

目录
- 一、pyhanlp
- 二、stanfordnlp
- 三、pyltp
- 四、openNRE
* - 1、安装:我安装到windows上了
- 2、使用
- 五、基于TensorFlow 2自定义NER模型(构建、训练与保存模型范例)
* - 1、BiLSTM+CRF模型
- 2、BERT+CRF(或 softmax)模型
– - 3、BERT+SPAN模型
- 六、SPO三元组抽取 / 关系抽取
* - 1、基于bert4keras(抽取三元组)
- 2、基于DGCNN[CNN、Attention、BiLSTM]
一、pyhanlp
【基于java的,安装使用前必须先安装java环境】
1、安装: pip install pyhanlp
【安装过程中会自动安装jpype1,该模块仅支持到python3.7,所以python3.7以上的安装老是报错。】
2、使用:
1)分词
import pyhanlp
print([i.word for i in pyhanlp.HanLP.segment('我们都是中国人,坚持一个中国原则。')])


二、stanfordnlp
【官方GitHub介绍:https://stanfordnlp.github.io/stanfordnlp/training.html】
1、安装:pip 安装
pip install stanfordnlp --proxy 111.666.88.688:808
2、简单使用
import stanfordnlp
三、pyltp
【学习手札:https://blog.csdn.net/MebiuW/article/details/52496920 】
【基于C++的】
四、openNRE
GitHub:https://github.com/thunlp/OpenNRE#datasets
清华大学自然语言处理与社会人文计算实验室(THUNLP)推出的一款开源的神经网络关系抽取工具包,包括了多款常用的关系抽取模型。
使用wiki80数据集,包含80种关系。(也可以自己训练)
但是都是英文数据集,使用也都是基于英文的……
1、安装:我安装到windows上了
cmd中下载git相关安装文件:
git clone https://github.com/thunlp/OpenNRE.git
安装requirements.txt中的模块(括号中是我安装的模块版本)
torch==1.6.0 (1.9.0)
transformers==3.4.0 (4.21.3)
pytest==5.3.2
scikit-learn==0.22.1 (0.23.2)
scipy==1.4.1 (1.4.1)
nltk>=3.6.4 (3.6.2)
安装openNRE
python setup.py develop
2、使用
【注意】
1)windows在导入包的时候会报错: TypeError: expected str, bytes or os.PathLike object, not NoneType
原因:opennre中的pretrain.py中的第13行在windows运行出错(os.getenv(‘HOME’)获取用户主文件地址,windows没有home地址)。
改为:
default_root_path = os.path.join(str(Path.home()), 'opennre')
2)windows在opennre.get_model(‘wiki80_cnn_softmax’)获取模型时报错: wget不是内部执行命令
原因:wget 是一个Linux环境下用于从万维网上提取文件的工具,windows使用时需要单独安装。
安装:①在网站 https://eternallybored.org/misc/wget/ 上下载windows 上适用的安装包(最新版就可);
②下载完成后解压:比如我下载的是 wget-1.21.3-win64.zip ,解压到 D:\software\wget-1.21.3-win64;
③添加环境变量:比如我的
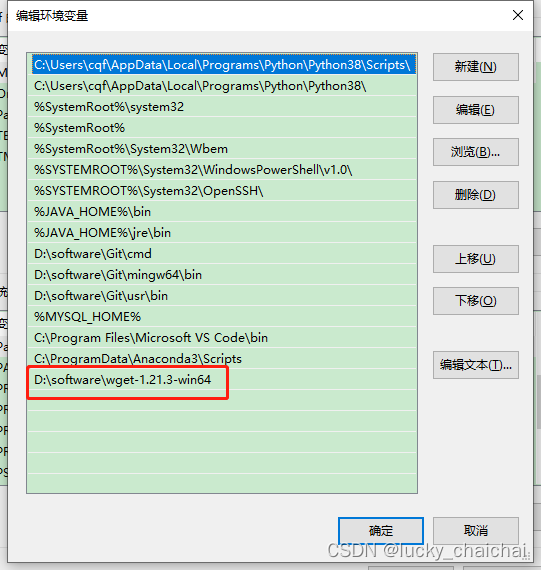
导入模块、加载模型、预测
>>> import opennre
>>> model = opennre.get_model('wiki80_cnn_softmax')
>>> model.infer({'text': 'Huang Xiaoming starred in the TV series "the emperor of Han Dynasty", in which he played Emperor Wu of Han Dynasty.', 'h': {'pos':(0,13)}, 't': {'pos':(41,66)}})
('notable work', 0.96822190284729)
五、基于TensorFlow 2自定义NER模型(构建、训练与保存模型范例)
NER实质:对目标句子序列进行特征向量表示,然后输入模型,预测句子中每个词对应所有 class 的概率,概率最高的即为其标注结果。
环境要求:(keras4bert环境要求后面单独说明)
keras_bert.__version__ = 0.88.0
keras.__version__ = 2.4.3
tf.__version__ = 2.5.0
tfa.__version__ = 0.16.1
transformers.__version__ = 4.9.1
超参:
config_path='data/chinese_L-12_H-768_A-12/bert_config.json'
check_point_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'
seq_len=200
layer_nums=4
training=False
trainable=False
num_label=4
drop_rate=0.3
is_training=True
hidden_size=600
TransBERT_MODEL_NAME='data/bert-base-uncased'
1、BiLSTM+CRF模型
理解说明:
CRF作用:①训练过程中作为损失函数,计算loss;②预测过程中,用于解码,获取得分最高的句子标记结果。
CRF的解码函数:
tfa.text.crf_decode()获取CRF解码结果,即最高分数的句子标记结果,返回结果包括:
