

1. 写在前面
这个系列整理的关于GNN的相关基础知识, 图深度学习是一个新兴的研究领域,将深度学习与图数据连接了起来,推动现实中图预测应用的发展。 之前一直想接触这一块内容,但总找不到能入门的好方法,而这次正好Datawhale有组队学习课,有大佬亲自带队学习入门,不犹豫,走起(感谢组织)。所以这个系列是参加GNN组队学习的相关知识沉淀, 希望能对GNN有一个好的入门吧 😉
这篇文章是简单的图论知识,以及环境的相关搭建内容, 算作对图的一个初识, 在简单的图论知识介绍里面,基本上是数据结构里面图的有关知识, 这个不是重点, 这里面的重点在后面, 也就是把环境搭建完毕之后, 整理的PyG包关于图的数据构建, 也就是 torch_geometric里面的Data和Dataset的使用, 如何把原先的样本点抽象成图的节点,把样本点之间存在的关联抽象成边表示出数据来才是应该重点学习的内容, 不同场景下肯定抽象的方式会不一样, 通过整理这篇文章,对于这块有点感觉了。
内容大纲:
- 为什么在图上深度学习
- 简单图论
- 环境配置与PyG中图数据集的表示和使用
Ok, let’s go!
2. 为什么要在图上深度学习
学习知识依然是知其然,知其所以然才有意思, 所以首先得先了解下为啥要进行图深度学习了,之前的深度学习不香了嘛?
深度学习应用中,我们接触的数据形式主要有四种: 矩阵,张量,序列和时间序列。 然而来自 现实应用的数据更多的是图结构, 比如社交网络,交通网络,知识图谱等。 图提供了一种通用的数据表示方法。
此外, 大量的现实世界问题可以作为图上的一组小的计算任务解决。 推断节点属性,检测异常节点(如垃圾邮件发送者), 识别与疾病相关的基因,向病人推荐药物等,都可以概括为 节点分类问题。 推荐,药物副作用预测,药物与目标的相互作用识别和知识图谱完成等,本质上都是 边预测问题。 (通过这段话,对图学习又有了新的认知, 由于目前做推荐的相关工作,所以主要了解了下GNN在推荐中的作用)
- 推荐系统主要的挑战是从历史交互(historical interactions)和边信息(side information)中学习有效的用户(user)和物品(item)表示,推荐系统中 大部分的信息具有图结构,例如社交关系、知识图谱、user-item交互组成的二部图(bipartite graph)、序列中的item转移图。GNN能够通过迭代传播捕捉高阶的交互,并且能够有效地整合社交关系和知识图谱等边信息(辅助信息)
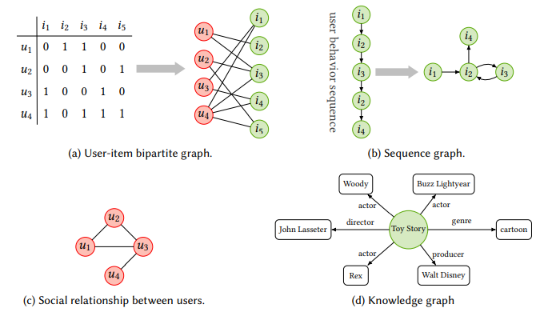

* 推荐系统可以划分为「一般的(general)推荐」和「序列化(sequential)推荐」
– 一般的(general)推荐: 认为用户具有静态的兴趣偏好,并根据隐式或显式反馈建模用户和物品间的匹配程度。从图的角度,user-item交互可以看做是二部图,GNN可以捕捉user-item交互,并学习user和item表示。另外, 边信息也可以用来提升推荐性能,常见的策略是增加正则项或者融合边信息的表示。一般的推荐会受到数据稀疏和冷启动的制约。 如果把a里面的推荐问题看成一个矩阵补全的问题,我们知道一般推荐里面用隐语义模型,原理就是基于交互学习用户和物品的向量表示。而在GNN中, 矩阵补全可以看做图上的链接预测(link prediction)问题, 同样也可以学习用户和item的表示,且如果多层GNN,还能有效模拟信息扩散过程。
– 序列化推荐:捕捉item序列中的序列化模式,为用户推荐下一个感兴趣的物品。主要有基于马尔科夫链(MC)、基于RNN、基于注意力和自注意力机制的方法。随着GNN的出现,一些工作将item序列转换为图结构并用GNN捕捉其中的转移模式。
* 在推荐中,GNN往往可以做一些预训练,丰富数据表示,解决冷启动等。比如图embedding
同一图的节点存在连接关系,而传统机器学习中,假设样本是独立同分布的,所以传统机器学习不适用图计算任务。 图机器学习研究如何构建节点表征(节点表征同时包含节点自身信息和节点邻接信息), 从而可以在节点表征应用传统的分类技术实现节点分类。 图机器学习成功的关键在于节点构建表征, 而深度学习又在表征学习中具有强大能力,所以 深度学习与图结合,利用神经网络学习节点表征,是个非常不错的机会。
当然,会面临挑战:
- 首先,神经网络是为规则且结构化的数据设计的(图像,文本,语言,序列), 但 图是不规则的(节点无序), 节点可以有不同的邻居节点。
- 其次, 规则数据结构信息简单,而 图结构信息是复杂的, 特别是考虑到各种类型的复杂图,节点和边可以关联丰富信息,这些丰富信息是无法被传统DL学习到的。
