

Bridging the Structural Gap Between Encoding and Decoding for Data-To-Text Generation
- 现有模型存在的问题
- Contribution
- 问题定义
* - Graph Representation and Encoding
- Planning Creation and Encoding
- Decoding
- Experiments
- Experiments on Text Generation
- Future Work
现有模型存在的问题
在生成过程中融合结构信息,将sequential encoder替换为graph encoder,例如GCN,导致Graph2Seq模型在某些任务上比Seq2Seq出色,不过这种结构增加了encoder和decoder之间的结构差异。这种结构差异增加了在source和target之间对齐的难度,对齐即生成文本和图结构上文本的对应关系。在机器翻译过程中,pre-reordering the soure words有助于提高翻译质量。
Contribution
提出一种双编码模型来缩小结构化图和非结构文本之间的结构上的差距。
提出一种 neural planner
实现显示我们的方法比所有baseline都出色
问题定义
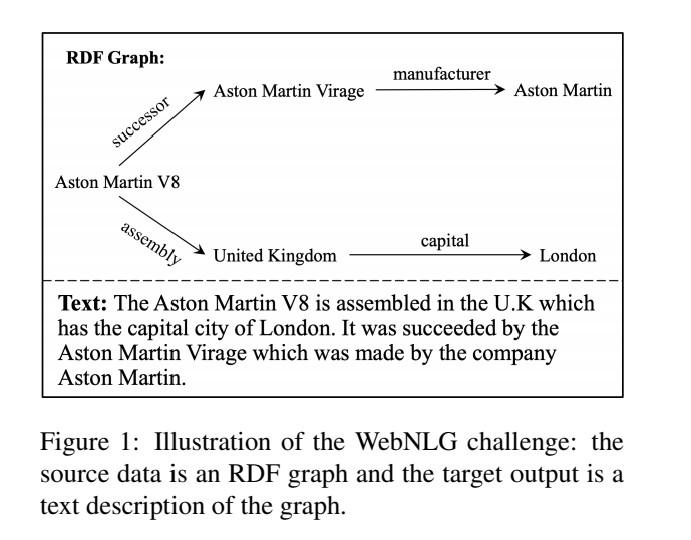
给出RDF数据 N-triples,根据给出的三元组输出一段描述该图中事实的自然语言文本。
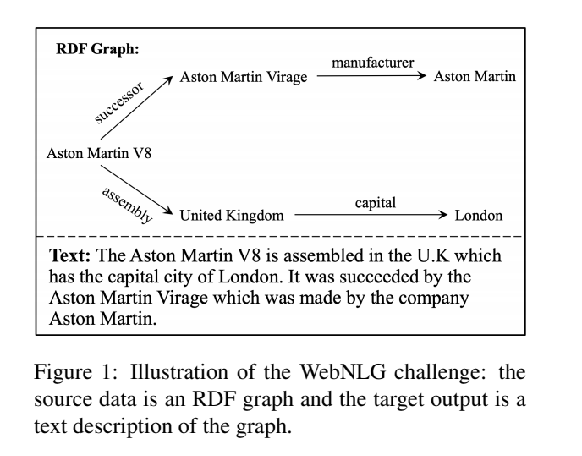

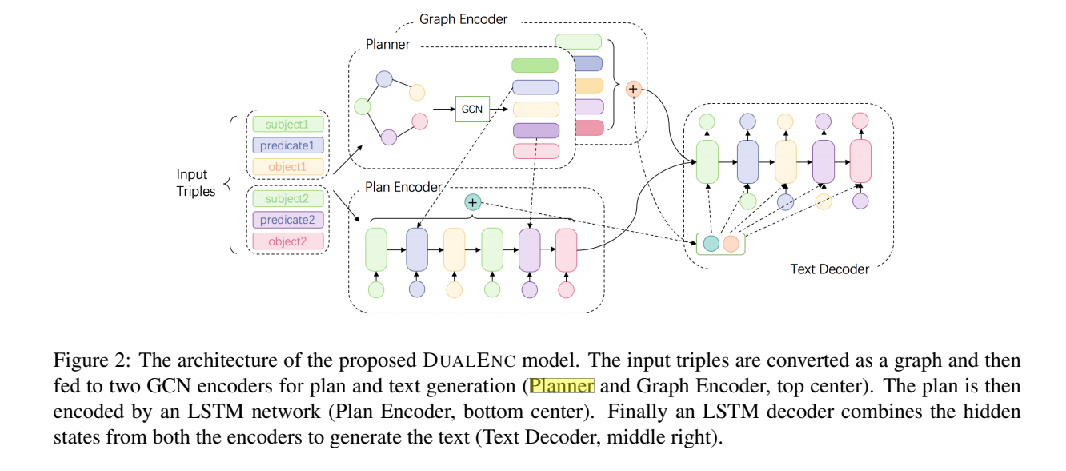
Dual Encoding Model
1.捕获图结构信息 采用GCN encoder
2.plan encoder促使输入输出之间的信息对齐:应用于另一个GCN,序列化并重新排列图中的node作为一个中间plan,然后将这个plan传入LSTM encoder。
最后用一个LSTM decoder 综合两个encoder的上下文表示,生成输出文本。其中,graph和plan都是相同数据的不同表示,对他们进行两次独立的编码,为decoder提供互补信息。