① decode_tags: A [batch_size, max_seq_len] matrix, with dtype tf.int32. Contains the highest scoring tag indices.
② best_score: A [batch_size] vector, containing the score of decode_tags.
1、模型构建
import tensorflow as tf
import tensorflow_addons as tfa
class CRF(tf.keras.layers.Layer):
def __init__(self, label_num) -> None:
super().__init__()
self.trans_params = tf.Variable(
tf.random.uniform(shape=(label_num, label_num)), name="transition")
def call(self, inputs, labels, seq_lens):
log_likelihood, self.trans_params = tfa.text.crf_log_likelihood(
inputs,
labels,
seq_lens,
transition_params=self.trans_params)
loss = tf.reduce_mean(-log_likelihood)
return loss
class BiLSTM_CRF_model(tf.keras.Model):
def __init__(self, embedding_dim, vocab_size, hidden_size, label_num) -> None:
super().__init__()
self.embeding_layer=tf.keras.layers.Embedding(input_dim=vocab_size,
output_dim=embedding_dim,
input_length=None,
embeddings_initializer='uniform')
self.bilstm_layer=tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(hidden_size, return_sequences=True),
merge_mode='concat')
self.dense = tf.keras.layers.Dense(label_num)
self.crf_layer=CRF(label_num)
def call(self, input, labels=None, externalEmbed_file=None, training=True):
seq_lens=tf.math.reduce_sum(tf.cast(tf.math.not_equal(input, 0), dtype=tf.int32), axis=-1)
if externalEmbed_file:
x=tf.nn.embedding_lookup(externalEmbed_file, input)
else:
x=self.embeding_layer(input)
x=self.bilstm_layer(x)
logits=self.dense(x)
if training:
labels = tf.convert_to_tensor(labels, dtype=tf.int32)
loss=self.crf_layer(logits, labels, seq_lens)
return loss, logits, seq_lens
else:
return logits, seq_lens
继承tf.keras.Model类构建的模型结构:
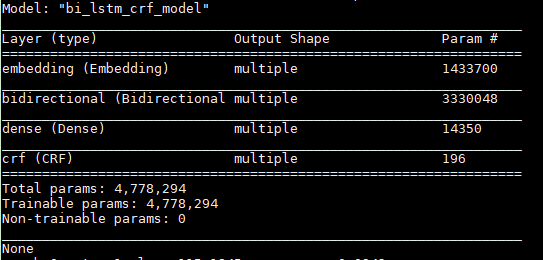
2、模型训练与保存:
def get_acc_one_step(logits, text_lens, labels_batch, model):
'''
【这个计算方式不是很好(一般一个句子中什么都不是的部分占比很大,导致即使全部标记结果都是非实体,那最终准确率也很高),
最后准确率普遍偏高,模型效果不咋地,可以尝试计算精确率、召回率】
计算实体识别准确率: 计算每个句子标注的准确率,然后所有句子准确率相加求平均。
'''
paths = []
accuracy = 0
for logit, text_len, labels in zip(logits, text_lens, labels_batch):
viterbi_path, _ = tfa.text.viterbi_decode(logit[:text_len],
model.get_layer('crf').get_weights()[0]
)
paths.append(viterbi_path)
correct_prediction = tf.equal(
tf.convert_to_tensor(tf.keras.preprocessing.sequence.pad_sequences([viterbi_path], padding='post'),
dtype=tf.int32),
tf.convert_to_tensor(tf.keras.preprocessing.sequence.pad_sequences([labels[:text_len]], padding='post'),
dtype=tf.int32)
)
accuracy = accuracy + tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
accuracy = accuracy / len(paths)
return accuracy
def train_main(vocab_file, tag_file, train_path, output_dir):
train_dataset = tf.data.Dataset.from_tensor_slices((text_sequences, label_sequences))
train_dataset = train_dataset.shuffle(len(text_sequences)).batch(batch_size, drop_remainder=True)
model = BiLSTM_CRF_model(hidden_size = hidden_num, vocab_size = len(vocab2id), label_num= len(tag2id), embedding_dim = embedding_size)
