

NLP实验六:stanford Parser中文分词
- 一、实验内容
- 二、实验前准备
* - 2.1下载安装前需要配置好电脑的JDK
- 2.2可视化工具
- 三、实验内容
* - 1.安装配置Stanford Parser
- 2. 自拟文字内容,实现中文分词、词性标注、命名实体识别与句法分析。
- 3. 使用Stanford Parser可视化工具,自己选择模型,进行中文句法分析。
–
一、实验内容
使用stanford Parser进行中文分词、命名实体识别与句法分析。
学习使用stanford Parser工具包,通过可视化界面和API调用两种方式进行中文信息处理。
二、实验前准备
2.1下载安装前需要配置好电脑的JDK
1.安装 pip install stanfordcorenlp
2.下载需要的资源 下载模型及文件:wget http://nlp.stanford.edu/software/stanford-corenlp-full-2018-10-05.zip 下载中文jar包:链接:https://pan.baidu.com/s/1dNpwG9fkhkwa73RbJcPhpA 提取码:3hfl
3.解压stanford-corenlp-full-2018-10-05.zip,并将stanford-chinese-corenlp-2018-10-05-models.jar,放入文件夹中
说明几点: 1.stanford-corenlp-full-2018-10-05文件夹下需要stanford-chinese-corenlp-2018-10-05-models.jar,代码才可以跑中文文本 2.如果在使用中提示找不到包,检查一下数据包的名称和路径是否正确。
2.2可视化工具
可视化工具使用 Stanford Parser是由StanforsNLP Group开发的基于Java的开源NLP工具,支持中文的语法分析,下载地址为:http://nlp.stanford.edu/software/lex-parser.shtml。 下载后解压。
解压文件中lexparser-gui.bat进行可视化页面运行,解析需要的模型文件存放在stanford-parser-3.3.0-models.jar,可以对其 解压。在中文处理方面,提供的模型文件有chineseFactored.ser.gz、chinesePCFG.ser.gz、xinhuaFactored.ser.gz、xinhuaFactoredSegmenting.ser.gz、xinhuaPCFG.ser.gz。
factored包含词汇化信息,PCFG是更快更小的模板,xinhua据说是根据大陆的《新华日报》训练的语料,而chinese同时包含香港和台湾的语料,xinhuaFactoredSegmenting.ser.gz可以对未分词的句子进行句法解析。
三、实验内容
1.安装配置Stanford Parser
解压stanford-corenlp-full-2018-10-05.zip,并将stanford-chinese-corenlp-2018-10-05-models.jar,放入文件夹中。
分词与词性标注
调用方法: nlp.word_tokenize(s)、nlp.pos_tag(s)
s为待处理的字符串
命名实体识别 调用函数:ner = nlp.ner(s) 能够识别多种ner,包括:FACILITY、ORGANIZATION、NUMBER
from stanfordcorenlp import StanfordCoreNLP
path = r'F:\wyt\stanford-corenlp-full-2018-10-05'
nlp = StanfordCoreNLP(path, lang='zh')
s = '''同学们每天都很努力'''
token = nlp.word_tokenize(s)
postag = nlp.pos_tag(s)
ner = nlp.ner(s)
parse = nlp.parse(s)
dependencyParse = nlp.dependency_parse(s)
print (' '.join(token))
print ('|'.join([','.join(i) for i in postag]))
print ('|'.join([','.join(i) for i in ner]))
print (parse)
同学们 每天 都 很 努力
同学们,NN|每天,AD|都,AD|很,AD|努力,VA
同学们,O|每天,O|都,O|很,O|努力,O
(ROOT
(IP
(NP (NN 同学们))
(VP
(ADVP (AD 每天))
(ADVP (AD 都))
(ADVP (AD 很))
(VP (VA 努力)))))
运行速度超级慢 耐心等待…(等到半个小时还没跑完,换了台电脑一分钟跑完了。。。)
2. 自拟文字内容,实现中文分词、词性标注、命名实体识别与句法分析。
测试
对一段句子进行分词(word_tokenize)、词性标注(pos_tag)、命名实体识别(ner)、
句法解析(parse)、句法依存分析(dependency_parse)。
from stanfordcorenlp import StanfordCoreNLP
path = r'F:\wyt\stanford-corenlp-full-2018-10-05'