So,why 在图上深度学习呢? 我自己理解的一句话图能更好的对我们现实世界中的问题进行抽象,更好的学习数据表示和数据之间的信息, 给我们提供了更好的解决问题的一种思路, 而DL在数据表征上比较强大,但考虑数据关联上还是存在局限性
这样,大体知道为啥图深度学习了,既然图深度学习这么好,那么就开始吧哈哈。
; 3. 简单图论
这里是介绍有关图论的基本知识。
3.1 图的表示
首先是图(边和顶点的集合)的定义:
- 一个图被记为G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E },其中V = { v 1 , … , v N } \mathcal{V}=\left{v_{1}, \ldots, v_{N}\right}V ={v 1 ,…,v N }是数量为N = ∣ V ∣ N=|\mathcal{V}|N =∣V ∣ 的结点的集合,E = { e 1 , … , e M } \mathcal{E}=\left{e_{1}, \ldots, e_{M}\right}E ={e 1 ,…,e M } 是数量为M M M 的边的集合。
- 图用节点表示实体(entities ),用边表示实体间的关系(relations)。
- 节点和边的信息可以是 类别型的(categorical),类别型数据的取值只能是哪一类别。一般称类别型的信息为 标签(label)。
- 节点和边的信息可以是 数值型的(numeric),类别型数据的取值范围为实数。一般称数值型的信息为 属性(attribute)。
- 大部分情况中,节点含有信息,边可能含有信息。
其实是图的存储,也就是图邻接矩阵的定义:
- 给定一个图G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E },其对应的 邻接矩阵被记为A ∈ { 0 , 1 } N × N \mathbf{A} \in{0,1}^{N \times N}A ∈{0 ,1 }N ×N。A i , j = 1 \mathbf{A}_{i, j}=1 A i ,j =1表示存在从结点v i v_i v i 到v j v_j v j 的边,反之表示不存在从结点v i v_i v i 到v j v_j v j 的边。
- 在 无向图中,从结点v i v_i v i 到v j v_j v j 的边存在,意味着从结点v j v_j v j 到v i v_i v i 的边也存在。因而 无向图的邻接矩阵是对称的。
- 在 无权图中, 各条边的权重被认为是等价的,即认为 各条边的权重为1 1 1。
- 对于 有权图,其对应的邻接矩阵通常被记为W ∈ [ 0 , 1 ] N × N \mathbf{W} \in\ [0,1]^{N \times N}W ∈[0 ,1 ]N ×N,其中W i , j = w i j \mathbf{W}{i, j}=w{ij}W i ,j =w i j 表示从结点v i v_i v i 到v j v_j v j 的边的权重。若边不存在时,边的权重为0 0 0。这里的权重应该是归一化了的, 但有时候归一化会丢失些信息,具体问题或许可以具体分析。
下面是一个无权图的例子:
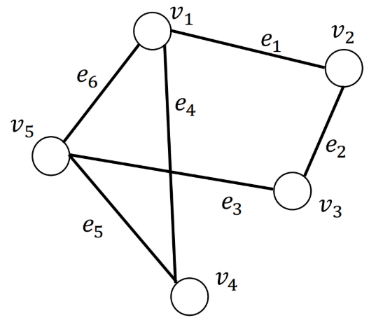
这个图的表示,用邻近矩阵的话,可以表示成下面这个样子, 这里和数据结构里面图的表示其实是一样的:
A = ( 0 1 0 1 1 1 0 1 0 0 0 1 0 0 1 1 0 0 0 1 1 0 1 1 0 ) \mathbf{A}=\left(\begin{array}{lllll} 0 & 1 & 0 & 1 & 1 \ 1 & 0 & 1 & 0 & 0 \ 0 & 1 & 0 & 0 & 1 \ 1 & 0 & 0 & 0 & 1 \ 1 & 0 & 1 & 1 & 0 \end{array}\right)A =⎝⎜⎜⎜⎜⎛0 1 0 1 1 1 0 1 0 0 0 1 0 0 1 1 0 0 0 1 1 0 1 1 0 ⎠⎟⎟⎟⎟⎞
; 3.2 图的属性
这里是有关图的相关属性的介绍, 这里还是数据结构的知识, 回顾下图啦。
首先是节点的度(degree):
- 对于有向有权图,结点v i v_i v i 的出度(out degree)等于从v i v_i v i 出发的边的权重之和,结点v i v_i v i 的入度(in degree)等于从连向v i v_i v i 的边的权重之和。
- 无向图是有向图的特殊情况,结点的出度与入度相等。