optimizer = tf.keras.optimizers.Adam(lr)
ckpt = tf.train.Checkpoint(optimizer=optimizer, model=model)
ckpt.restore(tf.train.latest_checkpoint(output_dir))
ckpt_manager = tf.train.CheckpointManager(ckpt,
output_dir,
checkpoint_name='bilstm_crf_model.ckpt',
max_to_keep=3)
for epoch in range(10):
for _, (text_batch, labels_batch) in enumerate(train_dataset):
step = step + 1
with tf.GradientTape() as tape:
loss, logits, text_lens = model(text_batch,
labels_batch,
externalEmbed_file=False)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
if step==1:
print(model.summary())
accuracy = get_acc_one_step(logits, text_lens, labels_batch, model)
print('epoch %d, step %d, loss %.4f , accuracy %.4f' % (epoch, step, loss, accuracy))
if accuracy > best_acc:
best_acc = accuracy
ckpt_manager.save()
print("model saved")
if __name__=='__main__':
train_main(vocab_file='data/vocab_file.txt',
tag_file='data/tag_file.txt',
train_path='data/train.txt',
output_dir='checkpoints/')
训练结果:loss值、准确率
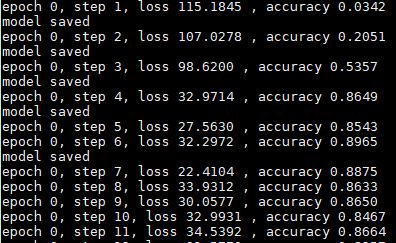
3、使用模型预测:
① 加载训练好的模型参数
② 使用predict()对输入序列预测
③ 基于预测的logit和模型中的转移矩阵,使用tfa.text.viterbi_decode()解码,得到最佳结果路径
def predict_main(vocab_file, tag_file, output_dir):
vocab2id, id2vocab = read_vocab(vocab_file)
tag2id, id2tag = read_vocab(tag_file)
model = BiLSTM_CRF_model(hidden_size = hidden_num,
vocab_size = len(vocab2id),
label_num= len(tag2id),
embedding_dim = embedding_size)
optimizer = tf.keras.optimizers.Adam(lr)
ckpt = tf.train.Checkpoint(optimizer=optimizer, model=model)
ckpt.restore(tf.train.latest_checkpoint(output_dir))
text = input("input:")
dataset = tf.keras.preprocessing.sequence.pad_sequences([[vocab2id.get(char,0) for char in text]], padding='post')
logits, text_lens = model.predict(dataset)
paths = []
for logit, text_len in zip(logits, text_lens):
viterbi_path, _ = tfa.text.viterbi_decode(
logit[:text_len],
model.get_layer('crf').get_weights()[0])
paths.append(viterbi_path)
print('结果路径:',paths)
参考:https://github.com/saiwaiyanyu/bi-lstm-crf-ner-tf2.0
2、BERT+CRF(或 softmax)模型
BERT中包含 四种special token,分别是:
[UNK]:指代在vocab中找不到的字/词
[CLS]:添加在每句句首。对于用于分类的向量,会聚集所有的分类信息
[SEP]:添加在每句句尾
[MASK]:使用[MASK]替换句子中的部分字/词。用于MLM(屏蔽语言模型)。
BERT的 三种输入(可通过模块中的tokenizer处理得到):字向量token_ids,段向量segment_ids、位置向量position_ids
token_ids:使用 vocab 中的字索引表示的向量集合,shape=(batch_size, seq_len)
segment_ids:当每个文本只有一个句子时,则segment_ids为0向量,shape=(batch_size, seq_len);BERT处理句子对的分类任务时(就是判断两个文本是否是语义相似的),会将两个句子拼接作为输入,此时segment_ids为前一句的0向量和后一句的1向量拼接而成
position_ids:对应位置下标,由于是固定的,会在模型内部生成,不需要手动再输入一遍
1、使用keras_bert:
tokenizer数据处理部分:
from keras_bert import Tokenizer
token2id={}
vocab_file=open('data/chinese_L-12_H-768_A-12/vocab.txt', 'r', encoding='utf-8')
for w in vocab_file.readlines():
w=w.strip()
token2id[w]=len(token2id)
tokenizer=Tokenizer(token2id)
r=tokenizer.tokenize('我是中糹国人!')