nlp = StanfordCoreNLP(path, lang='zh')
sentence = '美国财政部将中国列为"汇率操纵国"。'
print ('Tokenize:', nlp.word_tokenize(sentence))
print ('Part of Speech:', nlp.pos_tag(sentence))
print ('Named Entities:', nlp.ner(sentence))
print ('Constituency Parsing:', nlp.parse(sentence))
print ('Dependency Parsing:', nlp.dependency_parse(sentence))
nlp.close()
Tokenize: ['美国', '财政部', '将', '中国', '列为', '“', '汇率', '操纵', '国', '”', '。']
Part of Speech: [('美国', 'NR'), ('财政部', 'NN'), ('将', 'BA'), ('中国', 'NR'), ('列为', 'VV'), ('“', 'PU'), ('汇率', 'NN'), ('操纵', 'VV'), ('国', 'NN'), ('”', 'PU'), ('。', 'PU')]
Named Entities: [('美国', 'ORGANIZATION'), ('财政部', 'ORGANIZATION'), ('将', 'O'), ('中国', 'COUNTRY'), ('列为', 'O'), ('“', 'O'), ('汇率', 'O'), ('操纵', 'O'), ('国', 'O'), ('”', 'O'), ('。', 'O')]
Constituency Parsing: (ROOT
(IP
(IP
(NP
(NP (NR 美国))
(NP (NN 财政部)))
(VP (BA 将)
(IP
(NP (NR 中国))
(VP (VV 列为)
(IP (PU “)
(NP (NN 汇率))
(VP (VV 操纵)
(NP (NN 国)))
(PU ”))))))
(PU 。)))
Dependency Parsing: [('ROOT', 0, 5), ('nmod:assmod', 2, 1), ('nsubj', 5, 2), ('aux:ba', 5, 3), ('dep', 5, 4), ('punct', 8, 6), ('nsubj', 8, 7), ('ccomp', 5, 8), ('dobj', 8, 9), ('punct', 8, 10), ('punct', 5, 11)]
3. 使用Stanford Parser可视化工具,自己选择模型,进行中文句法分析。
句法分析 调用函数:nlp.parse(s) 使用: 提取chunk,也即短语、词组之类的;如NP(名词短语) 两个词之间的距离,也即一个树的两个叶子节点之间的路径
from nltk.parse import stanford
import os
import jieba
if __name__ == '__main__':
string = '他骑自行车去了菜市场。'
seg_list = jieba.cut(string, cut_all=False, HMM=True)
seg_str = ' '.join(seg_list)
print(seg_str)
parser_path = r'D:\Desktop\大三上\自然语言处理\6\stanford-parser-4.2.0\stanford-parser-full-2020-11-17/stanford-parser.jar'
model_path = r'D:\Desktop\大三上\自然语言处理\6\stanford-parser-4.2.0\stanford-parser-full-2020-11-17/stanford-parser-4.2.0-models.jar'
pcfg_path = r'D:\Desktop\大三上\自然语言处理\6\stanford-parser-4.2.0\stanford-parser-full-2020-11-17\stanford-parser-4.2.0-models\edu\stanford\nlp\models\lexparser/chinesePCFG.ser.gz'
parser = stanford.StanfordParser(
path_to_jar=parser_path,
path_to_models_jar=model_path,
model_path=pcfg_path
)
sentence = parser.raw_parse(seg_str)
for line in sentence:
print(line.leaves())
line.draw()
他 骑 自行车 去 了 菜市场 。
C:\Users\15488\anaconda3\lib\site-packages\ipykernel_launcher.py:23: DeprecationWarning: The StanfordParser will be deprecated
Please use [91mnltk.parse.corenlp.CoreNLPParser[0m instead.