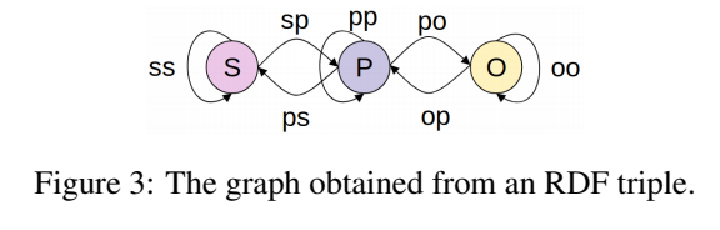
; Graph Representation and Encoding
改变图的结构,将entities和predicates作为node,s和o通过entity mentions辨别,p通过ID辨别。
相同提及的两个entity,即使来自不同的triples,也作为相同的node。想利用predicates来区分不同的triples,
两个相同提及的predicates也作为不同的node。
重新定义了七种edge
s->p p->s
o->p p->o
s,p,o的三种self-loop n->n
在建立图之后,利用R-GCN编码
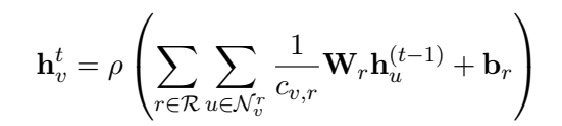
Planning Creation and Encoding
目的:弥补结构性图和非结构性文本之间的差距,输出结果与谓词的顺序有关。
首先利用RGCN的encoder来获取每个node的表示。然而,在获取谓词的表示时为输入特征X额外附加两位。其中一个表示当前predicates是否被访问,另一个表示是否最后一个也被访问完。
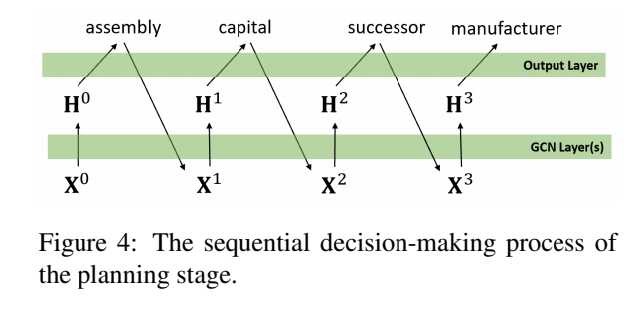
plan生成作为顺序决策过程,将选择谓词作为分类任务。每一次选择后修改附加两位的值,通过GCN计算表示,是在剩余未访问的谓词中选择。

在决定了输入predicates的顺序后,我们通过添加对应的subject和object完成plan。为了获取更好的语义角色信息,区分subject/predicate/object,在S,P,O之前都添加分隔符。最后用LSTM进行编码plan,LSTM捕获序列信息。

; Decoding
an LSTM-based decoder with an attention and copy mechanism
定义了两种decoder策略输入上下文
PLANENC:only use hidden states of the plan encoder as context .