print(r)
r_encode=tokenizer.encode('我是糹中国人!')
【 注意】当输入两个文本时:(与bert4keras很类似)
r=tokenizer.tokenize('我是中糹国人!', second='谁不说俺家乡好,啊啊啊啊!')
print(r)
r_encode=tokenizer.encode('我是糹中国人!', second='谁不说俺家乡好,啊啊啊啊!')
print(r_encode)
结果:

方式一、模型构建代码:继承tf.keras.Model()
bert_model( [tokenid_tensor, segmentid_tensor] )
class NonMaskingLayer(tf.keras.layers.Layer):
def __init__(self, **kwargs):
self.supports_masking = True
super(NonMaskingLayer, self).__init__(**kwargs)
def build(self, input_shape):
pass
def compute_mask(self, inputs, input_mask=None):
return None
def call(self, x, mask=None):
return x
class BertCrf(tf.keras.Model):
def __init__(self,
seq_len=200,
bertOut_layer_nums=4,
bertTraining=False,
bertTrainable=False,
num_label=4,
drop_rate=0.3,
is_training=True,
config_path='data/chinese_L-12_H-768_A-12/bert_config.json',
check_point_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'):
super(BertCrf, self).__init__()
self.config_path=config_path
self.check_point_path=check_point_path
self.seq_len=seq_len
self.layer_nums=bertOut_layer_nums
self.training=bertTraining
self.trainable=bertTrainable
self.num_label=num_label
self.drop_rate=drop_rate
self.is_training=is_training
self.bert_model=keras_bert.load_trained_model_from_checkpoint(
self.config_path,
self.check_point_path,
seq_len=self.seq_len,
output_layer_num=self.layer_nums,
training=self.training,
trainable=self.trainable)
self.NonMask_layer=NonMaskingLayer()
self.Dropout_layer=tf.keras.layers.Dropout(self.drop_rate)
self.Dense_layer=tf.keras.layers.Dense(self.num_label)
self.crf_layer=CRF(self.num_label)
def call(self, input, labels=None, train=False):
'''
input: [padded_tokenid_tensor, padded_segmentid_tensor], tensor shape=[batch, seq_len]
'''
seq_reallens=tf.math.reduce_sum(tf.cast(tf.math.not_equal(input[0], 0), dtype=tf.int32), axis=-1)
out_put=self.bert_model(input)
out_put=self.NonMask_layer(out_put)
out_put=self.Dropout_layer(out_put)
logits=self.Dense_layer(out_put)
if train:
labels=tf.convert_to_tensor(labels, dtype=tf.int32)
loss=self.crf_layer(logits, labels, seq_reallens)
return loss, logits, seq_reallens
else:
return logits, seq_reallens
模型结构:
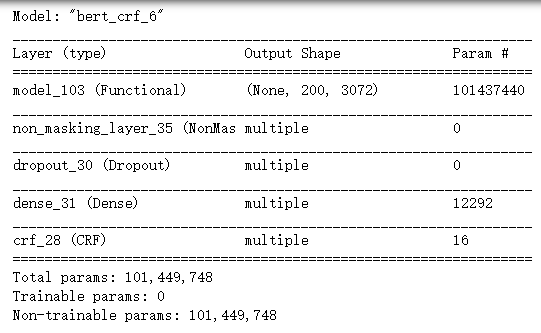
方式二、模型构建代码:链式(串联)方式