- 无权图是有权图的特殊情况,各边的权重为1 1 1,那么结点v i v_i v i 的出度(out degree)等于从v i v_i v i 出发的边的数量,结点v i v_i v i 的入度(in degree)等于从连向v i v_i v i 的边的数量。
- 结点v i v_i v i 的度记为d ( v i ) d(v_i)d (v i ),入度记为d i n ( v i ) d_{in}(v_i)d i n (v i ),出度记为d o u t ( v i ) d_{out}(v_i)d o u t (v i )。
其次是邻接节点的定义(neighbors):
- 结点v i v_i v i 的邻接结点为与结点v i v_i v i 直接相连的结点,其被记为N ( v i ) \mathcal{N(v_i)}N (v i )。
- 结点v i v_i v i 的k k k 跳远的邻接节点(neighbors with k k k-hop),指的是到结点v i v_i v i 要走k k k步的节点(一个节点的2 2 2跳远的邻接节点包含了自身)。
行走的定义, 这个让我不自觉联想到了d e e p w a l k deepwalk d e e p w a l k
- w a l k ( v 1 , v 2 ) = ( v 1 , e 6 , v 5 , e 5 , v 4 , e 4 , v 1 , e 1 , v 2 ) walk(v_1, v_2) = (v_1, e_6, v_5, e_5, v_4,e_4,v_1,e_1,v_2)w a l k (v 1 ,v 2 )=(v 1 ,e 6 ,v 5 ,e 5 ,v 4 ,e 4 ,v 1 ,e 1 ,v 2 ),这是一次”行走”,它是一次从节点v 1 v_1 v 1 出发,依次经过边e 6 , e 5 , e 4 , e 1 e_6,e_5,e_4,e_1 e 6 ,e 5 ,e 4 ,e 1 ,点v 5 , v 4 , v 1 v_5,v_4,v_1 v 5 ,v 4 ,v 1 ,最终到达节点v 2 v_2 v 2 的”行走”。 这里面经过的边的条数就是这一次walk的长度4,这次行走的话,就是4,但 注意, 从一个点出发到达另一个点, 行走不一定唯一。就比如这里从v 1 v_1 v 1 到v 2 v_2 v 2 ,有很多条路径可达。 下面有个定理:
有一图,其邻接矩阵为 A \mathbf{A}A, A n \mathbf{A}^{n}A n为邻接矩阵的n n n次方,那么A n [ i , j ] \mathbf{A}^{n}[i,j]A n [i ,j ]等于从结点v i v_i v i 到结点v j v_j v j 的长度为n n n的行走的个数。
- 有一图,其邻接矩阵为 A \mathbf{A}A, A n \mathbf{A}^{n}A n为邻接矩阵的n n n次方,那么A n [ i , j ] \mathbf{A}^{n}[i,j]A n [i ,j ]等于从结点v i v_i v i 到结点v j v_j v j 的长度为n n n的行走的个数。
- 下图所示为w a l k ( v 1 , v 2 ) = ( v 1 , e 6 , e 5 , e 4 , e 1 , v 2 ) walk(v_1, v_2) = (v_1, e_6,e_5,e_4,e_1,v_2)w a l k (v 1 ,v 2 )=(v 1 ,e 6 ,e 5 ,e 4 ,e 1 ,v 2 ),其中红色数字标识了边的访问序号。

- 在”行走”中,节点是允许重复的。这个要和”路径”做一个区分,”路径”是结点不可重复的”行走”。
(PS: 好吧,和deepwalk说的不是一回事,后者是从图上随机游走产生序列,这里面包含了很多次行走)
下面是子图的定义:
- 有一图G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E },另有一图G ′ = { V ′ , E ′ } \mathcal{G}^{\prime}={\mathcal{V}^{\prime}, \mathcal{E}^{\prime}}G ′={V ′,E ′},其中V ′ \mathcal{V}^{\prime}V ′ 含于V \mathcal{V}V,E ′ \mathcal{E}^{\prime}E ′含于E \mathcal{E}E,那么G ′ \mathcal{G}^{\prime}G ′是G \mathcal{G}G的子图。
连通图与连通分量:
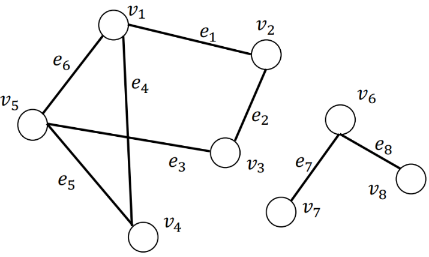