DUALENC: to incorporate the information from both the graph and the plan.
DUALENC:

Experiments
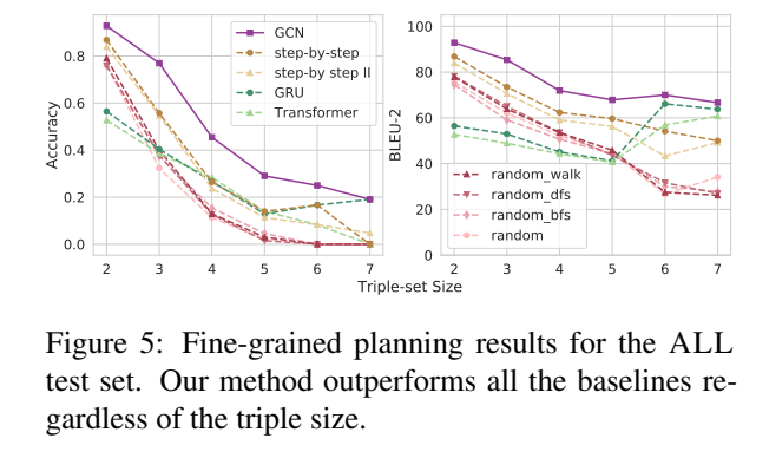
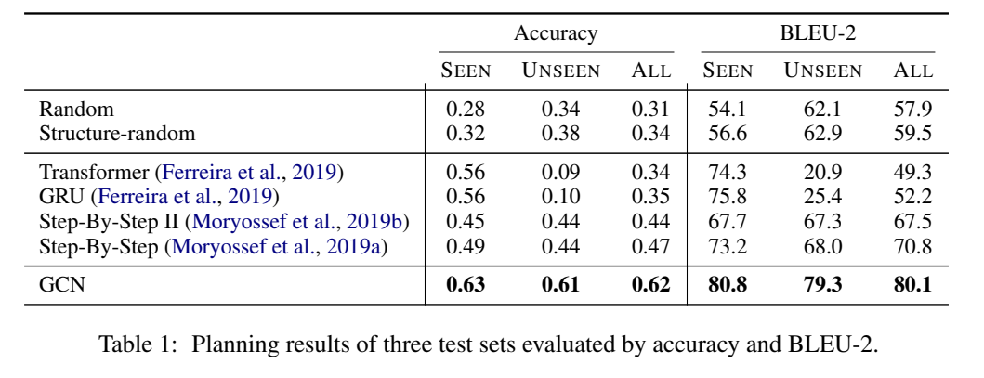
对Planner和总体生成系统进行评估。
DataSet:WebNLG
对于每一个样本,输入为N-triples from DBPedia,最多到达7个。输出是对三元组展示的文本描述。每一个三元组集还配有人工生成的参考文本,最多达到三个。参考文本和它实现的三元组顺序对应。用于训练和评估Planner。
总体数据集包含9674个三元组集合,25298个参考文本。测试集中包含两个子集,Seen指训练时模型使用过的,Unseen指训练时模型未使用过的,用来评估模型的泛化能力。

; Experiments on Text Generation
测试模型提高生成质量的能力
指标:BLEU,METEOR,TER
PLANENC与DUALENC表现相当,我们采用人工评价去进一步比较。
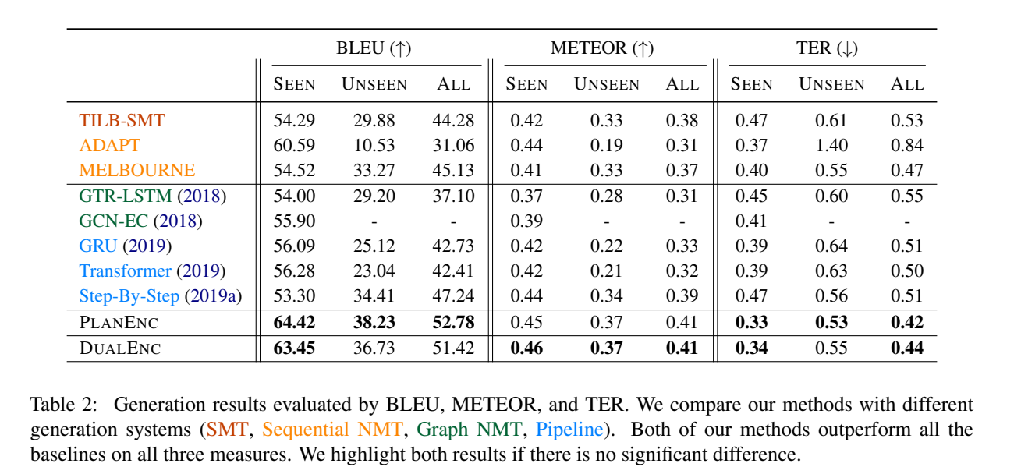
结论:
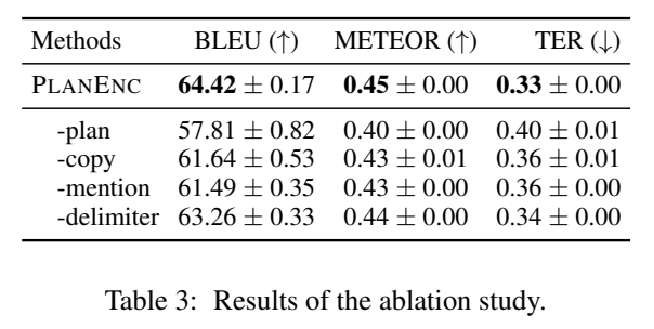
