

Knowledge Graph Embedding via Graph Attenuated Attention Networks
基于图衰减注意网络的知识图嵌入
发表于 Digital Object Identifier 10.1109/ACCESS.2019.2963367
摘要:知识图包含丰富的现实世界的知识,可以为人工智能应用程序提供强有力的支持。知识图的补全已经取得了很大的进展,最先进的模型是基于图卷积神经网络的。这些模型自动提取特征,结合图形模型的特征,生成具有较强表达能力的特征嵌入。但是,这些方法对知识图中的关系路径赋予相同的权值,忽略了相邻节点所呈现的丰富信息,导致三元特征的挖掘不完全。为此,我们提出了一种新的表示方法——图衰减注意网络(Graph Attenuated Attention networks-GAAT),该方法集成了一种衰减注意机制,在不同的关系路径上分配不同的权重,并从邻域获取信息。因此,实体和关系可以在任何邻居中学习。我们的实证研究为衰减注意力模型的有效性提供了深刻的见解,并在两个基准数据集WN18RR和FB15k-237上表明,与最先进的方法相比,我们有显著的改进。
我们的模型引入了注意衰减机制,同时考虑了n-hop邻居,即实体越接近一个给定的实体,获得的注意权重越高。我们将其添加到GAt中,并学习实体和关系的新嵌入。然后用我们的模型分别训练关系嵌入和实体嵌入。
GCNs在图特征提取方面取得了很大的进步。但是仍然存在一个问题,GCNs只关注节点本身,而不考虑它的邻居,这些邻居包含丰富的有价值的信息。图形注意网络(GATs)[13]是对GCNs的进一步改进。GA t强调将不同的重要值分配给不同的节点邻居,而不是像在GCNs中那样为所有邻居节点分配平等的权重。
图注意网络层节点集的输入特征为e= {e1,e2,…,eN}则节点的输出特性为e0= {e’1,e’2,…,e’N},其中ei表示第i个节点的输入嵌入。e’i表示第i个节点的输出嵌入。N表示节点数。节点的注意值可以形式化为
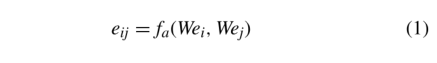

其中,w表示将输入特征映射到高维输出特征空间的参数线性变换矩阵,fa表示一个注意函数。注意值eij反映了边(ei,ej)的重要性,可以用来衡量头部节点ei的的重要性。可以得到如图2所示的注意值。
我们学习每个边的注意力权重,然后根据这些权重从邻居那里收集信息:
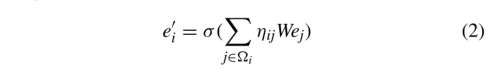
其中,ηij表示相对关注,它是通过softmax函数对所有邻居的值进行计算的。W表示一个线性映射矩阵。执行此操作后,输出节点ei的邻居表示。Ω表示实体ei的邻居集合,R表示连接两者之间的关系集。
为了防止模型的过拟合,我们使用多个独立的不同注意进行注意计算。多头注意结构如图3所示。

