

维度选择公式:n>8.33logN
JL理论:塞下N个向量,只需要𝒪(logN)维空间
一 BERT 句向量 缺点
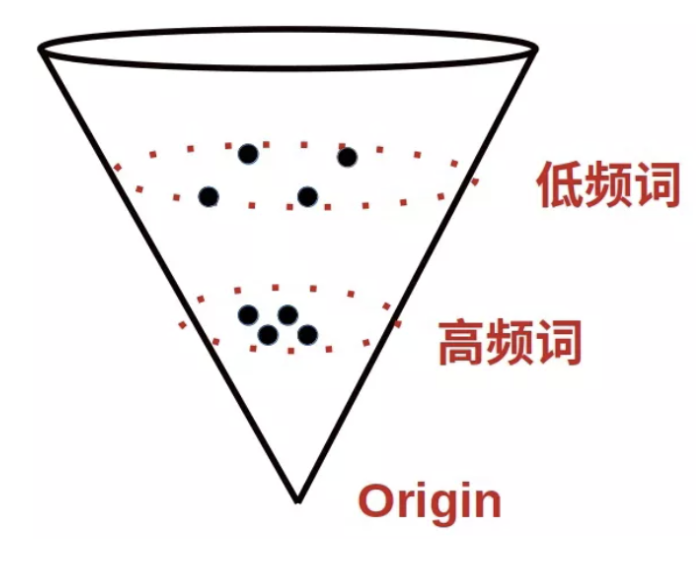
论文1和论文2证明了 transformer 模型出来的向量表达(如 BERT、GPT2)会产生各向异性,具体表现是向量分布不均匀,低频词分布稀疏距离原点较远,高频词分布紧密,距离原点较近,如图所示。

向量值受句子中词在所有训练语料里的词频影响,导致高频词编码的句向量距离更近,更集中在原点附近,导致即使一个高频词和一个低频词的语义是等价的,但词频的差异也会带来很大的距离偏差,从而词向量的距离就不能很好地代表语义相关性,和人判断句子的语义不受词频影响也不符合。
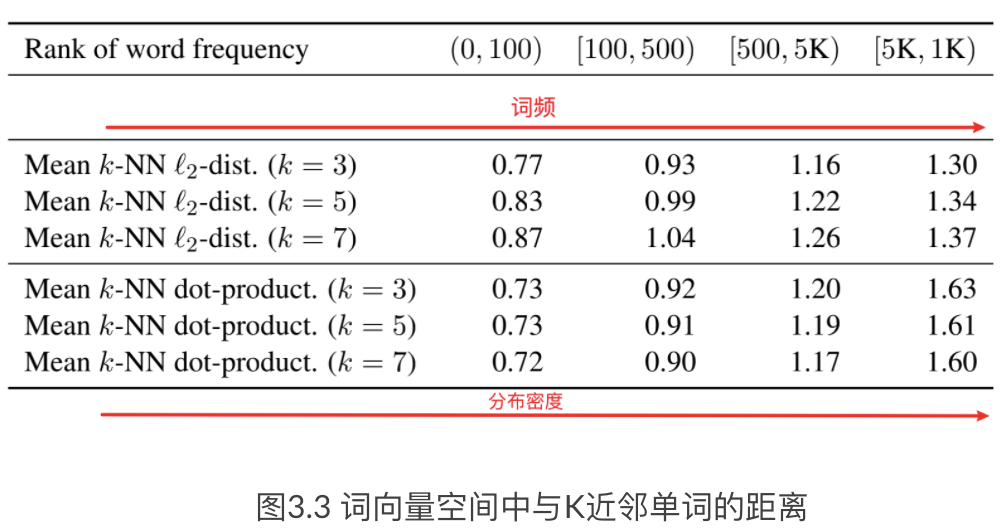
On the Sentence Embeddings from Pre-trained Language Models论文也通过试验验证了上述问题:
文中度量了词向量空间中与K近邻单词的 l2距离的均值。我们可以看到高频词分布更集中,而低频词分布则偏向稀疏。