['他', '骑', '自行车', '去', '了', '菜市场', '。']
4. 《Python自然语言处理》阅读第六章p242性别鉴定例子,完成p244题目。
自己从名字中拟定特征完成分类器训练、测试和精度评价。
def gender_features(word):
return {'last_letter': word[-1]}
gender_features('Shrek')
from nltk.corpus import names
import nltk
import random
names_set = ([(name, 'male') for name in names.words('male.txt')] +
[(name, 'female') for name in names.words('female.txt')])
print (names_set[:10])
random.shuffle(names_set)
print (names_set[:10])
[('Aamir', 'male'), ('Aaron', 'male'), ('Abbey', 'male'), ('Abbie', 'male'), ('Abbot', 'male'), ('Abbott', 'male'), ('Abby', 'male'), ('Abdel', 'male'), ('Abdul', 'male'), ('Abdulkarim', 'male')]
[('Thurston', 'male'), ('Keri', 'female'), ('Kassi', 'female'), ('Bradley', 'male'), ('Michale', 'male'), ('Gail', 'male'), ('Nelsen', 'male'), ('Tootsie', 'female'), ('Barry', 'female'), ('Cathee', 'female')]
featuresets = [(gender_features(n), g) for (n,g) in names_set]
train_set, test_set = featuresets[500:], featuresets[:500]
classifier = nltk.NaiveBayesClassifier.train(train_set)
classifier.classify(gender_features('Neo'))
'male'
classifier.classify(gender_features('Trinity'))
'female'
print (nltk.classify.accuracy(classifier, test_set))
0.784
names = nltk.corpus.names
print(names.fileids())
male_names = names.words('male.txt')
female_names = names.words('female.txt')
print([ w for w in male_names if w in female_names ])
['female.txt', 'male.txt']
['Abbey', 'Abbie', 'Abby', 'Addie', 'Adrian', 'Adrien', 'Ajay', 'Alex', 'Alexis', 'Alfie', 'Ali', 'Alix', 'Allie', 'Allyn', 'Andie', 'Andrea', 'Andy', 'Angel', 'Angie', 'Ariel', 'Ashley', 'Aubrey', 'Augustine', 'Austin', 'Averil', 'Barrie', 'Barry', 'Beau', 'Bennie', 'Benny', 'Bernie', 'Bert', 'Bertie', 'Bill', 'Billie', 'Billy', 'Blair', 'Blake', 'Bo', 'Bobbie', 'Bobby', 'Brandy', 'Brett', 'Britt', 'Brook', 'Brooke', 'Brooks', 'Bryn', 'Cal', 'Cam', 'Cammy', 'Carey', 'Carlie', 'Carlin', 'Carmine', 'Carroll', 'Cary', 'Caryl', 'Casey', 'Cass', 'Cat', 'Cecil', 'Chad', 'Chris', 'Chrissy', 'Christian', 'Christie', 'Christy', 'Clair', 'Claire', 'Clare', 'Claude', 'Clem', 'Clemmie', 'Cody', 'Connie', 'Constantine', 'Corey', 'Corrie', 'Cory', 'Courtney', 'Cris', 'Daffy', 'Dale', 'Dallas', 'Dana', 'Dani', 'Daniel', 'Dannie', 'Danny', 'Darby', 'Darcy', 'Darryl', 'Daryl', 'Deane', 'Del', 'Dell', 'Demetris', 'Dennie', 'Denny', 