bert_model.inputs , bert_model.output
class MyBertCrfModel:
def __init__(self,
seq_len=200,
bertOut_layer_nums=4,
bertTraining=False,
bertTrainable=False,
num_label=4,
drop_rate=0.3,
is_training=True,
config_path='data/chinese_L-12_H-768_A-12/bert_config.json',
check_point_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'):
self.config_path=config_path
self.check_point_path=check_point_path
self.seq_len=seq_len
self.layer_nums=bertOut_layer_nums
self.training=bertTraining
self.trainable=bertTrainable
self.num_label=num_label
self.drop_rate=drop_rate
self.is_training=is_training
def build_model(self):
'''
这种方式构建的模型,可以将BERT详细的模型结构打印出来。
返回模型对象,后续直接使用model.compile()、 model.fit()、model.save()、 model.predict()编译、训练、保存和预测
model调用时,有四个输入[input1, input2, input3, input4], 分别对应:
input1:bert的输入1,padded_tokenid_tensor,shape=[batch, seq_len]
input2:bert的输入2,padded_segmentid_tensor,shape=[batch, seq_len],即段向量,用来区分两个句子,用于句子级别的Mask任务,第一句话标记0(两个句子时,另一句为1)
input3:crf层要用的labels, [batch, seq_len]
input4:crf层要用的各句子真实长度, [batch]
'''
label_input = tf.keras.layers.Input(shape=(self.seq_len,), name='target_ids', dtype='int32')
seq_reallens = tf.keras.layers.Input(shape=(), name='input_reallens', dtype='int32')
bert_model = keras_bert.load_trained_model_from_checkpoint(self.config_path,
self.check_point_path,
seq_len=self.seq_len,
output_layer_num=self.layer_nums,
training=self.training,
trainable=self.trainable)
out_put=NonMaskingLayer()(bert_model.output)
out_put=tf.keras.layers.Dropout(self.drop_rate)(out_put, training=self.is_training)
logits=tf.keras.layers.Dense(self.num_label)(out_put)
loss=CRF(self.num_label)(logits, label_input, seq_reallens)
model=tf.keras.Model([bert_model.inputs[0],bert_model.inputs[1],label_input, seq_reallens], loss)
model.summary()
return model
模型结构图:

2、使用transformers
from transformers import BertTokenizer, TFBertModel, BertConfig
构建BERT+BiLSTM模型:
def build_model_tran():
label_input = tf.keras.layers.Input(shape=(seq_len,), name='target_ids', dtype='int32')
seq_reallens = tf.keras.layers.Input(shape=(), name='input_reallens', dtype='int32')
input_ids=tf.keras.layers.Input(shape=(seq_len,), name='input_ids', dtype='int32')
token_type_ids=tf.keras.layers.Input(shape=(seq_len,), name='token_type_ids', dtype='int32')