; 二 BERT-FLOW优化
论文:On the Sentence Embeddings from Pre-trained Language Models
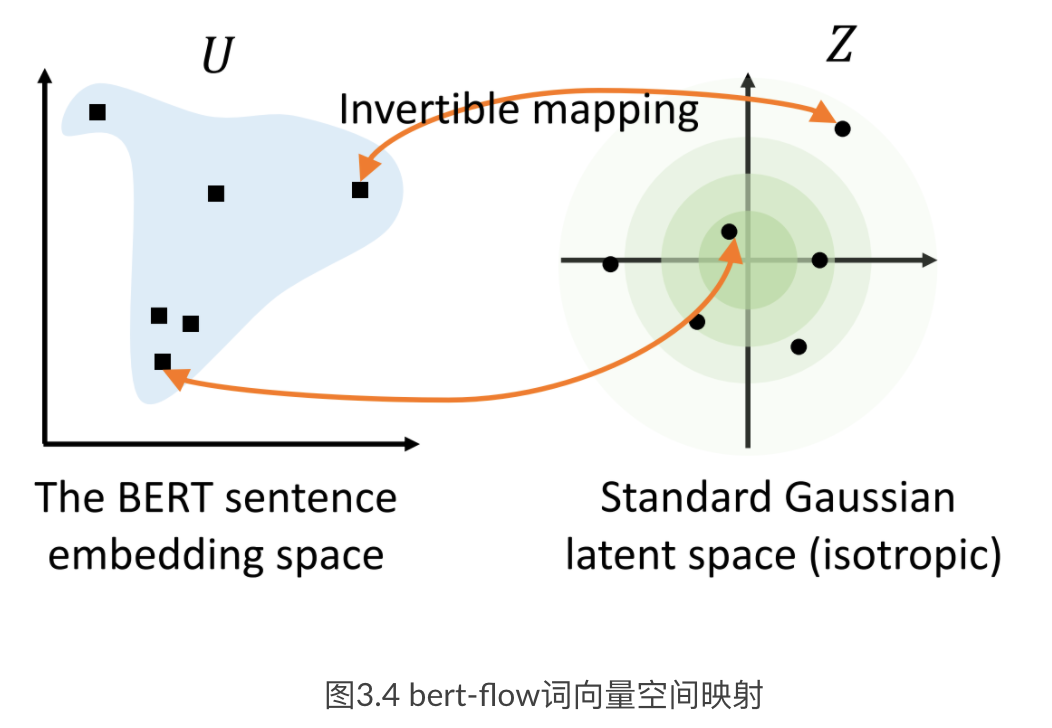
代码: bert flow coding github将BERT embedding空间映射到一个标准高斯隐空间
参考:苏剑林-细水长flow之NICE:流模型的基本概念与实现

二 BERT-whitening优化
论文:Whitening Sentence Representations for Better Semantics and Faster Retrieval
代码:bert whitening coding github
基本思想与BERT-FLOW相同,将BERT embedding空间映射到一个标准高斯隐空间。但是BERT-FLOW的flow模型较为复杂,该论文提出使用线性变换即可实现flow模型的效果。


把当前任务的语料,分别一句句地输入到预训练模型中得到各自的embedding,然后对embeddings做特征值分解,得到变换矩阵,然后存起来。应用时,输入新的句子,把它们输入预训练模型,得到句子embedding,再用存起来的变换矩阵u和W做变换,这时候得到的embedding就是标准正交基表示的embedding
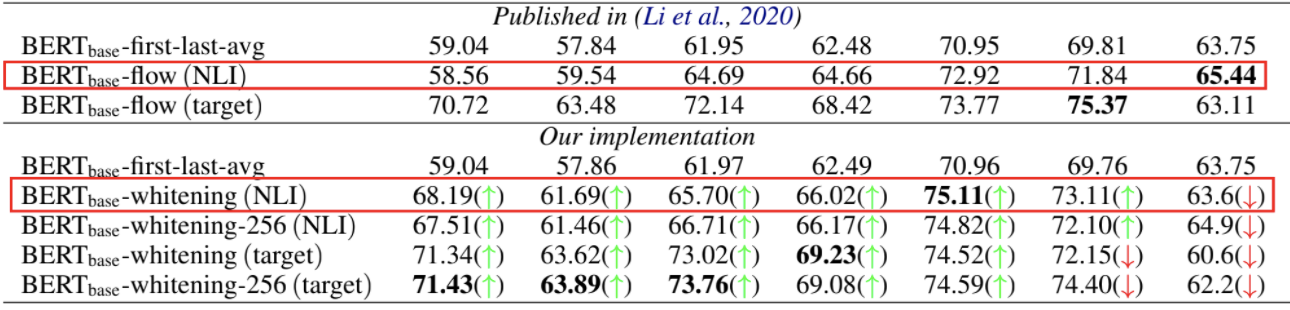
试验结果如下
whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得”降维不掉点”的结果
第一部分主要是正交变换U,U是Σ矩阵SVD分解之后的结果,它能将向量xi−βμ变换成每个分量尽量独立的新向量,并且新向量的每个分量与0的平均波动正好是由Λ1/2的对角线元素来衡量,如果对应的波动很接近于0,那么我们就可以认为它实际就是0,舍去这个分量也不会影响余弦值的计算结果,这就是降维的原理。而由于SVD分解的结果已经提前将Λ从大到小排好了顺序,因此我们可以直接通过保留前k维的操作x̃ i[:k]就可以实现降到k维了。
至于第二部分Λ−γ/2,我们可以理解为当前任务对各向同性的依赖程度,如果γ=1,那么相当于每个分量都是各平权的,这可以作为一个无监督的先验结果,但未必对所有任务都是最优的,所以我们可以通过调节γ来更好地适应当前任务。
参考:当BERT-whitening引入超参数:总有一款适合你