- 在无向图G中,若从顶点v i v_i v i 到顶点v j v_j v j 有路径(当然从v j v_j v j 到v i v_i v i 也一定有路径),则称v i v_i v i 和v j v_j v j 是连通的。若V(G)中任意两个不同的顶点v i v_i v i 和v j v_j v j 都连通(即有路径),则称G为连通图(Con-nected Graph)。

- 连通分量的定义:无向图G的 极大连通子图称为G的最强连通分量(Connected Component)。任何连通图的连通分量只有一个,即是其自身,非连通的无向图有多个连通分量。如果把下图看成一个整图, 那么这个图是非连通的,有左右两个连通分量。 如果把下图看成两个连通的图,那么两个图都是连通的, 分别是其自身的连通分量。
下面是一些高级的定义了:
- 最短路径,shortest path:
v s , v t ∈ V v_{s}, v_{t} \in \mathcal{V}v s ,v t ∈V 是图G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E }上的一对结点,结点对v s , v t ∈ V v_{s}, v_{t} \in \mathcal{V}v s ,v t ∈V之间所有路径的集合记为P s t \mathcal{P}{\mathrm{st}}P s t 。结点对v s , v t v{s}, v_{t}v s ,v t 之间的最短路径p s t s p p_{\mathrm{s} t}^{\mathrm{sp}}p s t s p 为P s t \mathcal{P}{\mathrm{st}}P s t 中长度最短的一条路径,其形式化定义为
p s t s p = arg min p ∈ P s t ∣ p ∣ p{\mathrm{s} t}^{\mathrm{sp}}=\arg \min {p \in \mathcal{P}{\mathrm{st}}}|p|p s t s p =ar g p ∈P s t min ∣p ∣
其中,p p p表示P s t \mathcal{P}_{\mathrm{st}}P s t 中的一条路径,∣ p ∣ |p|∣p ∣是路径p p p的长度。 - 直径,diameter:
给定一个连通图G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E },其直径为其 所有结点对之间的最短路径的最大值,形式化定义为
diameter ( G ) = max v s , v t ∈ V min p ∈ P s t ∣ p ∣ \operatorname{diameter}(\mathcal{G})=\max {v{s}, v_{t} \in \mathcal{V}} \min {p \in \mathcal{P}{s t}}|p|d i a m e t e r (G )=v s ,v t ∈V max p ∈P s t min ∣p ∣
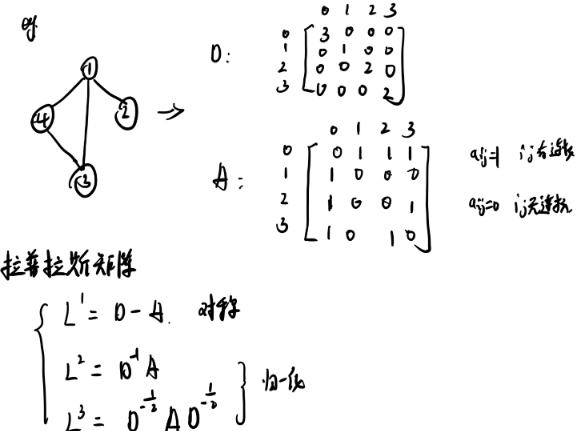
- 拉普拉斯矩阵,Laplacian Matrix:
给定一个图G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E },其邻接矩阵为A A A,其拉普拉斯矩阵定义为L = D − A \mathbf{L=D-A}L =D −A,其中D = d i a g ( d ( v 1 ) , ⋯ , d ( v N ) ) \mathbf{D=diag(d(v_1), \cdots, d(v_N))}D =d i a g (d (v 1 ),⋯,d (v N ))。 - 对称归一化的拉普拉斯矩阵,Symmetric normalized Laplaciaaa:
给定一个图G = { V , E } \mathcal{G}={\mathcal{V}, \mathcal{E}}G ={V ,E },其邻接矩阵为A A A,其规范化的拉普拉斯矩阵定义为
L = D − 1 2 ( D − A ) D − 1 2 = I − D − 1 2 A D − 1 2 \mathbf{L=D^{-\frac{1}{2}}(D-A)D^{-\frac{1}{2}}=I-D^{-\frac{1}{2}}AD^{-\frac{1}{2}}}L =D −2 1 (D −A )D −2 1 =I −D −2 1 A D −2 1
后面这俩是啥东西,解释下, 关于拉普拉斯矩阵为啥是这样,这里先不解释,这里记得之前看的时候,挺难的,什么傅里叶欧拉公式啥的,目前用不到,所以就先不整理了,感兴趣的可以看阿泽哥这篇入门图卷积。 而只这么看这俩概念,估计也是有点懵逼,到底这是啥东西呢?