头节点(HN)、边节点(E)和尾节点(TN)先进入一个线性变换,然后输入到多头注意。每个header之间的参数都是不共享的,HN, E, TN的线性变换参数是不同的。然后,将m个结果串联起来,利用线性变换得到的值作为多头注意的结果。将多个注意头连接起来的多头注意过程如下图所示
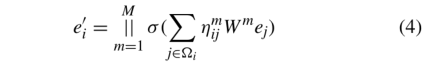
式中||表示串联操作,σ表示非线性激活函数,ηmij表示第m个注意机制所获得的权重,Wm表示第m个注意机制的线性映射矩阵。然后,我们使用平均法得到最终的节点表示,如下所示
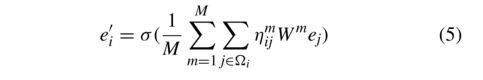
在知识图中,一个实体与给定实体的距离越近,其关注价值就越高。此外,从图4中还可以看出,图中关系的颜色越浅,权重越低,对给定实体的影响越小。在此基础上,我们提出了一种衰减注意机制,对给定实体的相邻节点的注意值分配不同的权重。
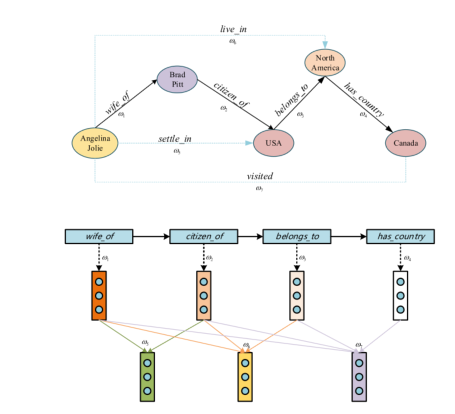
图中显示了我们的图衰减注意层的聚集过程。Wi表示边缘的相对注意值。蓝色虚线代表n-hop邻居的辅助边。当n=4时,节点”Angelina Jolie”的注意权重为ω1+1/2ω2+1/3ω3+1/4ω4。
根据与给定实体越接近,获得的注意权越大的原则,我们定义衰减的注意系数θid,表示给定节点ei的第d个跳跃邻居的衰减。假设给定节点与其d-hop邻居之间的距离为xd,则衰减的注意系数可以形象化为
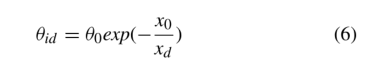
其中θ0为初始衰减注意系数,x0为路径步长参数,默认为1。
我们将衰减注意机制合并到GA t中,形成我们提出的图衰减注意网络模型。该模型通过对不同的关系分配不同的权重,从节点的邻居中收集特征,增强实体和关系嵌入。
最先进的方法集中于实体嵌入,而关系嵌入仅使用TransE训练的初始向量。而关系作为知识图中最重要的组成部分,对知识推理的质量起着决定性的作用。此外,特定关系嵌入可以使表示嵌入包含更多有价值的特征。因此,我们建议细化关系的类型,并使用我们的GAATs模型来学习关系的嵌入。
我们定义初始关系嵌入矩阵R∈RNr×T,其中Nr表示关系个数,T表示嵌入每个关系的初始特征维数,第i行表示第i个关系的嵌入量。经过GAATs层处理后对应的输出矩阵为R’∈RNt×T’,其中Nt表示三元组的个数,T’表示输出特征维数。换句话说,我们独立地学习每个三元组的关系嵌入。
我们使用GAAT模型来学习关系嵌入。在关系的图结构中,我们首先分别计算每个关系的注意值,得到输出关系的嵌入矩阵为R’=R·WR,其中WR∈RT×T’为权矩阵。具体来说,提取图1中的一些子图,我们将关系划分为三个类别,如图5所示。
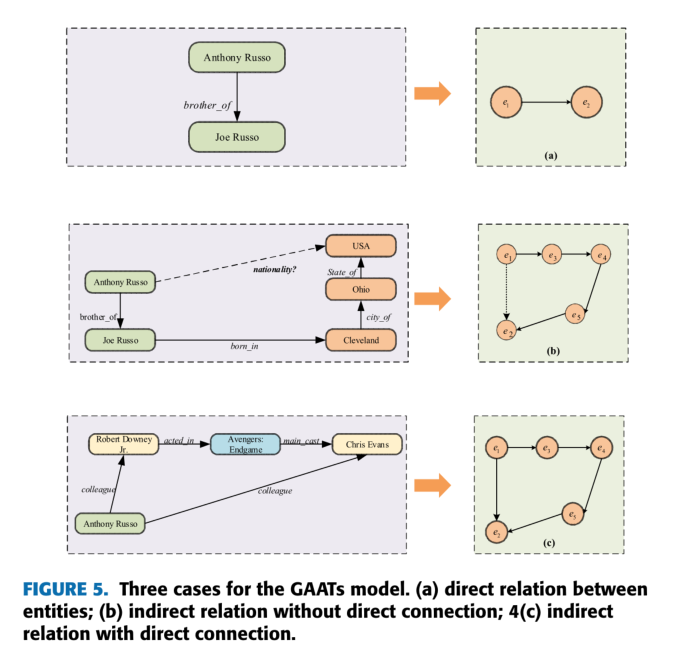
(1)如果两个实体之间有直接关系,如图5(a)所示。然后,关系式为

