

【预训练语言模型】KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
核心要点:
- 不引入任何参数实现知识融合;
- 结合知识表示学习和MLM两个loss进行训练;
- 构建新的benchmark:wikidata5M
简要信息:
序号属性值1模型名称KEPLER2发表位置ACL 20193所属领域自然语言处理、预训练语言模型4研究内容预训练语言模型、知识增强语言模型5核心内容Knowledge-enhanced PLM6GitHub源码
https://github.com/THU-KEG/KEPLER
7论文PDF
https://arxiv.org/pdf/1911.06136
一、动机
- 现如今的预训练语言模型不能有效处理world fact知识;
- 现有的知识图谱包含实体描述信息,可以有效提高实体的语义丰富度;
- 因此我们期望使用实体描述信息来拉近Knowledge Emebdding(KE)和预训练语言模型(PLM)之间的差距
We encode the texts and entities into a unified semantic space with the same PLM as the encoder, and jointly optimize the KE and the masked language modeling (MLM) objectives.
- 现有一些方法直接将预训练好的Knowledge Embedding作为预训练语言模型的初始化,但两个语义空间差异太大,无法直接使用;需要实体链指工具,容易导致误差传播等问题;
二、方法
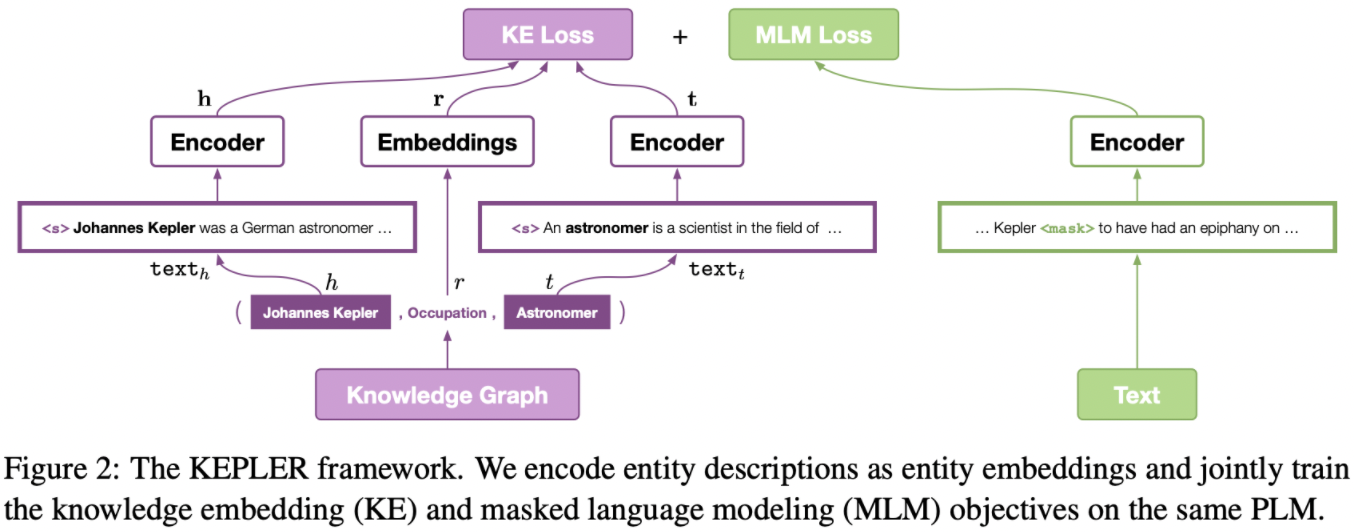

主要目标是将factual knowledge与language representation通过两个训练目标进行融合。
; 2.1 Encoder
直接采用与BERT一致的深层transformer架构,输出的隐状态作为encoder的输出。分词工具则使用RoBERTa的BPE(Byte-Pair Encoding)
不像之前的融合知识图谱的预训练模型,KEPLER不引入任何参数:
we do not modify the Transformer encoder struc- ture to add external entity linkers or knowledge- integration layers
2.2 Knowledge Embedding
知识图谱包含实体和关系边,且以三元组的形式存在(头实体,关系,尾实体)。本文并非先进行预训练,而是直接使用对应的文本的BERT embedding作为初始化。
In KEPLER, instead of using stored embeddings, we encode entities into vectors by using their cor- responding text.
提出三种不同的embedding:
Entity Descriptions as Embeddings
给定一个三元组,头实体和尾实体的描述类文本喂入BERT中获得表征向量,并取 < s > (即[CLS])的表征作为句子向量。关系向量则直接使用初始化的embedding:
根据知识表示学习的预训练Knowledge Embedding的方法,定义能量函数:
d r ( h , t ) = ∣ ∣ h − r + t ∣ ∣ p d_r(\mathbf{h}, \mathbf{t}) = ||\mathbf{h} – \mathbf{r} +\mathbf{t}||_p d r (h ,t )=∣∣h −r +t ∣∣p
以及训练loss:

Entity Embeddings Conditioned on Relations
认为实体embedding应该基于相应的关系。因此对于上面式字中的 h \mathbf{h}h,使用如下进行表示:
h r = E < s > ( t e x t h , r ) \mathbf{h}r = E{~~}(text_{h, r})~~h r =E (t e x t h ,r )
即将头实体和关系的文本描述拼接起来,并获得对应的句子表征。
; m2.3 Masked Language Modeling
遵循BERT(RoBERTa),采用MLM作为另一个预训练的目标函数
2.4 Training Objective
两个loss加和训练:
L = L K E + L M L M \mathcal{L} = \mathcal{L}{KE} + \mathcal{L}{MLM}L =L K E +L M L M
三、Wikidata5M构建
构建新的KG,使得其尽可能规模大,每个实体包含文本描述信息,且可以供推理。
3.1 Data Collection
通过https://www.wikidata.org获取wikidata dump(2019)。根据每个实体,从维基百科网站获取相应的词条,并将对应的文本描述保存下来。去除不包含实体描述信息或描述信息低于5个token的实体。构建relation,可以通过超链接(表格、或显式的三元组等),最终得到4, 594, 485 entities, 822 relations and 20, 624, 575 triplets。与其他KB的对比:


- transductive setting: 在training、dev和test数据集中,实体可以重叠,但是三元组不能重叠;
- inductive setting: 在training、dev和test数据集中,实体和三元组都不能重叠;因此模型需要能够在unseen entity上提升泛化能力
; 四、实验
Baseline
● RoBERTa:直接使用RoBERTa;
● Our RoBERTa:使用RoBERTa-base进行初始化,然后在使用与KEPLER相同语料使用MLM进行训练;
● ERNIE-bert:与KEPLER使用相同的语料和知识图谱进行训练
● KnowBERT-bert:与KEPLER使用相同的语料和知识图谱进行训练
● ERNIE-roberta:
● KnowBERT-roberta:
● MTB(BERT-large):
● MTB(BERT-base)
Evaluate tasks——NLP
● 关系抽取:TACRED、FewRel1.0、FewRel2.0
● 实体类型分类:OpenEntity
● GLUE:
Evaluate tasks——KE
在构建的Wikidata5M上完成link prediction任务;
Original: https://blog.csdn.net/qq_36426650/article/details/122257656
Author: 华师数据学院·王嘉宁
Title: 【预训练语言模型】KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/556023/
转载文章受原作者版权保护。转载请注明原作者出处!