其实, 在图神经网络里面, 有非常重要的两个矩阵: 度矩阵D和邻接矩阵A。度矩阵反映了自身度数,而邻接矩阵反映了邻里关系。 而拉普拉斯矩阵呢? 就是这两个矩阵的运算得到。拿个图举个例子:
; 3.3 图的种类
- 同质图(Homogeneous Graph):只有一种类型的节点和一种类型的边的图。
- 异质图(Heterogeneous Graph):存在多种类型的节点和多种类型的边的图。

二部图(Bipartite Graphs):节点分为两类,只有不同类的节点之间存在边。

这里的几种图在推荐里面的策略:GNN相比于随机游走等传统的图学习方法取得了更好的表现。对于二部图,GNN能够迭代地从交互的items中传播信息,并更新用户向量(对item同理),可以增强user/item表示。GNN还可以学习边信息的压缩表示,学习到的向量可以整合到交互数据的表示中以提升性能,另外的策略是结合多个图到一个异质图,然后在全图上传播信息。
3.4 图结构数据上的机器学习
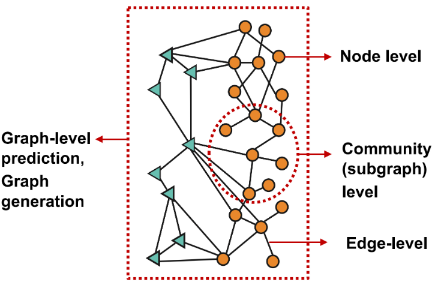
图结构的机器学习,有这么几大应用:
- 节点预测:预测节点的类别或某类属性的取值, 比如对是否是潜在客户分类、对游戏玩家的消费能力做预测。
- 边预测:预测两个节点间是否存在链接, 比如Knowledge graph completion、好友推荐、商品推荐
- 图的预测:对不同的图进行分类或预测图的属性, 比如分子属性预测
- 节点聚类:检测节点是否形成一个社区, 比如社交圈检测
- 其他任务
- 图生成:例如药物发现
- 图演变:例如物理模拟
- ……
; 3.5 应用于神经网络的挑战

过去的深度学习应用中,我们主要接触的数据形式主要是这四种: 矩阵、张量、序列(sequence)和时间序列(time series), 它们都是规则的结构化的数据。然而图数据是非规则的非结构化的,它具有以下的特点:
- 任意的大小和复杂的拓扑结构;
- 没有固定的结点排序或参考点;
- 通常是动态的,并具有多模态的特征;
- 图的信息并非只蕴含在节点信息和边的信息中,图的信息还包括了图的拓扑结构。
以往的深度学习技术是为规则且结构化的数据设计的,无法直接用于图数据。应用于图数据的神经网络,要求
- 适用于不同度的节点;
- 节点表征的计算与邻接节点的排序无关;
- 不但能够根据节点信息、邻接节点的信息和边的信息计算节点表征,还能根据图拓扑结构计算节点表征。下面的图片展示了一个需要根据图拓扑结构计算节点表征的例子。图片中展示了两个图,它们同样有俩黄、俩蓝、俩绿,共6个节点,因此它们的节点信息相同;假设边两端节点的信息为边的信息,那么这两个图有一样的边,即它们的边信息相同。但这两个图是不一样的图,它们的拓扑结构不一样。
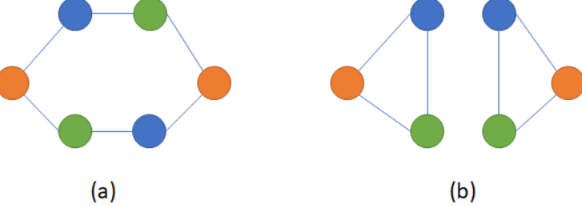
这个有点像Node2Vec里面的同质性和异构性,同质性更看重的就是邻接点,距离相近,应该更加相似。 而异构性就是看重的拓扑结构,结构相似,应该更加相似。Node2Vec就是在这俩之间做出了衡量。 还有一点,如果想偏重拓扑结构的话,在游走的时候更偏向BFS, 因为根据BFS的特点, 是访问与当前节点相邻的所有节点,那么访问了一个邻居节点之后,会回来,再去访问另一个,这样, 才能够探索出结构来。而偏重同质性的话,偏向用DFS。
4. 环境配置与PyG中图数据集的表示和使用
有了一些图理论的基础, 下面搭建个环境,就能玩了。 所以先把必要的编程环境搭建起来。
4.1 环境搭建
PyTorch Geometric (PyG)是面向几何深度学习的PyTorch的扩展库,几何深度学习指的是应用于图和其他不规则、非结构化数据的深度学习。基于PyG库,我们可以轻松地根据数据生成一个图对象,然后很方便的使用它;我们也可以容易地为一个图数据集构造一个数据集类,然后很方便的将它用于神经网络。 好吧,这个库我也是第一次听, 又学习到啦。
首先,先安装Pytorch和cuda, 由于我这里使用的我实验室的服务器,所以这些环境之前都已经配置好:

所以下面按照pyG, 注意,这个要安装正确版本的, 版本的安装方法以及 安装过程中出现的大部分问题的解决方案可以在Installation of of PyTorch Geometric页面找到。
我这里的torch和cuda和文档里面的不一样,所以我这边需要这个版本
pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-1.7.0+cu102.html
pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-1.7.0+cu102.html
pip install torch-cluster -f https://pytorch-geometric.com/whl/torch-1.7.0+cu102.html
pip install torch-spline-conv -f https://pytorch-geometric.com/whl/torch-1.7.0+cu102.html
pip install torch-geometric
这样,就把pyG包安装好,接下来打开pycharm, 连接远程的这个python环境,就可以愉快的编程啦。
4.2 Data 类——PyG中图的表示及其使用
Data类的官方文档为torch_geometric.data.Data。
4.2.1 构造函数
构造函数如下:
class Data(object):
def __init__(self, x=None, edge_index=None, edge_attr=None, y=None, **kwargs):
r"""
Args:
x (Tensor, optional): 节点属性矩阵,大小为[num_nodes, num_node_features]
edge_index (LongTensor, optional): 边索引矩阵,大小为[2, num_edges],第0行为头节点,第1行为尾节点,头指向尾
edge_attr (Tensor, optional): 边属性矩阵,大小为[num_edges, num_edge_features]
y (Tensor, optional): 节点或图的标签,任意大小(,其实也可以是边的标签)
"""
self.x = x
self.edge_index = edge_index
self.edge_attr = edge_attr
self.y = y
for key, item in kwargs.items():
if key == 'num_nodes':
self.__num_nodes__ = item
else:
self[key] = item
edge_index的每一列定义一条边,其中第一行为边起始节点的索引,第二行为边结束节点的索引。这种表示方法被称为 COO格式(coordinate format),通常用于表示稀疏矩阵。PyG不是用稠密矩阵A ∈ { 0 , 1 } ∣ V ∣ × ∣ V ∣ \mathbf{A} \in { 0, 1 }^{|\mathcal{V}| \times |\mathcal{V}|}A ∈{0 ,1 }∣V ∣×∣V ∣来持有邻接矩阵的信息,而是用仅存储邻接矩阵A \mathbf{A}A中非0 0 0元素的稀疏矩阵来表示图。
通常,一个图至少包含 x, edge_index, edge_attr, y, num_nodes5个属性, 当图包含其他属性时,我们可以通 过指定额外的参数使 Data 对象包含其他的属性:
graph = Data(x=x, edge_index=edge_index, edge_attr=edge_attr, y=y, num_nodes=num_nodes, other_attr=other_attr)
4.2.2 对象转换
- 转
dict对象为Data对象
我们也可以 将一个dict对象转换为一个Data对象:
graph_dict = {
'x': x,
'edge_index': edge_index,
'edge_attr': edge_attr,
'y': y,
'num_nodes': num_nodes,
'other_attr': other_attr
}
graph_data = Data.from_dict(graph_dict)
from_dict是一个类方法:
@classmethod
def from_dict(cls, dictionary):
r"""Creates a data object from a python dictionary."""