attention_masks=tf.keras.layers.Input(shape=(seq_len,), name='attention_masks', dtype='int32')
bert_input=[input_ids, token_type_ids, attention_masks]
bert_configs = BertConfig.from_pretrained(TransBERT_MODEL_NAME, num_labels=num_label)
bert_model = TFBertModel.from_pretrained(TransBERT_MODEL_NAME,
config=bert_configs,
from_pt=True)
bert_model.trainable = False
sequence_output = bert_model(bert_input)[0]
output=tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(hidden_size, return_sequences=True),
merge_mode='concat')(sequence_output)
output=tf.keras.layers.Dropout(drop_rate)(output)
logits=tf.keras.layers.Dense(num_label)(output)
loss=CRF(num_label)(logits, label_input, seq_reallens)
model=tf.keras.Model(bert_input+[label_input, seq_reallens], logits)
model.summary()
return model
model=build_model_tran()
模型层次结构:
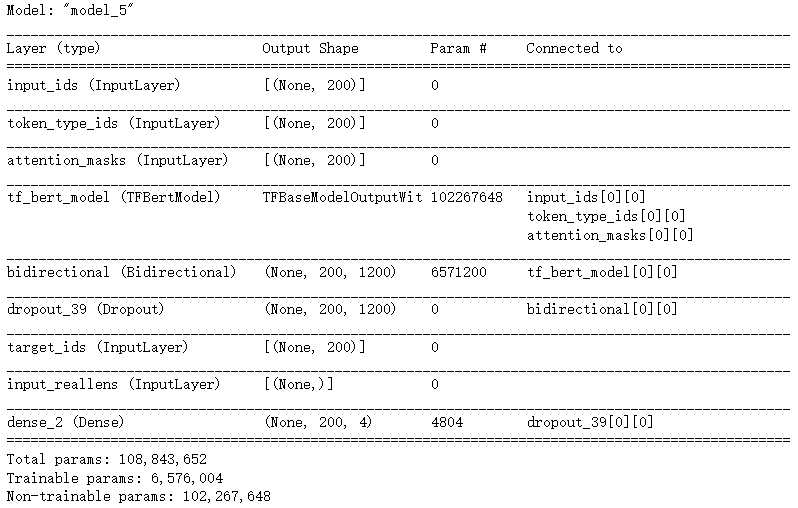
3、BERT+SPAN模型
未完待续
六、SPO三元组抽取 / 关系抽取
1、基于bert4keras(抽取三元组)
任务实质:p是给定的几种S-O之间的关系,其实任务实质就是抽取句子中S和O并确定他们之间关系属于哪一种。(实体识别 + 关系分类)
效果较差的一般思路:
①s、p、o作为整体的序列标注来搞;
②先通过序列标注识别出实体s、o,然后使用分类模型对s-o进行关系分类。
思路主干:先构建S预测模型 subject_model,预测 S ,然后构建P、O预测模型 object_model,共享 S 特征向量,与随机选择的 Si 的特征向量共同预测 Si 对应的所有 p、o。
环境要求:
'''
苏神bert4keras开发环境:tf 1.14 + keras 2.3.1
python3.8.0
'''
bert4keras.__version = 0.11.3
tensorflow.__version__ = 2.2.0(最好) / 2.5.0
keras.__version__ = 2.3.1
模块导入:
import json
import numpy as np
from tqdm import tqdm
import os
os.environ["TF_KERAS"] = '1'
from bert4keras.backend import keras, K, batch_gather
from bert4keras.layers import Loss
from bert4keras.layers import LayerNormalization
from bert4keras.tokenizers import Tokenizer
from bert4keras.models import build_transformer_model
from bert4keras.optimizers import Adam, extend_with_exponential_moving_average
from bert4keras.snippets import sequence_padding, DataGenerator
from bert4keras.snippets import open, to_array
from tensorflow.keras.layers import Input, Dense, Lambda, Reshape
from tensorflow.keras.models import Model
config_path='data/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path='data/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = 'data/chinese_L-12_H-768_A-12/vocab.txt'
基于bert4keras的tokenizer:
tokenizer处理部分:将字符转换为index表示,101是[CLS],102是[SEP]