'Devin', 'Devon', 'Dion', 'Dionis', 'Dominique', 'Donnie', 'Donny', 'Dorian', 'Dory', 'Drew', 'Eddie', 'Eddy', 'Edie', 'Elisha', 'Emmy', 'Erin', 'Esme', 'Evelyn', 'Felice', 'Fran', 'Francis', 'Frank', 'Frankie', 'Franky', 'Fred', 'Freddie', 'Freddy', 'Gabriel', 'Gabriell', 'Gail', 'Gale', 'Gay', 'Gayle', 'Gene', 'George', 'Georgia', 'Georgie', 'Geri', 'Germaine', 'Gerri', 'Gerry', 'Gill', 'Ginger', 'Glen', 'Glenn', 'Grace', 'Gretchen', 'Gus', 'Haleigh', 'Haley', 'Hannibal', 'Harley', 'Hazel', 'Heath', 'Henrie', 'Hilary', 'Hillary', 'Holly', 'Ike', 'Ikey', 'Ira', 'Isa', 'Isador', 'Isadore', 'Jackie', 'Jaime', 'Jamie', 'Jan', 'Jean', 'Jere', 'Jermaine', 'Jerrie', 'Jerry', 'Jess', 'Jesse', 'Jessie', 'Jo', 'Jodi', 'Jodie', 'Jody', 'Joey', 'Jordan', 'Juanita', 'Jude', 'Judith', 'Judy', 'Julie', 'Justin', 'Karel', 'Kellen', 'Kelley', 'Kelly', 'Kelsey', 'Kerry', 'Kim', 'Kip', 'Kirby', 'Kit', 'Kris', 'Kyle', 'Lane', 'Lanny', 'Lauren', 'Laurie', 'Lee', 'Leigh', 'Leland', 'Lesley', 'Leslie', 'Lin', 'Lind', 'Lindsay', 'Lindsey', 'Lindy', 'Lonnie', 'Loren', 'Lorne', 'Lorrie', 'Lou', 'Luce', 'Lyn', 'Lynn', 'Maddie', 'Maddy', 'Marietta', 'Marion', 'Marlo', 'Martie', 'Marty', 'Mattie', 'Matty', 'Maurise', 'Max', 'Maxie', 'Mead', 'Meade', 'Mel', 'Meredith', 'Merle', 'Merrill', 'Merry', 'Meryl', 'Michal', 'Michel', 'Michele', 'Mickie', 'Micky', 'Millicent', 'Morgan', 'Morlee', 'Muffin', 'Nat', 'Nichole', 'Nickie', 'Nicky', 'Niki', 'Nikki', 'Noel', 'Ollie', 'Page', 'Paige', 'Pat', 'Patrice', 'Patsy', 'Pattie', 'Patty', 'Pen', 'Pennie', 'Penny', 'Perry', 'Phil', 'Pooh', 'Quentin', 'Quinn', 'Randi', 'Randie', 'Randy', 'Ray', 'Regan', 'Reggie', 'Rene', 'Rey', 'Ricki', 'Rickie', 'Ricky', 'Rikki', 'Robbie', 'Robin', 'Ronnie', 'Ronny', 'Rory', 'Ruby', 'Sal', 'Sam', 'Sammy', 'Sandy', 'Sascha', 'Sasha', 'Saundra', 'Sayre', 'Scotty', 'Sean', 'Shaine', 'Shane', 'Shannon', 'Shaun', 'Shawn', 'Shay', 'Shayne', 'Shea', 'Shelby', 'Shell', 'Shelley', 'Sibyl', 'Simone', 'Sonnie', 'Sonny', 'Stacy', 'Sunny', 'Sydney', 'Tabbie', 'Tabby', 'Tallie', 'Tally', 'Tammie', 'Tammy', 'Tate', 'Ted', 'Teddie', 'Teddy', 'Terri', 'Terry', 'Theo', 'Tim', 'Timmie', 'Timmy', 'Tobe', 'Tobie', 'Toby', 'Tommie', 'Tommy', 'Tony', 'Torey', 'Trace', 'Tracey', 'Tracie', 'Tracy', 'Val', 'Vale', 'Valentine', 'Van', 'Vin', 'Vinnie', 'Vinny', 'Virgie', 'Wallie', 'Wallis', 'Wally', 'Whitney', 'Willi', 'Willie', 'Willy', 'Winnie', 'Winny', 'Wynn']
