

参考
https://blog.csdn.net/pelhans/category_7607589.html
知识图谱的定义
“A knowledge graph consists of a set of interconnected typed entities and their attributes.”
知识图谱是由一些相互连接的实体和他们的属性构成的。
经典例子:罗纳尔多
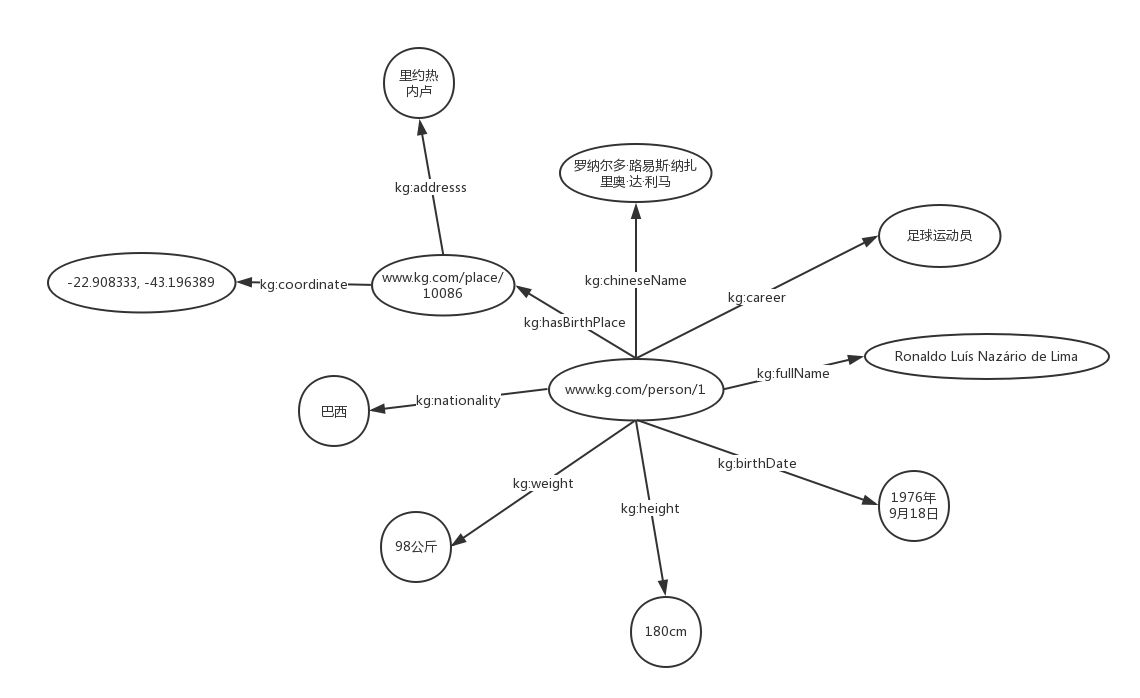

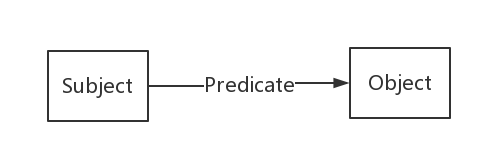
每条知识都是一个SPO三元组:
官方推荐的语义网知识表示框架:
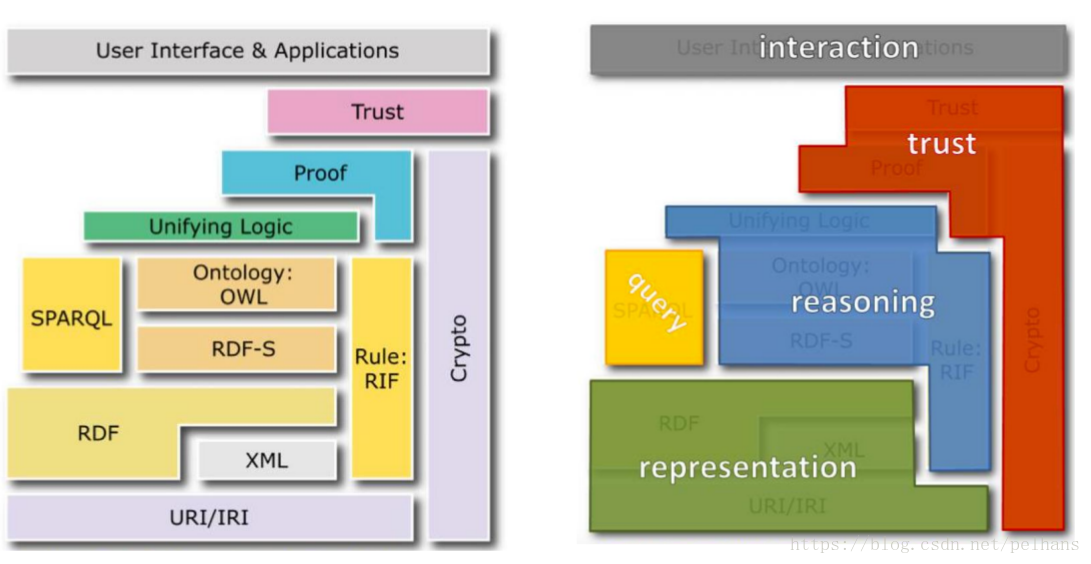
- URI/IRI:网络中的链接
- RDF和XML:资源表示框架(Resource Description Framework)
- SPARQL:知识查询语言