plan的准确性对生成质量至关重要。
copy机制从三元组中复制token,是有助于效果提升的。
entity mention信息能够有助于缓解数据的稀疏性并与复制机制协调。
移除delimiters影响不大。
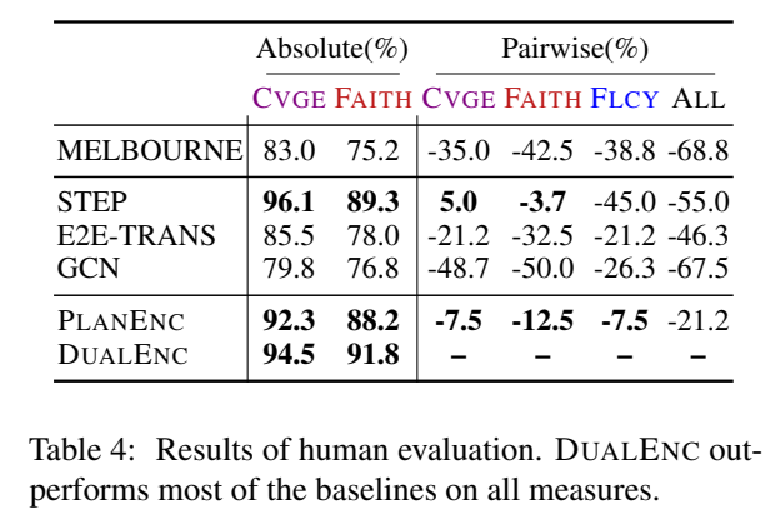
Absolute判断三元组是否被生成文本覆盖或生成文本与原三元组一致。
pairwise是将DualEnc生成文本与其他模型生成的文本进行比较。
Future Work
- 本文中plan部分仅考虑三元组顺序,未来工作可以探索subject和object的顺序。
- 未来工作可以验证该方法在其他data-to-text生成任务的有效性。
Original: https://blog.csdn.net/qq_41894414/article/details/122761584
Author: Terra-incognito
Title: Bridging the Structural Gap Between Encoding and Decoding for Data-To-Text Generation
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/556031/
转载文章受原作者版权保护。转载请注明原作者出处!