书上:
一般来说,以字母 a 结尾的名字都是女性名字。所以我们可以提取最后一个字母 name[-1],则:
cfd = nltk.ConditionalFreqDist((fileid,name[-1]) for fileid in names.fileids() for name in names.words(fileid))
cfd.plot()
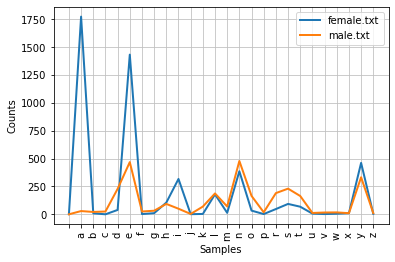

<axessubplot:xlabel='samples', ylabel="Counts">
</axessubplot:xlabel='samples',>
可以由此图看到,大多数名字以 a,e,i 结尾的名字是女性,以 k,o,r,s 和 t 结尾的更可能是男性。以 h,l 结尾的男女差不多。
那我们这里就建立一个分类器来更精确的模拟这些差异。
创建一个分类器的第一步是决定输入的什么样的 特征 是能相关的,以及如何为那些特征 编码 。
在这个例子中,我们一开始只是寻找一个给定的名称的最后一个字母。
以下 特征提取器 函数建立了一个字典,包含有关给定名称的相关信息:
def gender_features(word):
return {'last_letter':word[-1]}
print(gender_features('Shark'))
{'last_letter': 'k'}
这个函数返回的字典被称为 特征集 ,映射特征名称到他们的值。
特征名称是简单类型的值,如布尔,数字和字符串。
现在我们已经建立了一个特征提取器,我们需要准备一个例子和一个对应类标签的链表:
from nltk.corpus import names
import random
names = ([(name,'male') for name in names.words('male.txt')]
+[(name,'female') for name in names.words('female.txt')])
random.shuffle(names)
接下来,我们使用特征提取器处理名称数据,并划分特征集的结果链表为一个 训练集 和一个 测试集。
训练集用于训练一个新的”朴素贝叶斯”分类器。
featuresets = [(gender_features(n),g) for (n,g) in names]
train_set , test_set = featuresets[500:],featuresets[:500]
下面测试下没有出现在训练数据中的名字:
classiffier = nltk.NaiveBayesClassifier.train(train_set)
print(classiffier.classify(gender_features('Neo')))
print(classiffier.classify(gender_features('Trinity')))
male
female
那我们可以使用大数据量来系统的评估这个分类器:
print(nltk.classify.accuracy(classiffier,test_set))
0.758
最后我们可以检查分类器,确定哪些特征对于区分名字的性别是最有效的。
print(classiffier.show_most_informative_features(10))
Most Informative Features
last_letter = 'a' female : male = 34.6 : 1.0
last_letter = 'k' male : female = 30.7 : 1.0
last_letter = 'f' male : female = 15.2 : 1.0
last_letter = 'p' male : female = 11.2 : 1.0
last_letter = 'v' male : female = 11.2 : 1.0
last_letter = 'd' male : female = 9.6 : 1.0
last_letter = 'o' male : female = 8.7 : 1.0
last_letter = 'm' male : female = 8.5 : 1.0
last_letter = 'r' male : female = 6.6 : 1.0
last_letter = 'g' male : female = 5.4 : 1.0
None
通过输出结果可以看到,训练集中以 ‘a’ 结尾的名字中女性是男性的 34 倍,而以 ‘k’ 结尾名字中男性是女性的30倍。
这些比率叫做 似然比,可以用于比较不同特征-结果关系。
实验:
修改gender_features()函数,为分类器提供名称的长度、它的第一个字母以及任何其他看起来可能有用的特征。
再用这些新特征训练分类器,并测试其准确性。
names = nltk.corpus.names
print(names.fileids())
male_names = names.words('male.txt')
female_names = names.words('female.txt')