data = cls()
for key, item in dictionary.items():
data[key] = item
return data
注意: graph_dict中属性值的类型与大小的要求与 Data类的构造函数的要求相同。
2. 我们可以将 Data对象转换为 dict对象:
def to_dict(self):
return {key: item for key, item in self}
或转换为 namedtuple:
def to_namedtuple(self):
keys = self.keys
DataTuple = collections.namedtuple('DataTuple', keys)
return DataTuple(*[self[key] for key in keys])
4.2.3 Data 对象属性
x = graph_data['x']
graph_data['x'] = x
graph_data.keys()
graph_data.coalesce()
通过内置的一个图,看看其他特性:
from torch_geometric.datasets import KarateClub
dataset = KarateClub()
data = dataset[0]
print(data)
print('==============================================================')
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Number of node features: {data.num_node_features}')
print(f'Number of node features: {data.num_features}')
print(f'Number of edge features: {data.num_edge_features}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'if edge indices are ordered and do not contain duplicate entries.: {data.is_coalesced()}')
print(f'Number of training nodes: {data.train_mask.sum()}')
print(f'Training node label rate: {int(data.train_mask.sum()) / data.num_nodes:.2f}')
print(f'Contains isolated nodes: {data.contains_isolated_nodes()}')
print(f'Contains self-loops: {data.contains_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')
结果如下:
Data(edge_index=[2, 156], train_mask=[34], x=[34, 34], y=[34])
==============================================================
Number of nodes: 34
Number of edges: 156
Number of node features: 34
Number of node features: 34
Number of edge features: 0
Average node degree: 4.59
if edge indices are ordered and do not contain duplicate entries.: True
Number of training nodes: 4
Training node label rate: 0.12
Contains isolated nodes: False
Contains self-loops: False
Is undirected: True
该图有34个节点, 156条边。节点属性的维度是34,边属性的维度0。训练集的节点数量4。
4.2.4 Dataset 类——PyG中图数据集的表示及其使用
PyG内置了大量常用的基准数据集,接下来我们以PyG内置的 Planetoid数据集为例,来 学习PyG中图数据集的表示及使用。
Planetoid是一个引文网络数据集。节点表示文档,边表示引用链接。训练、验证和测试分割是通过二进制掩码进行的。
看到这里说下我的感觉, 这里可能是一个多分类任务, 也就是给定某篇文档,看看是哪一类的, 而如果这里用DL的话, 是没法考虑文档与文档之间的链接信息的,只能把文档看做独立样本。 而GNN里面,就能构件图把这种链接引用关系考虑进来。
Planetoid数据集类的官方文档为torch_geometric.datasets.Planetoid。
- 生成数据集对象并生成数据集
在PyG中生成一个数据集是简单直接的,可以直接用下面的代码:
dataset = Planetoid(root='dataset/Cora', name='Cora')
如果是第一次生成内置数据集,会进行下载,但是我这里下载超时,所以可以自己去这里下载, 这里还探索到了一种GitHub里面只下载某个文件目录的方法TortoiseSVN, 去官网下载这个软件。在桌面右击,点击SVN checkout,出现的框里面

2. 该数据集的分析:
print(f"图的个数: {len(dataset)}")
print(f"类别总数: {dataset.num_classes}")
print(f"节点的特征数: {dataset.num_node_features}")
print(f"图结构: {dataset[0]}")
data = dataset[0]
print(f"是否是无向图: {data.is_undirected()}")
print(f"用作训练集的节点: {data.train_mask.sum().item()}")
print(f"用作验证集的节点: {data.val_mask.sum().item()}")
print(f"用作测试集的节点: {data.test_mask.sum().item()}")
这个结果如下:

这应该是一个七分类任务,所以最终的预测任务应该是给定一篇文档,预测是7类中的哪一类。分析下这个图数据,1个图, 2708个节点, 10556条边,训练集,验证集和测试集的节点如上。 这里解释成预测任务: 一共2708篇文档, 文档与文档的引用链接共10556。但是到这里还是有些懵逼的, 所以又进行了下面的探索:
print(data.train_mask)
print(data.x.shape)
print(data.x)
print(data.y)
print(data.edge_index)
print(data.edge_attr)
这个的结果如下:

这里解释下, 首先是
train_mask, 打印了下是2708维的,每一个元素不是True,就是False。 可以这么想, 我们有2708篇文档, 存放地址是0-2707,而这个 train_mask为True的位置对应的文档用作训练集。 val_mask和 test_mask同理。这也是为啥看训练集样本数量的时候 sum()的原因。 其次就是 data.x的形状 [2708, 1433],表示的是2708篇文档, 每篇文档1433个特征,或者想成embedding的维度是1433。 data.y其实就是说的每一篇文档属于哪一类,共7个类别。 data.edge_index这个是[2,10556]的Tensor,每个数肯定是0-2707(文档的位置), 表示的是文档与文档之间的链接信息,比如第1列这个,表示0位置的文档中有个链接可以跳到633这个位置的文档中。 data.edge_attr表示的边的属性为None。所以这样分析完了之后,才发现,这个图并不是很复杂
文档的7分类问题, 每一篇文档1433个特征,或者每一篇文档的embedding维度1433。文档与文档之间有链接关系,这个可以通过边进行体现 到这里,就清晰一些了,但还有2个疑问: 为啥GNN里面, 训练集的节点个数这么少呢? 测试集的节点个数反而多了? 然后我用了这句代码检验了一下训练集,验证集和测试集之间是否有重叠:
print((data.train_mask^data.test_mask^data.val_mask).sum())
这个1640正好等于训练集,验证集和测试集的节点个数之和,说明没有重叠, 那为啥采用了1640个节点呢? 为啥不2708篇文档都用上?
