



; 1. 摘要
- 无监督的关系抽取,存在两大问题:噪声标签、训练数据不平衡
- 以往:研究集中在减少错误标签的关系(假阳性),很少研究由于知识库的不完备性导致的缺失关系(假阴性)
-
本文的贡献:
– 首先对负面数据进行分析
– 接下来,将关系抽取表述为一个正的无标签学习任务,缓解假阴性问题
– 提出模型RERE进行关系检测,然后进行subject和object提取 -
问题分析
关系级别假阴性:抽取到的关系,在预定义的关系集中不存在
实体级别假阴性:S4、S5表示实体级别假阴性

阶级分布不平衡:负标签的数量远远大于正面标签的数量
; 2.1 解决假阴性问题
由百度百科标记的NYT数据集中的三元组为88253,由Wikidata标记的为58135。可以看到,由于知识库的不完备性,只用一个KB来标记,就会存在大量的FN,特别是当多个关系出现在一句中时,即使是人工标注。
2.2解决负面标签
采用先抽取关系,再抽取主体和客体的范式
3.模型
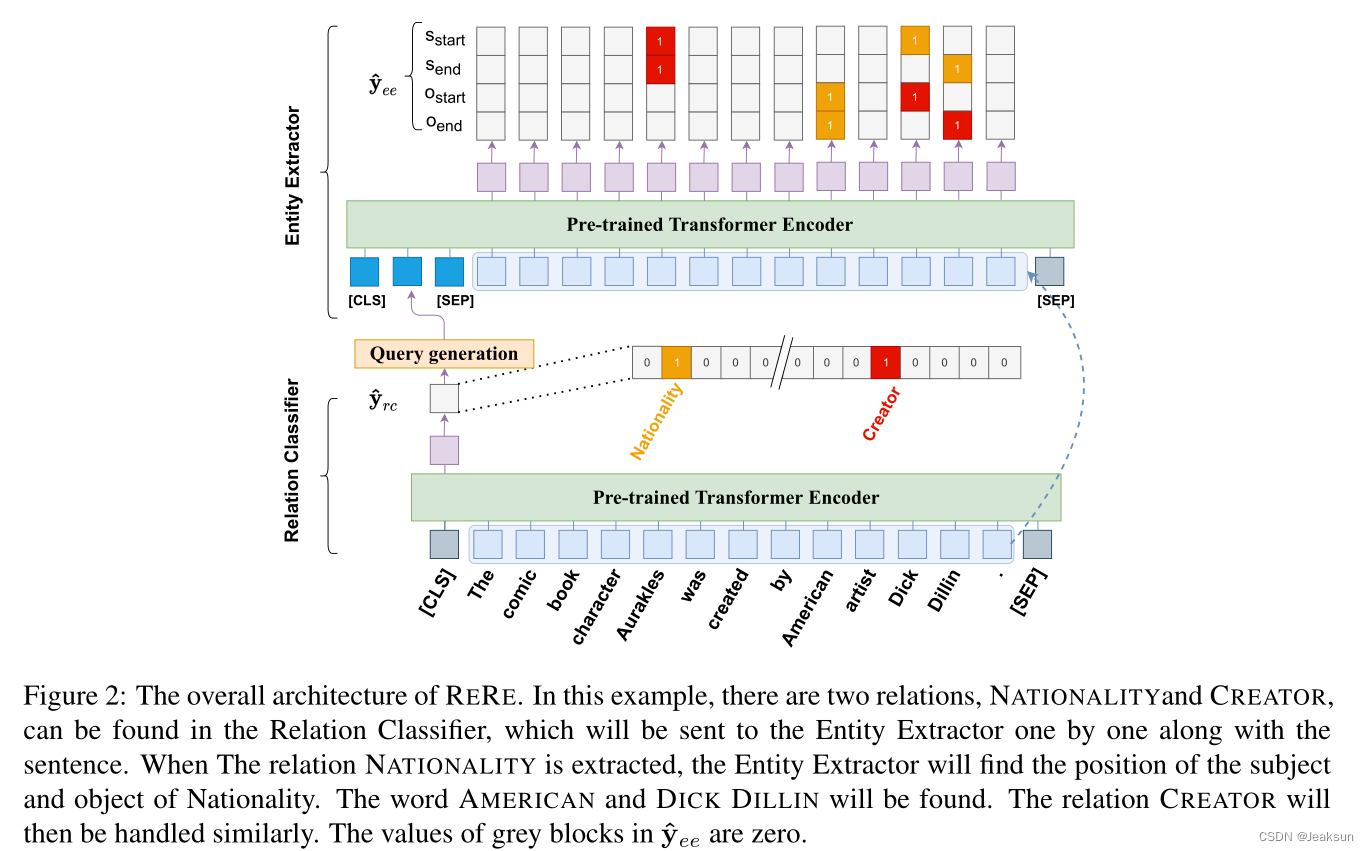
- 输入:[CLS],c i c_i c i ,[SEP]
- 经过BERT生成token表示矩阵:H r c ∈ R N × d H_{rc} \in R^{N \times d}H r c ∈R N ×d
- 将BERT输出的第一个token [CLS] 的编码向量h r c 0 h_{rc}^{0}h r c 0 作为句子表示,关系分类的最终输出为:y r c = σ W h r c 0 + b y_{rc}= \sigma{Wh^0_{rc}+b}y r c =σW h r c 0 +b