- RDFS、OWL:用来描述RDF数据(RDF词汇的扩展)
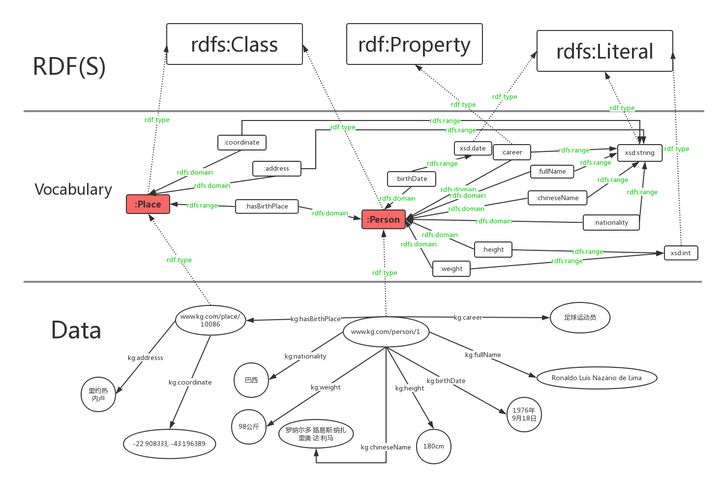
RDFRDFS


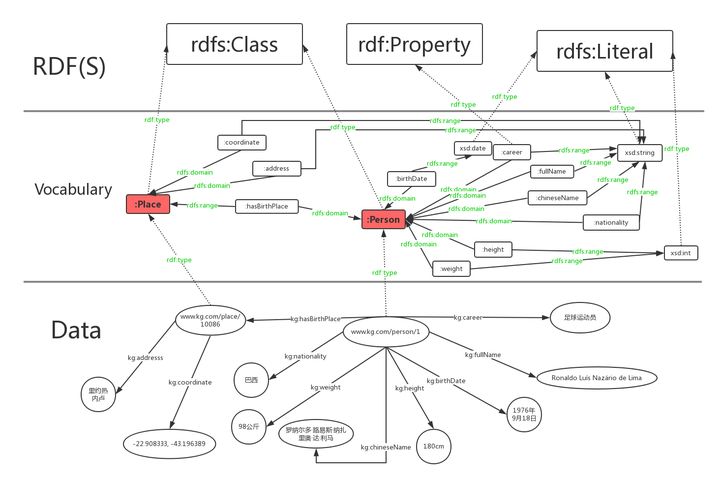
Vocabulary是自己定义的一些词汇(类别,属性),RDF(S)则是预定义词汇。从下到上是一个具体到抽象的过程。
OWL,即”Web Ontology Language”,有两个主要的功能:
- 提供快速、灵活的数据建模能力。
- 高效的自动推理。
RDFS,即”Resource Description Framework Schema”OWL,即”Web Ontology Language”@prefix rdfs:
@prefix rdf:
@prefix :
@prefix rdf:
@prefix :
@prefix owl:
这里我们用词汇rdfs:Class定义了”人”和”地点”这两个类。
:Person rdf:type rdfs:Class.