式中,R’ij表示实体ei和ej之间的关系向量,ηij表示实体ei和ej之间的注意值,R (cor)表示初始关系矩阵对应的行。
(2)如果两个实体之间存在间接连接,但可以通过相邻节点访问,如图5(b)所示。然后,关系式为
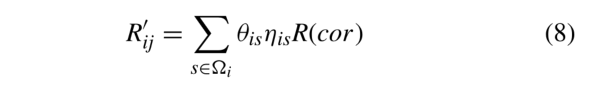
Ωi表示实体ei的邻居集,θis表示实体ei和es之间的衰减注意系数。我们利用衰减注意机制计算邻居的加权注意值,然后用邻居的关系嵌入与注意值的乘积作为关系的表示。
如果两个实体之间存在间接连接,而存在直接连接,如图5©所示。我们利用衰减注意机制计算邻居的注意值,然后利用已有边缘的关系来表示它。然后,关系表示为
如果两个实体之间存在间接连接,并且存在直接连接,如图5©所示。我们利用衰减注意机制计算邻居的注意值,然后利用已有边缘的关系来表示它。然后,关系表示为
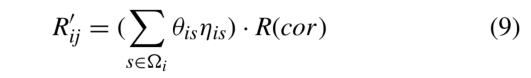
然而,在学习新的关系嵌入时,关系丢失了初始化信息。为了解决这个问题,我们指定两个矩阵,以便将原始的关系嵌入矩阵添加到最终的表示法中
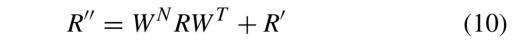
其中WN∈RNt×Nr和WT∈RT×T0表示线性变换矩阵,R”表示最终的关系嵌入矩阵。
实体在知识图中起着重要的作用,实体与关系之间的对应关系在知识图推理中尤为重要。例如,实体Anthoy Russo在不同的三元组中扮演不同的角色,即(brother_of, Joe Russo),(college, Robert Downey Jr .)。GAATs嵌入实体具有以下优点:(1)我们的模型可以解决平移模型灵活性不足的问题。(2)我们的模型可以在不同的关系下嵌入同一实体。(iii)模型利用衰减注意机制计算实体的注意权重,使实体能够携带知识图中关系路径的距离信息,实现具体实体的嵌入,便于处理1-N、N-1、N-M等复杂关系。
我们定义初始实体嵌入矩阵E∈RNe×D,其中Ne表示实体个数,D表示嵌入实体的初始特征维数,第j行表示第j个实体的嵌入。经过GAATs层处理后对应的输出矩阵为E’∈RNe×D’,其中D’表示输出特征维数。
注意值反映了边缘特征的重要性,可以用来衡量头部实体的重要性。首先学习三元组在KGs中的嵌入,将初始化的嵌入实体与关系向量连接,得到三元组的初始表示,如下所示
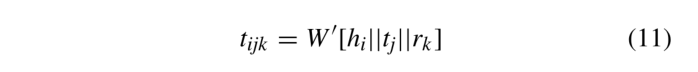
式中,W’∈R1×(2D+T’)表示线性过渡矩阵,tijk表示三重向量(ei,rk,ej), hi,tj,rk分别表示ei,rk,ej的嵌入。然后,我们使用ReLU激活函数学习三重嵌入,以确保三元组注意是非负的。

式中,cijk为变换后的向量,V∈R1×(2D+T’)为线性变换参数矩阵。