- 取关系分类的输出y r c y_{rc}y r c (onehot),使用每个检测到的关系(y r c y_{rc}y r c 中1的个数)来生成query
- 构造MRC格式:[CLS],q i q_i q i ,[SEP],c i c_i c i ,[SEP]
- 将上述输入到BERT中,得到token表示矩阵H e e ∈ R N × d H_{ee} \in R^{N\times d}H e e ∈R N ×d
- 实体抽取的第K个输出指针由y e e k = σ W H e e + b y_{ee}^k=\sigma{WH_{ee}+b}y e e k =σW H e e +b
; 4. Experiments
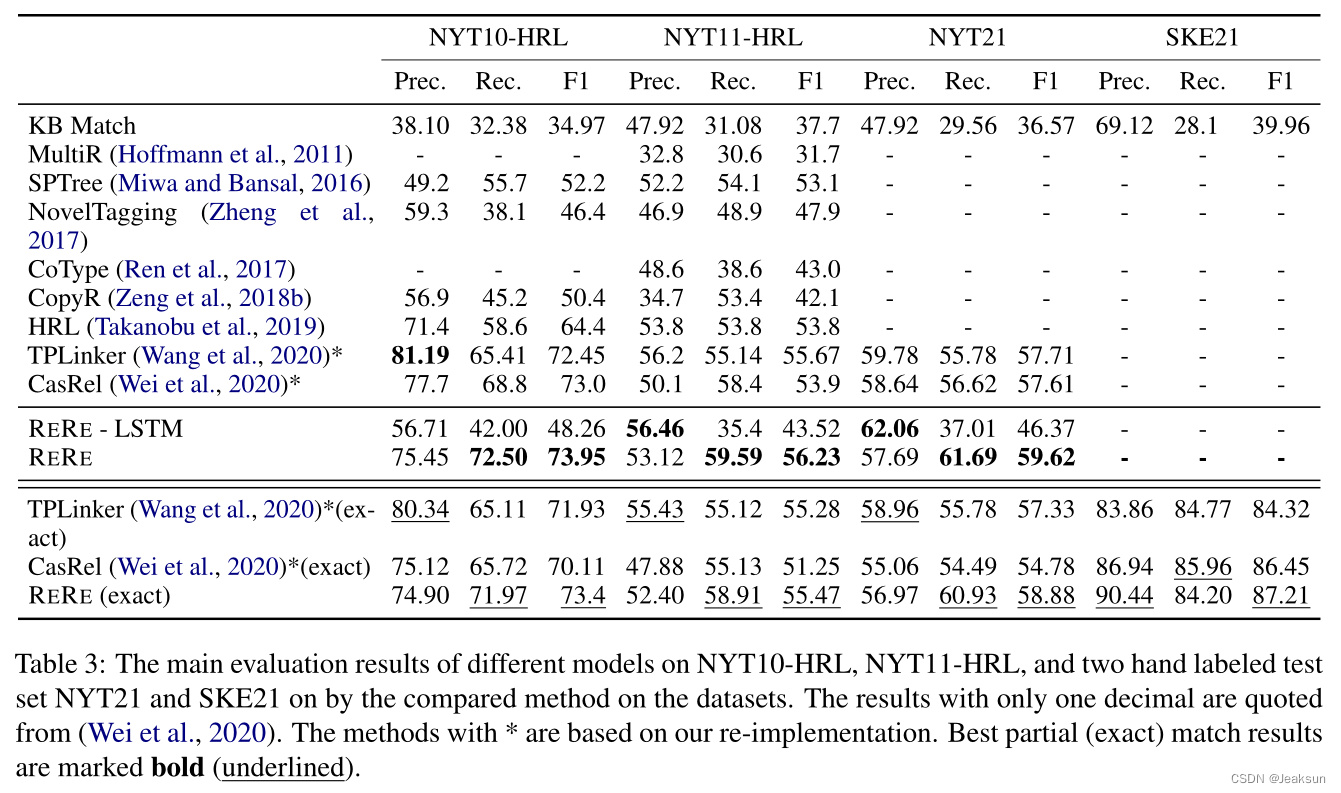
-
启示
-
先抽取关系再抽取实体的范式,可以应用到监督领域
- 可以对模型进一步提取特征
- 增加两者之间的关联性
Original: https://blog.csdn.net/Jeaksun/article/details/124544720
Author: 自然语言处理CS
Title: Revisiting the Negative Data of Distantly Supervised Relation Extraction重温远程监督关系抽取中的负数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557496/
转载文章受原作者版权保护。转载请注明原作者出处!