ' '))
dox = doc
docs, orignal_list = datapre()
doc = []
orignal_doc = []
orignal_str = ''
for sent in dox :
orignal_str += sent
for i in docs:
doc += i
for i in orignal_list:
orignal_doc += i
sentmat = Word2Num()
result = rank(sentmat, orignal_str, orignal_doc)
num = 0
flag = 0
for alpha in result :
print(alpha, end='')
num += 1
if num >= 25:
flag = 1
if num >= 25 and flag == 1 and alpha == ' ':
print('\n')
num, flag = 0, 0
return rouge(result, str3)
4.3 利用K-Means聚类后进行关联度排序摘要
- 算法流程:
- 停用词、词干化、句子切分、TF-IDF预处理;
- 将切分后的句子使用K-Means聚类,聚类数量为17;
- 将每一个簇看为一个句子;
- 计算各个簇内的短句子和簇句子的余弦相似度;
- 计算每一个簇句子和整个Topic的余弦相似度;
- 从余弦相似度最高的簇逐次降低,依次选取每一个簇中余弦相似度最高的短句子组成摘要;
- 当摘要词数达到665时停止。
- 结果展示
In Washington on Thursday, President Bill Clinton ordered dlrs 30
million in Defense Department equipment and services and dlrs 36
million in food, fuel and other aid be sent to Honduras, Nicaragua,
El Salvador and Guatemala.At least 231 people have been confirmed dead
in Honduras from former-hurricane Mitch, bringing the storm’s death
toll in the region to 357, the National Emergency Commission said
Saturday. About 100 victims had been buried around Tegucigalpa, Mayor
Nahum Valladeres said. Until now, we have had a short amount of
time and few resources to get reliable information. Former U. It also
kicked up huge waves that pounded seaside communities. Hillary Rodham
Clinton also will travel to the region, visiting Nicaragua and
Honduras on Nov. We’re trying to move food as fast as possible to
help people as soon as possible,” Rowe said. commitment to
providing humanitarian relief. Mexico reported one death from Mitch
last Monday.The county is semi-destroyed and awaits the maximum
effort and most fervent and constant work of every one of its
children,” he said. The hurricane has destroyed almost
everything,” said Mike Brown, a resident of Guanaja Island which was
within miles (kms) of the eye of the hurricane.” The entire coast of
Honduras was under a hurricane warning and up to 15 inches (38
centimeters) of rain was forecast in mountain areas. The latest EU aid
follows an initial 400,000 ecu (dlrs 480,000).
- Rouge评测:
Average-RAverage-PAverage-FRouge-10.37614678899082570.173728813559322040.23768115509783663Rouge-20.0174927070557346460.012765957446808510.027777777777777776Rouge-L0.211764705882352940.104651162790697680.14007781658465698
- Python实现:
def cal_simi_in(clus, clusent, data):
clus_simi_in = {}
for key in clus.keys():
if key not in clus_simi_in.keys():
clus_simi_in[key] = []
for sent in clus[key] :
clus_simi_in[key].append({sent: counter_cosine_similarity(data[sent], clusent[key])})
maxi = []
locy = ['在聚类中的位置信息', '在data中的位置信息', '最大值']
locs = []
for key in clus_simi_in.keys():
maxi.append(0)
for elem in clus_simi_in[key] :
if list(elem.values())[0] >= maxi[-1]:
maxi[-1] = list(elem.values())[0]
locy = [key, list(elem.keys())[0], maxi[-1]]
locs.append(locy)
return locs
def cal_simi_out(clusent):
doc_data = []
simi_out = {}
for sent in doc :
for word in sent.split(' '):
doc_data.append(tf_idf(word, doc))
for key in clusent.keys():
if key not in simi_out.keys():
simi_out[key] = []
simi_out[key] = counter_cosine_similarity(clusent[key], doc_data)
return simi_out
def rank(simi_in, simi_out, orignal_doc):
result = ''
max_clu, max_sent = [0, 'key'], [0, 'key', 'loc in mat']
keys_list = list(simi_out.keys())
for i in range(len(keys_list)) :
for j in range(i, len(keys_list)):
if keys_list[i] keys_list[j] :
mid = keys_list[i]
keys_list[i] = keys_list[j]
keys_list[j] = mid
for i in keys_list:
for elem in simi_in:
if elem[0] == i:
result += orignal_doc[elem[1]]
print(result)
return result
def main():
global aa, doc, docs, dox
path_list = os.listdir(root_path)
for i in range(len(path_list)):
path_list[i] = root_path + '\\' + path_list[i]
for path in path_list:
pre_abstract = aa.baseline(file=path, mode='fuck')
doc.append(pre_abstract.replace('\n', ' '))
dox = doc
docs, orignal_list = datapre()
doc = []
orignal_doc = []
orignal_str = ''
for sent in dox :
orignal_str += sent
for i in docs:
doc += i
for i in orignal_list:
orignal_doc += i
sentmat = Word2Num()
clus, clusent = clustering(sentmat, np.sqrt(sentmat.shape[0]))
simi_in = cal_simi_in(clus, clusent, sentmat)
simi_out = cal_simi_out(clusent)
result = rank(simi_in, simi_out, orignal_doc)
print(result)
return rouge(result, str3)
5. 在工程搭建时的问题及解决办法
- [1 ] 数据集的问题,部分符号不规范,且有分行符合,只能通过对字符串按字符进行操作,去除分行符;
- [2] 在改进方法2中的阈值选取的时候,开始是按精度为1e-3取得前1330个单词的句子对于Topic的众数,但是众数就存在相似度句子堆积问题,导致在特征空间上相似度较大的句子和摘要相似度较小,后来换为平均值,可以有效解决此问题;
- [3] 在改进方法1中,使用TF-IDF构建矩阵 向量集时,存在句子长短不一,导致每一个维度的长度不确定,在K-Means中,对于数据集的要求是特征数量需要相同,因此我们构建出的向量集无法直接使用K-Means,但因为对NLP方向的Trick了解的不多,只是觉得对于一个句子来讲,其特征之间应该存在一些关联性,因此对于较短的句子的补齐采用类似于CNN的零Padding。
Original: https://blog.csdn.net/weixin_43702410/article/details/111031615
Author: 涂漾图森魄
Title: 多文档的抽取式自动文本摘要
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557549/
转载文章受原作者版权保护。转载请注明原作者出处!