print([ w for w in male_names if w in female_names ])
['female.txt', 'male.txt']
['Abbey', 'Abbie', 'Abby', 'Addie', 'Adrian', 'Adrien', 'Ajay', 'Alex', 'Alexis', 'Alfie', 'Ali', 'Alix', 'Allie', 'Allyn', 'Andie', 'Andrea', 'Andy', 'Angel', 'Angie', 'Ariel', 'Ashley', 'Aubrey', 'Augustine', 'Austin', 'Averil', 'Barrie', 'Barry', 'Beau', 'Bennie', 'Benny', 'Bernie', 'Bert', 'Bertie', 'Bill', 'Billie', 'Billy', 'Blair', 'Blake', 'Bo', 'Bobbie', 'Bobby', 'Brandy', 'Brett', 'Britt', 'Brook', 'Brooke', 'Brooks', 'Bryn', 'Cal', 'Cam', 'Cammy', 'Carey', 'Carlie', 'Carlin', 'Carmine', 'Carroll', 'Cary', 'Caryl', 'Casey', 'Cass', 'Cat', 'Cecil', 'Chad', 'Chris', 'Chrissy', 'Christian', 'Christie', 'Christy', 'Clair', 'Claire', 'Clare', 'Claude', 'Clem', 'Clemmie', 'Cody', 'Connie', 'Constantine', 'Corey', 'Corrie', 'Cory', 'Courtney', 'Cris', 'Daffy', 'Dale', 'Dallas', 'Dana', 'Dani', 'Daniel', 'Dannie', 'Danny', 'Darby', 'Darcy', 'Darryl', 'Daryl', 'Deane', 'Del', 'Dell', 'Demetris', 'Dennie', 'Denny', 'Devin', 'Devon', 'Dion', 'Dionis', 'Dominique', 'Donnie', 'Donny', 'Dorian', 'Dory', 'Drew', 'Eddie', 'Eddy', 'Edie', 'Elisha', 'Emmy', 'Erin', 'Esme', 'Evelyn', 'Felice', 'Fran', 'Francis', 'Frank', 'Frankie', 'Franky', 'Fred', 'Freddie', 'Freddy', 'Gabriel', 'Gabriell', 'Gail', 'Gale', 'Gay', 'Gayle', 'Gene', 'George', 'Georgia', 'Georgie', 'Geri', 'Germaine', 'Gerri', 'Gerry', 'Gill', 'Ginger', 'Glen', 'Glenn', 'Grace', 'Gretchen', 'Gus', 'Haleigh', 'Haley', 'Hannibal', 'Harley', 'Hazel', 'Heath', 'Henrie', 'Hilary', 'Hillary', 'Holly', 'Ike', 'Ikey', 'Ira', 'Isa', 'Isador', 'Isadore', 'Jackie', 'Jaime', 'Jamie', 'Jan', 'Jean', 'Jere', 'Jermaine', 'Jerrie', 'Jerry', 'Jess', 'Jesse', 'Jessie', 'Jo', 'Jodi', 'Jodie', 'Jody', 'Joey', 'Jordan', 'Juanita', 'Jude', 'Judith', 'Judy', 'Julie', 'Justin', 'Karel', 'Kellen', 'Kelley', 'Kelly', 'Kelsey', 'Kerry', 'Kim', 'Kip', 'Kirby', 'Kit', 'Kris', 'Kyle', 'Lane', 'Lanny', 'Lauren', 'Laurie', 'Lee', 'Leigh', 'Leland', 'Lesley', 'Leslie', 'Lin', 'Lind', 'Lindsay', 'Lindsey', 'Lindy', 'Lonnie', 'Loren', 'Lorne', 'Lorrie', 'Lou', 'Luce', 'Lyn', 'Lynn', 'Maddie', 'Maddy', 'Marietta', 'Marion', 'Marlo', 'Martie', 'Marty', 'Mattie', 'Matty', 'Maurise', 'Max', 'Maxie', 'Mead', 'Meade', 'Mel', 'Meredith', 'Merle', 'Merrill', 'Merry', 'Meryl', 'Michal', 'Michel', 'Michele', 