tokenizer = Tokenizer(dict_path, do_lower_case=True)
token_ids, segment_ids = tokenizer.encode('查尔斯·阿兰基斯(Charles Aránguiz),1989年4月17日出生于智利圣地亚哥,智利职业足球运动员,司职中场,效力于德国足球甲级联赛勒沃库森足球俱乐部',
maxlen=maxlen)
print(token_ids, '\n', segment_ids)
结果:

【注意】当输入两个文本时:
tokenizer = Tokenizer(dict_path, do_lower_case=True)
token_ids, segment_ids = tokenizer.encode('查尔斯·阿兰基斯(Charles Aránguiz),1989年4月17日出生于智利圣地亚哥,智利职业足球运动员,司职中场,效力于德国足球甲级联赛勒沃库森足球俱乐部',
second_text = '中国是社会主义社会,坚持共产党的领导,为人民服务,必须是为人民。',
maxlen=maxlen)
print(token_ids, '\n', segment_ids)
结果:

基于bert三元组抽取联合模型逻辑图(参考苏神抽取三元组):
数据集(batch)处理:一个text中s单独用首(1,0)尾(0,1)二维向量表示(shape = [token_ids_len, 2]),o、p统一用三维向量表示(shape = [token_ids_len, num_p, 2])
注意:s、o的label分开标注,防止s、o出现重叠的极端情况:如《鲁迅自传》由江苏文艺出版社出版,包含三元组 (鲁迅自传, 作者, 鲁迅) 。


调用bert模型(bert4keras加载的bert模型从0层开始,最后一层(11层)是最后一个encoder的Normalization层);
构建三元组模型代码(苏神GitHub完整代码):
class TotalLoss(Loss):
"""subject_loss与object_loss之和,都是二分类交叉熵
"""
def compute_loss(self, inputs, mask=None):
subject_labels, object_labels = inputs[:2]
subject_preds, object_preds, _ = inputs[2:]
if mask[4] is None:
mask = 1.0
else:
mask = K.cast(mask[4], K.floatx())
subject_loss = K.binary_crossentropy(subject_labels, subject_preds)
subject_loss = K.mean(subject_loss, 2)
subject_loss = K.sum(subject_loss * mask) / K.sum(mask)
object_loss = K.binary_crossentropy(object_labels, object_preds)
object_loss = K.sum(K.mean(object_loss, 3), 2)
object_loss = K.sum(object_loss * mask) / K.sum(mask)
return subject_loss + object_loss
class Nre_model:
def __init__(self, relation_num = 20, maxlen = 128, batch_size = 64,
config_path = 'data/chinese_L-12_H-768_A-12/bert_config.json',
checkpoint_path = 'data/chinese_L-12_H-768_A-12/bert_model.ckpt',
dict_path = 'data/chinese_L-12_H-768_A-12/vocab.txt') -> None:
self.relation_num = relation_num
self.maxlen = maxlen
self.batch_size = batch_size
self.config_path = config_path
self.checkpoint_path = checkpoint_path
self.dict_path = dict_path
subject_labels = Input(shape=(None, 2), name='Subject-Labels')
subject_ids = Input(shape=(2,), name='Subject-Ids')
object_labels = Input(shape=(None, relation_num, 2), name='Object-Labels')
bert = build_transformer_model(
config_path=config_path,