; 三: PROMPT生成句子表示
PROMPT:用Prompt的方式生成句子表示,比如[X] means [MASK],[X]是输入句子,[MASK]是输出的表示,用这个当句子表示
PromptBERT: Improving BERT Sentence Embeddings with Prompts
https://openreview.net/forum?id=7I3KTEhKaAK重新审视了sentence Embedding的问题,指出了之前的 各向同性其实并不影响, 本质是static token Embedding bias导致的。这些就占据了一半的版面。
从图中可以看出,frequency对于token Embedding的分布是有影响的,fre低的时候分布比较分散,而fre大的时候分布比较集中。此外,还可以看出subword和case等信息对于Embedding的分布也是有影响的。
前面分析了bias的影响因素,后续就是如何来消除这些影响因素的干扰
因为有一些词是biased,所以一个naive的想法就是去除这些词,但是如果输入的长度比较短的话,这时候直接删除词语就可以误除一些有意义的词。
作者采用了一种 使用prompt,然后使用mask的token的表征来作为句表征
有两种方式,
第一:直接使用mask对应的hidden state,
第二:将mask可能对应的top-k个token的语义进行加权求和。
考虑到以上的两个缺点,作者使用第一套方案。
作者采用的是 手动设计prompt模板的形式来处理【现在看来略有落后,应该是自动搜索比较好】作者认为,原生BERT表现不好主要是因为词语频率、大小写、subword等token导致的bias,而BERT本身各层Transformer都没有纠正这个问题。通过利用prompt,可以更有效地使用BERT各层中的知识,并且用[MASK]来表示embedding的话,可以避免像以前一样做各种token的平均,从而避免了token引入的偏差。
为了证明上述猜想,PromptBERT在开头做了不少分析:
通过实验,显示embedding层甚至比最后一层的表现要好,证明BERT各层对于文本表示任务效率较低
之前其他工作认为,原生BERT表现差主要是因为表示空间的anisotropy(呈锥形),而anisotropy是由词频这样的偏差引起。但作者通过一些实验,认为anisotropy和bias不是相关的,所以bias的问题仍有待解决
四 对比学习解决各向异性