'Mickie', 'Micky', 'Millicent', 'Morgan', 'Morlee', 'Muffin', 'Nat', 'Nichole', 'Nickie', 'Nicky', 'Niki', 'Nikki', 'Noel', 'Ollie', 'Page', 'Paige', 'Pat', 'Patrice', 'Patsy', 'Pattie', 'Patty', 'Pen', 'Pennie', 'Penny', 'Perry', 'Phil', 'Pooh', 'Quentin', 'Quinn', 'Randi', 'Randie', 'Randy', 'Ray', 'Regan', 'Reggie', 'Rene', 'Rey', 'Ricki', 'Rickie', 'Ricky', 'Rikki', 'Robbie', 'Robin', 'Ronnie', 'Ronny', 'Rory', 'Ruby', 'Sal', 'Sam', 'Sammy', 'Sandy', 'Sascha', 'Sasha', 'Saundra', 'Sayre', 'Scotty', 'Sean', 'Shaine', 'Shane', 'Shannon', 'Shaun', 'Shawn', 'Shay', 'Shayne', 'Shea', 'Shelby', 'Shell', 'Shelley', 'Sibyl', 'Simone', 'Sonnie', 'Sonny', 'Stacy', 'Sunny', 'Sydney', 'Tabbie', 'Tabby', 'Tallie', 'Tally', 'Tammie', 'Tammy', 'Tate', 'Ted', 'Teddie', 'Teddy', 'Terri', 'Terry', 'Theo', 'Tim', 'Timmie', 'Timmy', 'Tobe', 'Tobie', 'Toby', 'Tommie', 'Tommy', 'Tony', 'Torey', 'Trace', 'Tracey', 'Tracie', 'Tracy', 'Val', 'Vale', 'Valentine', 'Van', 'Vin', 'Vinnie', 'Vinny', 'Virgie', 'Wallie', 'Wallis', 'Wally', 'Whitney', 'Willi', 'Willie', 'Willy', 'Winnie', 'Winny', 'Wynn']
cfd = nltk.ConditionalFreqDist((fileid,name[-2]) for fileid in names.fileids() for name in names.words(fileid))
cfd.plot()
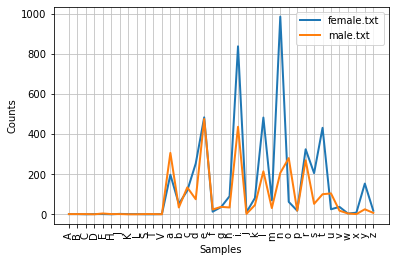
<axessubplot:xlabel='samples', ylabel="Counts">
</axessubplot:xlabel='samples',>
倒数第二个字母是n的女孩子更多
cfd = nltk.ConditionalFreqDist((fileid,name[0]) for fileid in names.fileids() for name in names.words(fileid))
cfd.plot()
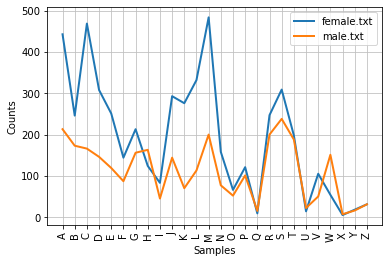
<axessubplot:xlabel='samples', ylabel="Counts">
</axessubplot:xlabel='samples',>
第一个字母c,k,l,m的女孩子更多
cfd = nltk.ConditionalFreqDist((fileid,name[1]) for fileid in names.fileids() for name in names.words(fileid))
cfd.plot()
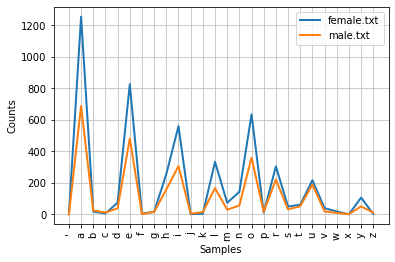
<axessubplot:xlabel='samples', ylabel="Counts">
</axessubplot:xlabel='samples',>
第二个字母类似
{'last_letter': 'k', 'first_letter': 'S'}
from nltk.corpus import namesimport randomnames = ([(name,'male') for name in names.words('male.txt')] +[(name,'female') for name in names.words('female.txt')])random.shuffle(names)
malemale
0.792
大于第一个特征提取器的0.758哦!效果得到了提升
Original: https://blog.csdn.net/wtyuong/article/details/121760427
Author: 是Yu欸
Title: NLP6:stanford Parser中文分词
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557541/
转载文章受原作者版权保护。转载请注明原作者出处!