3. 数据集的使用
假设我们定义好了一个图神经网络模型,其名为 Net。节点分类图数据集在训练过程中的使用。
model = Net().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
这里的训练方式,发现和普通的神经网络训练一样, 但是这里的Net()说是个图神经网络, 具体怎么构建不知道, 也就是说,只要把数据构建成图的格式,然后能构建出图神经网络来, 后面的训练基于Pytorch就非常容易了,所以关键还是 前面的数据构建图,以及图神经网络里面的计算逻辑。 后面应该会重点学习吧。
5. 小总
到这里就把简单图论以及PyG如何表示图整理完毕, 这次是趁着端午节放假的时间学习整理的,实习期间,这种时间还是非常难得的,但里面还是有些细节没有来得及整理的, 通过后面的学习进行补充吧。
最后就是有个作业题:
请通过继承
Data类实现一个类,专门用于表示”机构-作者-论文”的网络。该网络包含”机构”、”作者”和”论文”三类节点,以及”作者-机构”和”作者-论文”两类边。对要实现的类的要求:1)用不同的属性存储不同节点的属性;2)用不同的属性存储不同的边(边没有属性);3)逐一实现获取不同节点数量的方法。
这里的网络说的应该就是图的意思(第一眼还以为搭建个GNN呢,吓我一跳), 这里自己思考了下, 写了这样的一个类:
from torch_geometric.data import Data
class MyData(Data):
def __init__(self, x=None, edge_index=None, edge_attr=None, y=None, **kwargs):
r"""
Args:
x: list[x1,x2,x3], 这里的x用一个列表, 长度为3, 表示3类节点, 每个x_i[num_nodes, num_node_fea]的维度,节点属性矩阵
edge_index: list[e1, e2],这里用个列表,表示两类边,e_i边索引矩阵,大小为[2, num_edges]
edge_attr: list, 每个e_i 边属性矩阵,大小为[num_edges, num_edge_features]
y (Tensor, optional): 节点或图的标签,任意大小(,其实也可以是边的标签),这个具体看啥任务了
"""
super(MyData, self).__init__()
self.organ, self.author, self,paper = x
self.organ_author, self.author_paper = edge_index
self.organ_author_att, self.author_paper_att = self.edge_attr
self.y = y
for key, item in kwargs.items():
if key == 'num_nodes':
self.__num_nodes__ = item
else:
self[key] = item
def get_organ_num(self, key_word):
if key_word == 'organ':
return len(self.organ)
elif key_word == 'author':
return len(self.author)
elif key_word == 'paper':
return len(self.paper)
else:
return (len(self.organ), len(self.author), len(self.paper))
这里把原来的x封装成了个列表, 边也同理,所以这个如果调用的时候,得先把三类节点用一个列表传进去, 边也是存放成一个列表传进去。
参考:
- DatawhaleGNN组队学习
- Graph Neural Networks in Recommender Systems: A Survey
- 图神经网络在推荐系统的应用研究综述
- pytorch-geometric文档
Original: https://blog.csdn.net/wuzhongqiang/article/details/117898474
Author: 翻滚的小@强
Title: 图神经网络GNN(一): 简单图论与PyG中图数据集的表示及其使用
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557238/
转载文章受原作者版权保护。转载请注明原作者出处!