:Place rdf:type rdfs:Class.
这里我们用词汇owl:Class定义了”人”和”地点”这两个类。
:Person rdf:type owl:Class.
:Place rdf:type owl:Class.
rdfs当中不区分数据属性和对象属性,词汇rdf:Property定义了属性,即RDF的”边”。
owl区分数据属性和对象属性(对象属性表示实体和实体之间的关系)。
词汇owl:DatatypeProperty定义了数据属性,owl:ObjectProperty定义了对象属性。
:chineseName rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:chineseName rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:career rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:career rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:fullName rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .
:fullName rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .
:birthDate rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:date .
:birthDate rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:date .
:height rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:int .:height rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:int .:weight rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:int .:weight rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:int .:nationality rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range xsd:string .:nationality rdf:type owl:DatatypeProperty;
rdfs:domain :Person;
rdfs:range xsd:string .:hasBirthPlace rdf:type rdf:Property;
rdfs:domain :Person;
rdfs:range :Place .:hasBirthPlace rdf:type owl:ObjectProperty;
rdfs:domain :Person;
rdfs:range :Place .:address rdf:type rdf:Property;
rdfs:domain :Place;
rdfs:range xsd:string .:address rdf:type owl:DatatypeProperty;
rdfs:domain :Place;
rdfs:range xsd:string .:coordinate rdf:type rdf:Property;
rdfs:domain :Place;
rdfs:range xsd:string .:coordinate rdf:type owl:DatatypeProperty;
rdfs:domain :Place;
rdfs:range xsd:string .
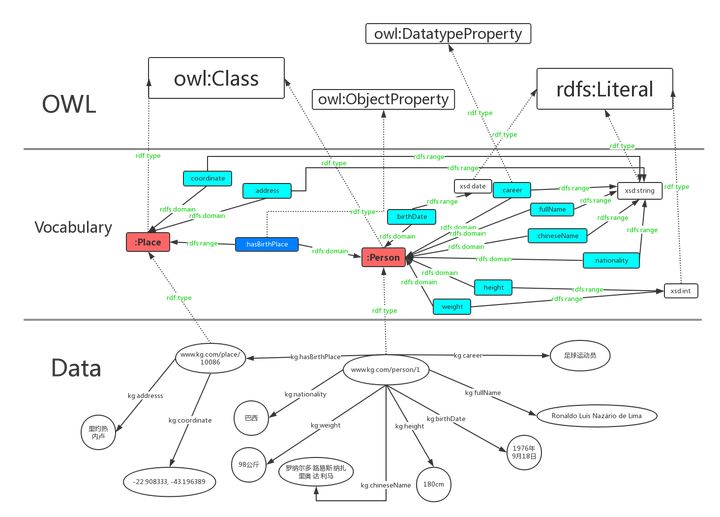
数据属性用青色表示,对象属性由蓝色表示。
RDFS常用词汇:
- rdfs:Class. 用于定义类。
- rdfs:domain. 用于表示该属性属于哪个类别。
- rdfs:range. 用于描述该属性的取值类型。
- rdfs:subClassOf. 用于描述该类的父类。比如,我们可以定义一个运动员类,声明该类是人的子类。
- rdfs:subProperty. 用于描述该属性的父属性。比如,我们可以定义一个名称属性,声明中文名称和全名是名称的子类。
OWL常用词汇:
-
描述属性特征的词汇
-
owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义”位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
- owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义”认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
- owl:FunctionalProperty. 表示该属性取值的唯一性。 例如,我们定义”母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
-
owl:inverseOf. 定义某个属性的相反关系。例如,定义”父母”的相反关系是”子女”,若A是B的父母,那么B肯定是A的子女。
-
本体映射词汇(Ontology Mapping)
-
owl:equivalentClass. 表示某个类和另一个类是相同的。
- owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
- owl:sameAs. 表示两个实体是同一个实体。
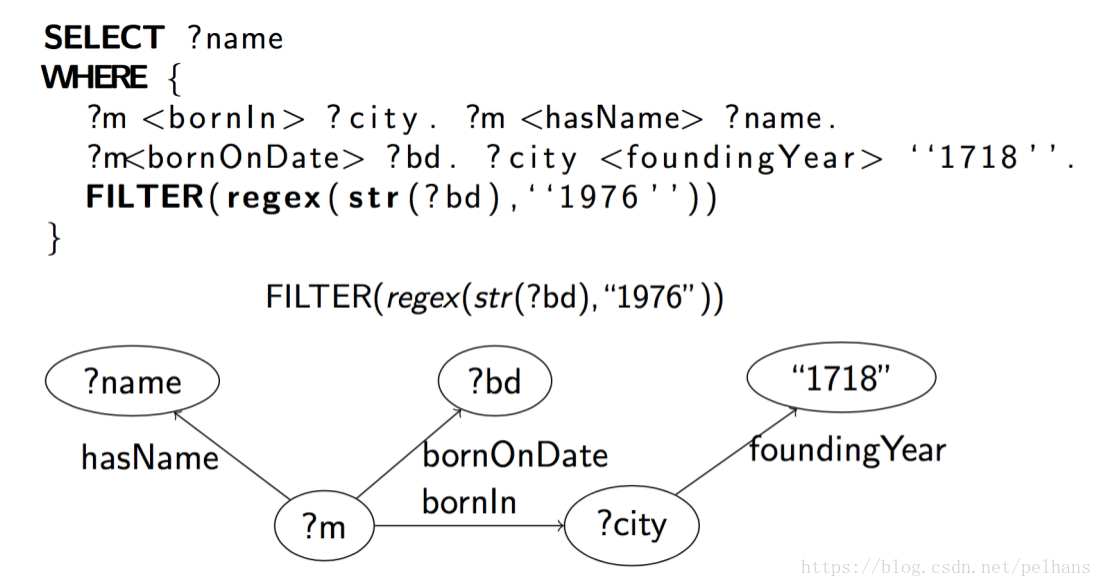
SPARQL
SPARQL是RDF的查询语言,它基于RDF数据模型,可以对不同的数据集撰写复杂的连接,由所有主流的图数据库支持。其操作如:
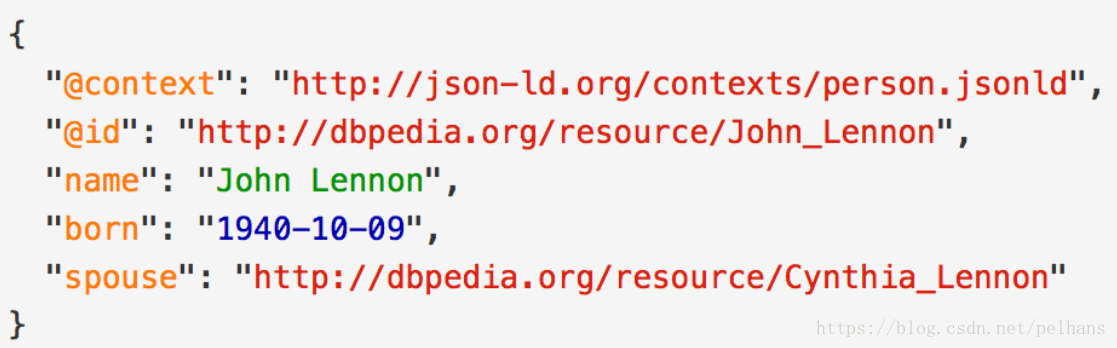
JSON-LD
JSON for Linking Data: 适用于作为程序之间做数据交换,在网页中嵌入语义数据和Restful Web Service。存储格式如:
知识获取
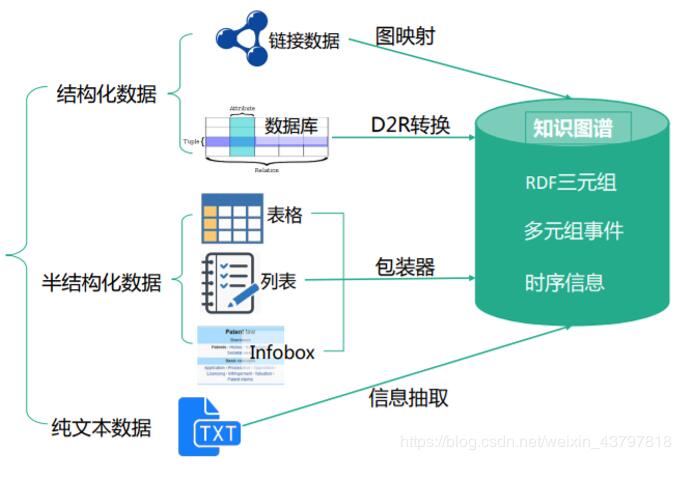
知识获取的整个过程是指从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱中。
- 半结构化数据源解析: 如今网站大部分是通过模板生成的,因此通常需要使用包装器来解析,包装器可以自动学习, 但为保证准确度,通常使用人机结合方式。实际应用中,通常针对不同结构的数据配置相应的包装器,完成数据解析。
- 非结构化数据抽取:主要为文本信息抽取:包括实体识别、关系抽取、概念抽取、事件抽取。信息抽取可分为面向特定领域的信息抽取和面向开放领域的信息抽取。
- 文本抽取:目前还没有统一的实现各类信息抽取的现成工具。通用解决方式是把现有的工具进行集成,依据抽取任务的不同使用不同的抽取工具,需要对信息进行有针对化的抽取方法,通常使用已有结构化知识进行监督学习。 NLP分词、命名实体识别工具:NLPIR、LTP、FudanNLP、Stanford NLP等
1.实体抽取
也叫命名实体识别(Named Entity Recognition,简称NER),是从文本数据集中 自动识别命名实体。
根据抽取的范围可分为:
- 面向单一领域信息抽取构建的知识图谱成为行业知识图谱,主要识别文本或数据中的人名、地名、专业术语、时间等实体信息。抽取方式有:1.启发式算法 + 人工规则,实现自动抽取实体信息的原型系统;2.统计机器学习方法辅助解决命名实体抽取问题。3.有监督学习 + 先验知识。
- 面向开放领域信息抽取构建的知识图谱成为通用知识图谱。抽取方式有:1.人工建立科学完整的命名实体分类体系;2.基于归纳总结的实体类别,基于条件随机场模型进行实体边界识别,最后采用自适应感知机 实现对实体的自动分类。 3.采用统计机器学习的方法,从目标数据集中抽取与之具有相似上下文特征的实体,从而实现 实体的分类与聚类。4.迭代扩展实体语料库。5.通过搜索引擎的服务器日志,聚类获取新出现的命名实体
2.关系抽取
文本数据经过实体抽取得到一系列离散的命名实体,但要得到语义信息,还要从文本信息中提取实体之间的关系,通过关系连接实体,形成网状的知识结构。
3.属性抽取
属性抽取是从文本源中抽取实体的属性信息,比如人物的属性包含姓名、年龄、学历等。抽取方式有:
- 将实体属性作为实体与属性值的词性关系,将属性抽取任务转化为关系抽取任务。
- 基于规则和启发性算法,抽取结构化数据。
- 基于百科类网站的半结构化数据,通过自动抽取生成训练语料,用于训练实体属性标注模 型,然后将其应用于对非结构化数据的实体属性抽取。
- 采用数据挖掘的方法,直接从文本中挖掘实体属性和属性值的关系模型,据此实现对属性名 和属性值在文中的定位。
Original: https://blog.csdn.net/Mrong1013967/article/details/121425271
Author: Mrong1013967
Title: 知识图谱学习笔记1
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557310/
转载文章受原作者版权保护。转载请注明原作者出处!