; 五 ConSERT
论文标题:ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer
ConSERT提出了一种无监督的目标来微调BERT以获得更好的句子表示,另外研究表明Natural Language Inference(NLI)任务能够训练好的句子表示,因此ConSERT也可以采用一些有监督的NLI数据
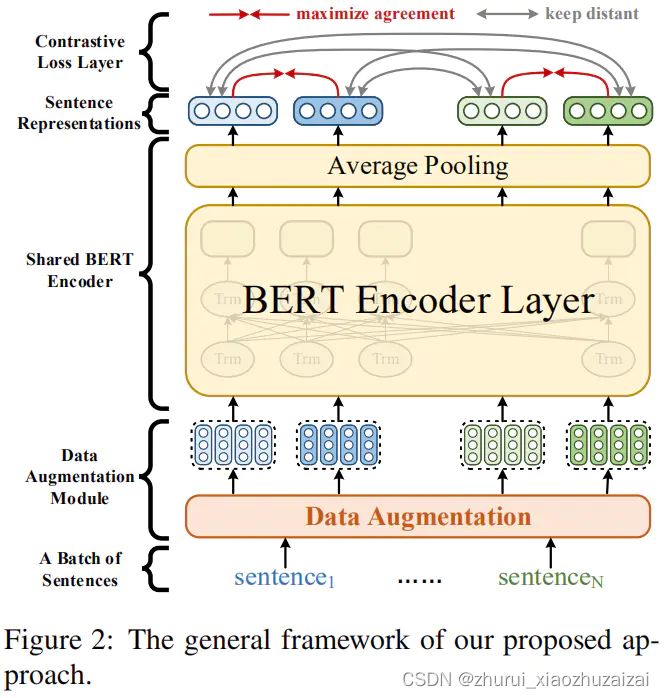
如上图所示,ConSERT主要包括三个部分:
①数据增强模块,生成输入样本在token embedding层的不同view;
②BERT encoder,计算句子表示,本文实验采用最后层的token embedding的平均来获得句子表示;
③对比loss层,它使样本增强之后的view之间相互接近,同一个batch的不同样本的view之间相互远离。
对于每个样本,首先将它通过数据增强模块,在这里使用两种数据增强的变换T1和T2来生成输入样本的两种不同的版本ei=T1(x), ej=T2(x), :然后ei,ej通过BERT并进行平均池化最终获得句子表示:ri,ri
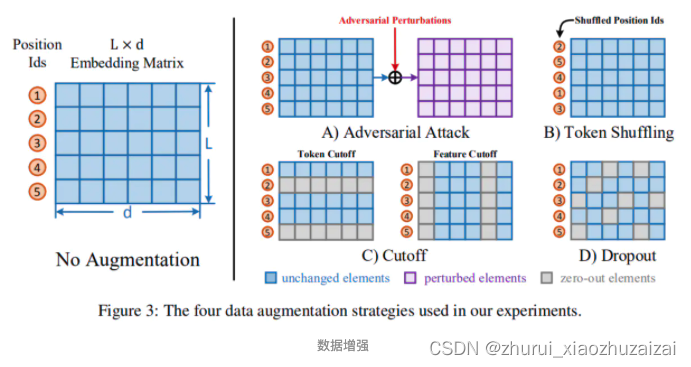
本文采用了四种数据增强的策略,分别是adversarial attack,token shuffling,cutoff 和dropout
Adversarial Attack:为样本添加对抗性的干扰(Adversarial Perturbations)来获得样本的新view,本文采用Fast Gradient Value(FGV)方法,直接使用梯度来计算干扰。注意此策略仅适用于与监督方法联合训练时,因为它依赖监督损失来计算对抗扰动。
Token Shuffling:此方法随机打乱输入序列的token顺序。Transformer架构具有bag-of-words属性,序列的位置信息由位置编码唯一决定,因此在实现时会打乱位置id而不是打乱token的顺序。
Cutoff:这种方法随机抹去特征矩阵的一些token(token cutoff)或者一些特征维度(feature cutoff)或者一些token span(span cutoff)。在本文实验中只采用token cutoff和feature cutoff。
Dropout:依照一定概率随机丢弃token embedding层的一些元素,将它们的值设置为0。这种方法与Cutoff是不同的,因为每个元素被单独考虑。结合NLI监督任务来继续提升ConSERT的性能。
NLI是一个句子对分类任务,主要用来判断两个句子在语义上的关系,一般可以分为:Entailment(蕴含)、Contradiction(矛盾)、Neutral(中立)。分类目标损失可以表示为:
ConSERT采用normalized temperature-scaled cross-entropy loss(NT-Xent)作为对比学习损失函数。
在每个训练的step,会随机从中抽取N个文本作为一个mini-batch,经过数据增强后得到2N个句子表示,
每个数据点被训练来找出它的另一个增强view:在最初做对比学习时,我们的思路局限在有监督对抗扰动和BERT输出后的表示对比上(比如mean、max池化后的对比),但提升一直有限。直到渊蒙发现即使不使用任何方法,直接拉近相同表示、拉远不同表示也会有不错的提升后,我们的重点才又放到了句子前期的扰动上。
参考其他NLP论文的数据增强后,我们在Embedding层使用了:
shuffle:更换position id的顺序
token cutoff:在某个token维度把embedding置为0
feature cutoff:在embedding矩阵中,有768个维度,把某个维度的feature置为0
dropout:顺着cutoff,我们又想到了dropout
再看SimCSE的思路还是很巧妙的,我们只局限在了Embedding layer和Pool layer的扰动上,意识到扰动越提前,越会被网络放大,而没意识到在Transformer的每一层都可以增加扰动,把diff更加放大,提升任务难度。
有意思的是两篇论文得出的结论是不一样的,我们对比后发现Feature cutoff+Shuffle的效果最好(当然我们的dropout其实弱一些)