checkpoint_path=checkpoint_path,
return_keras_model=False,
)
output = Dense(
units=2, activation='sigmoid', kernel_initializer=bert.initializer
)(bert.model.output)
subject_preds = Lambda(lambda x: x**2)(output)
self.subject_model = Model(bert.model.inputs, subject_preds)
output = bert.model.layers[-2].get_output_at(-1)
subject = Lambda(self._extract_subject)([output, subject_ids])
output = LayerNormalization(conditional=True)([output, subject])
output = Dense(
units=relation_num * 2,
activation='sigmoid',
kernel_initializer=bert.initializer
)(output)
output = Lambda(lambda x: x**4)(output)
object_preds = Reshape((-1, relation_num, 2))(output)
self.object_model = Model(bert.model.inputs + [subject_ids], object_preds)
subject_preds, object_preds = TotalLoss([2, 3])([
subject_labels, object_labels, subject_preds, object_preds,
bert.model.output
])
self.train_model = Model(
bert.model.inputs + [subject_labels, subject_ids, object_labels],
[subject_preds, object_preds]
)
optimizer = Adam(learning_rate=1e-4)
self.train_model.compile(optimizer=optimizer)
def _extract_subject(self, inputs):
"""根据subject_ids从output中取出subject的向量表征
"""
output, subject_ids = inputs
start = batch_gather(output, subject_ids[:, :1])
end = batch_gather(output, subject_ids[:, 1:])
subject = K.concatenate([start, end], 2)
return subject[:, 0]
模型保存说明:使用keras中模型保存和加载
subject_model.save('best_subject_model.model')
from keras.models import load_model
my_model = load_model('best_subject_model.model')
subject_model.save_weights('best_subject_weight.weight')
object_model.save_weights('best_oubject_weight.weight')
subject_model.load_weights('best_subject_weight.weight')
2、基于DGCNN[CNN、Attention、BiLSTM]
参考代码:苏神解读
模块导入:
'''keras == 2.2.4
tensorflow == 1.8.0
python3.6.8'''
from keras.layers import *
from keras.models import Model
import keras.backend as K
from keras.callbacks import Callback
from keras.optimizers import Adam
数据标签处理过程:

模型结构:
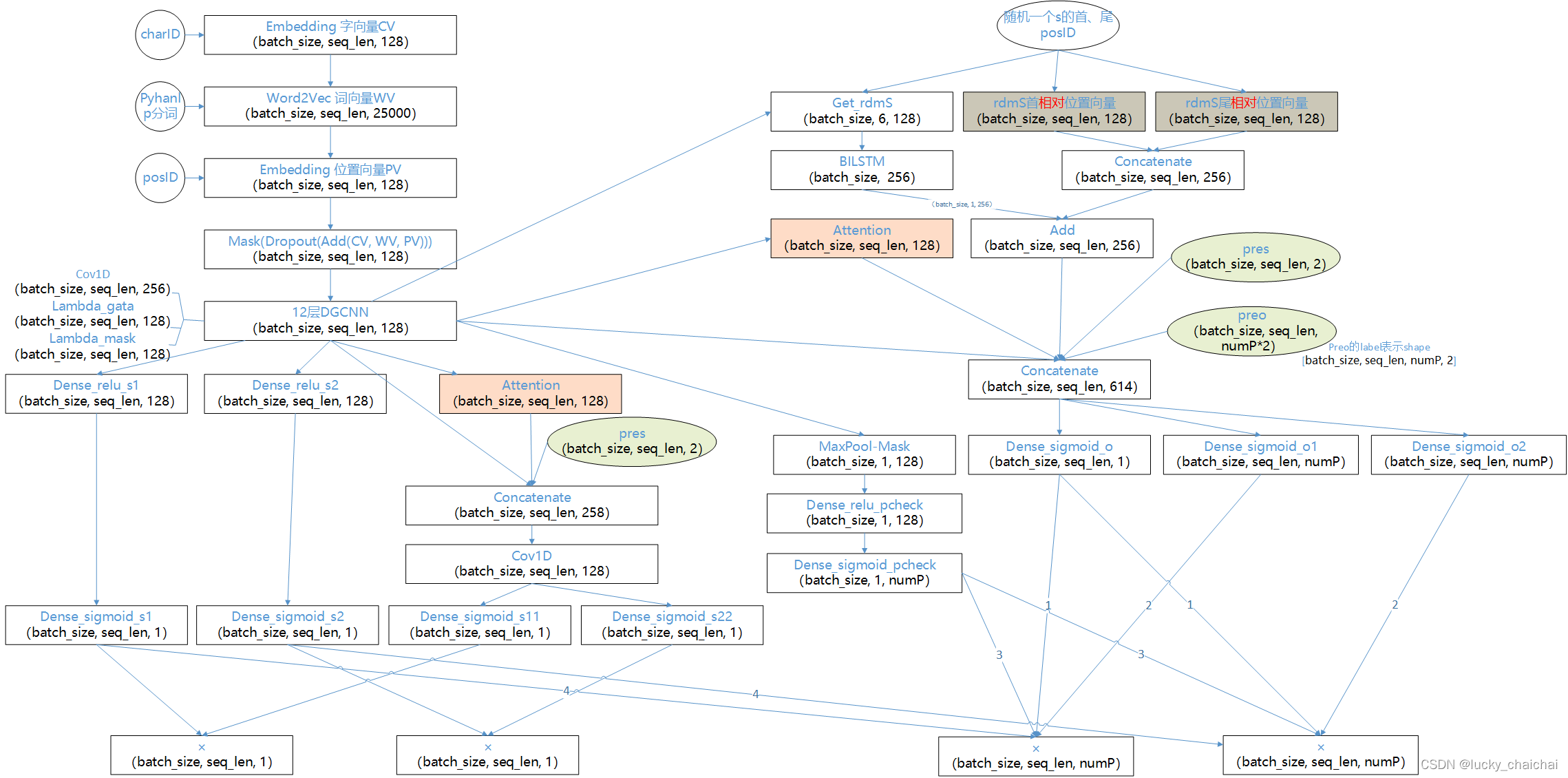
相关代码:
未完待续……
Original: https://blog.csdn.net/lucky_chaichai/article/details/122602670
Author: lucky_chaichai
Title: 知识图谱中“三元组”抽取——Python中模型总结实战(基于TensorFlow2.5)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/555940/
转载文章受原作者版权保护。转载请注明原作者出处!