应用softmax函数得到实体的n-hop邻居的注意值,从而计算出每三个节点的注意权ηijk。同时,当我们知道每个三元组注意力的权重时,我们添加衰减的注意系数,以确保我们越接近给定的三元组注意力权重增加的越高。ηijk的计算方法如下
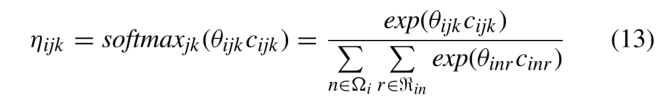
实体ei的新嵌入被更新为三元组注意权重与三元组嵌入乘积的加权和,如下所示
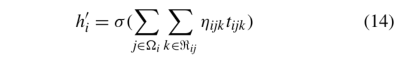
为了提高学习过程的稳定性和学习更多的邻居信息,我们加入了一个类似GATs的多头注意机制。最后,每个实体的邻居表示如下
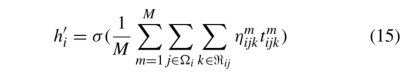
与关系嵌入类似,在学习新实体嵌入时,实体会丢失其初始化信息。为了解决这一缺点,我们指定一个线性过渡矩阵WE∈RT×T’,将原始的关系嵌入矩阵加入到最终表示中,如下所示
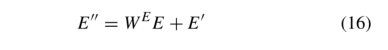
图6所示的图衰减的注意层。在我们的结构中,实体逐层收集邻居的信息。例如,在图4中,实体Brad Pitt从第一层的直接邻居收集信息。然后,它从间接实体美国和直接实体安吉丽娜朱莉在第二层收集信息。一般情况下,n-hop邻居实体可以通过n层模型累积。
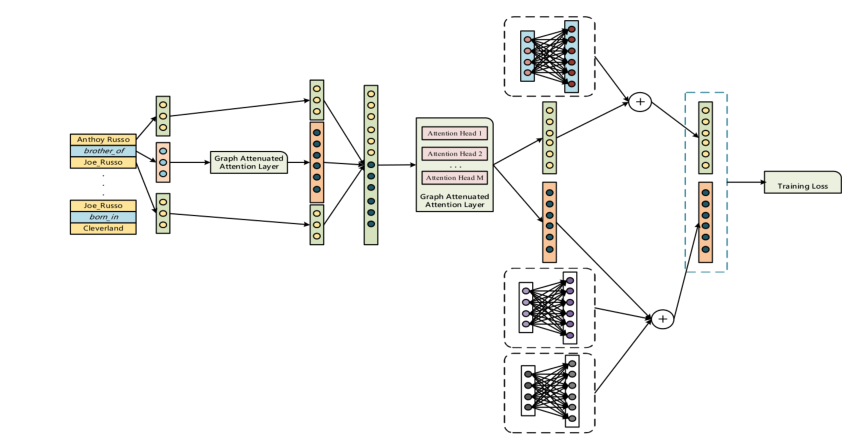
该图显示了我们模型的整个结构。黄色圆圈表示初始实体嵌入,蓝色圆圈表示初始关系嵌入,深黄色和蓝色圆圈分别表示转换实体和关系嵌入。
我们的模型利用了平移模型的评分函数,具体来说,我们尝试通过最小化由d(h+r,t)=|| hi+rk-tj||给出的L1范数不相似性度量来学习实体嵌入和关系嵌入。我们用基于利润率的排名损失来训练我们的模型,作为训练的目标如下
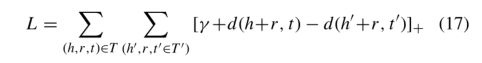
模型解码器使用了CapsE
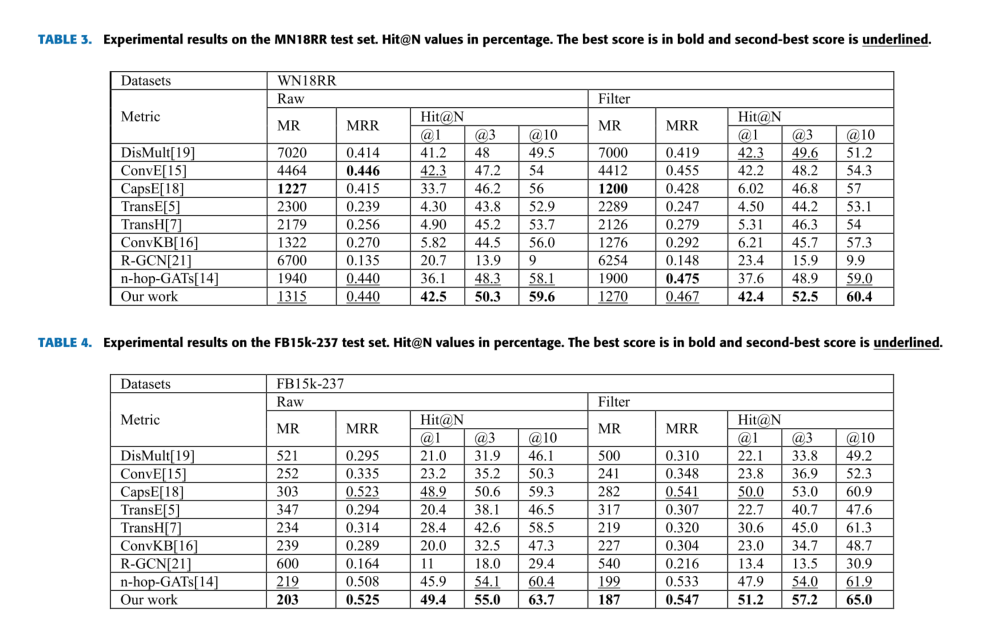
链接预测实验结果:
个人总结:本文提出了一种带距离衰减的图注意力网络,通过节点之间的距离(跳数)来对节点注意力权重进行调整。同时还对每一个三元组的关系都建立了一个不同的嵌入参数,再对节点的每一条路径进行attention后与原向量加权相加得到新嵌入,但文章还是仅仅对实体进行了处理,没有对关系进行处理。
Original: https://blog.csdn.net/qq_41669355/article/details/121497162
Author: 勤劳的复读机
Title: 论文阅读 Knowledge Graph Embedding via Graph Attenuated Attention Networks
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/556304/
转载文章受原作者版权保护。转载请注明原作者出处!