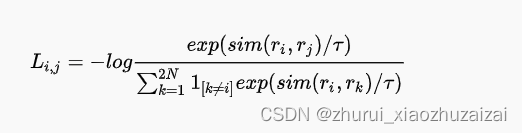

; 六 CoSENT
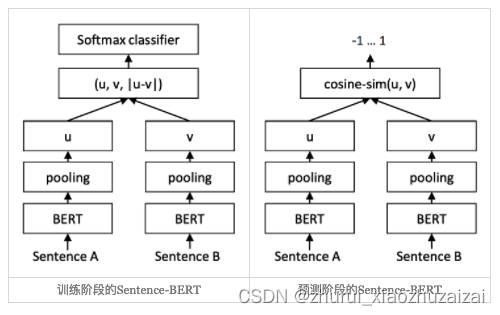
对于句向量训练,Sentence-BERT是最易于实现以及数据构造比较友好并且效果也比较好的方法。
但其训练目标和推理任务的目标是不一致的,它的训练目标是优化一个分类任务,而推理却是计算文本的余弦相似度。
难优化:基于cos(u,v)的loss,直接优化这些目标的实验结果往往特别差(至少明显比InferSent要差),在某些情况下甚至还不如随机初始化的效果。原因:
通常文本匹配语料中标注出来的负样本对都是”困难样本”,常见的正样本对=1、负样本对=-1;或者正样本对=1、负样本对=0。不管哪一种,负样本对的目标都”过低”了,因为对于”困难样本”来说,虽然语义不同,但依然是”相似”,相似度不至于0甚至-1那么低,如果强行让它们往0、-1学,那么通常的后果就是造成过度学习,从而失去了泛化能力,又或者是优化过于困难,导致根本学不动。
要验证这个结论很简单,只需要把训练集的负样本换成随机采样的样本对(视作更弱的负样本对),然后用上述loss进行训练,就会发现效果反而会变好。如果不改变负样本对,那么缓解这个问题的一个方法是给负样本对设置更高的阈值.这样一来,负样本对的相似度只要低于0.7就不优化了,从而就不那么容易过度学习了。但这仅仅是缓解,效果也很难达到最优,而且如何选取这个阈值依然是比较困难的问题。CoSENT直接优化文本对的余弦相似度同label的差异
CoSENT本质上就是一种新的损失函数,它统计了所有正样本对余弦值与负样本对余弦值的差值同样本标签差值的损失,模型训练的时候就不会崩掉,也能提高文本相似度任务的准确率.代码:https://github.com/bojone/CoSENT/blob/main/accuracy/cosent.py
https://github.com/shawroad/CoSENT_Pytorch训练阶段和推理阶段
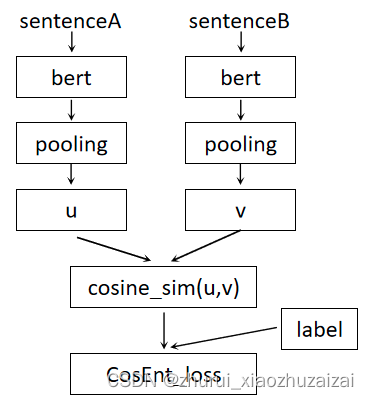
新损失函数
可应用场景
二分类可适用
对于NLI数据而言,它有”蕴含”、”中立”、”矛盾”三种标签,我们自然可以认为两个”蕴含”的句子相似度大于两个”中立”的句子,而两个”中立”的句子相似度大于两个”矛盾”的句子,这样基于这三种标签就可以为NLI的句子对排序了。而有了这个排序后,NLI数据也可以用CoSENT来训练了。类似地,对于STS-B这种本身就是打分的数据,就更适用于CoSENT了,因为打分标签本身就是排序信息。
当然,如果多类别之间没有这种序关系,那就不能用CoSENT了。然而,对于无法构建序关系的多类别句子对数据,InferSent和Sentence-BERT能否出合理的句向量模型,笔者也是持怀疑态度。目前没看到类似的数据集,也就无从验证了。Original: https://blog.csdn.net/weixin_36378508/article/details/121838489
Author: zhurui_xiaozhuzaizai
Title: 句向量表示


原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/556354/
转载文章受原作者版权保护。转载请注明原作者出处!