

Video Visual Relation Detection via Iterative Inference
基于迭代推理的视频视觉关系检测。
论文地址:https://dl.acm.org/doi/abs/10.1145/3474085.3475263
主要贡献
- 提出了一种迭代关系推理方法,在其他两个组件的基础上逐步细化每个组件的类,可以利用关系组件的 相互依赖性来实现更好的视觉关系识别;
- 提出了一种新的训练方法来训练优先预测器,以便从可能正确的三元组合中更好地 学习依赖性知识;
- 提出了一个改进的VidVRD架构 VidVRD- II (Iterative Inference),稳定且显著地改善了ImageNet-VidVRD上的结果,并在具有挑战性的VidOR数据集上实现了具有竞争力的性能。
实现背景
现有的VidVRD方法对这三个关系组件进行了 独立或级联的分类,未能充分利用它们之间的 依赖性。为了利用这种 相互依赖性来解决视频中视觉关系识别的挑战,本文提出了一种新的迭代关系推理方法用于VidVRD,能够根据学习到的依赖关系和其他两个组件的预测,逐步细化每个组件。
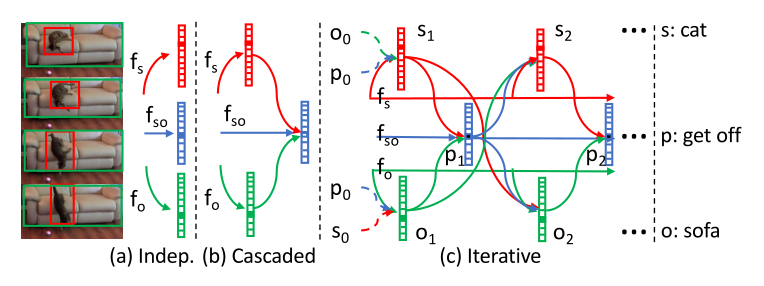

如上图所示,a是主谓宾的独立分类,但其很难学习视觉外观特征;b是级联分类,其严重依赖主客体的分类,视频的主客体分类质量并不高,所以效果并不好;c是本文提出的迭代关系推理,主客体和谓词将通过利用它们之间的依赖关系在每次迭代中交替地更新。
; 现有vidvrd任务的困难
- 谓词表示的方差较大,潜在的模式学习困难,如”walk past”很难区分;
- 视频中的对象实体姿势可能会频繁变化,且视频可能会有运动模糊、遮挡和光照问题,难以分类;
- 受到桶效应的影响很大,任何部分只要有一个错误就会产生很大影响。
具体实现
1. 迭代关系推理
将联合概率分解为三个条件概率:P ( s ∣ f s , p , o ) P ( p ∣ f r , s , o ) P ( o ∣ f o , s , p ) ( 1 ) P(s|f_s,p,o)P(p|f_r,s,o)P(o|f_o,s,p) (1)P (s ∣f s ,p ,o )P (p ∣f r ,s ,o )P (o ∣f o ,s ,p )(1 )
任何两个组件的类都暗示着对第三个组件的类有一定的偏好,因此可以在视觉信息不足或不明确时帮助进行推断。
为了对上述条件概率建模,为每个关系组件使用三个分类器,每个分类器由一个 视觉预测器和一个 优先预测器组成。
- 视觉预测器可以是识别主客体和谓词视觉模式的任何深度神经网络。为了简单起见,使用一个单一的线性层。
- 另一方面,引入了优先预测器,以可学习的依赖张量为基础,以其他两个变量的值为条件,细化一个变量的预测。
P ( s ∣ f s , p , o ) = ς ( V e f s + p W s o ) ( 2.1 ) P(s|f_s,p,o)=\varsigma (V_ef_s+pW_so)(2.1)P (s ∣f s ,p ,o )=ς(V e f s +p W s o )(2 .1 )P ( o ∣ f o , s , p ) = ς ( V e f o + s W o p ) ( 2.2 ) P(o|f_o,s,p)=\varsigma (V_ef_o+sW_op)(2.2)P (o ∣f o ,s ,p )=ς(V e f o +s W o p )(2 .2 )P ( p ∣ f r , s , o ) = σ ( V r f r + s W p o ) ( 3 ) P(p|f_r,s,o)=\sigma (V_rf_r+sW_po)(3)P (p ∣f r ,s ,o )=σ(V r f r +s W p o )(3 )其中ς \varsigma ς是一个softmax函数,V e V_e V e 是主客体分类器共享的视觉预测器的可学习权值,W s W_s W s 和W o W_o W o 是一个三阶张量,可以通过张量积将两个给定的向量映射到一个新的张量,模拟主/客体对谓语和客/主体的依赖关系,同W p W_p W p 。σ \sigma σ是一个sigmoid函数。
本文提出了一种更好的学习依赖知识的方法,这允许直接从真实三元组组合学习依赖关系,并与视觉预测器联合优化。即在输入中目标被明确地标记,并基于其余标记和视觉上下文预测目标标记。
迭代推理 :即联合概率的近似估计。
(1)从视觉信息初始化
- 设置初始条件变量:s ( 0 ) = o ( 0 ) = p ( 0 ) = 0 ( 4 ) s(0)=o(0)=p(0)=0(4)s (0 )=o (0 )=p (0 )=0 (4 ),公式(2)中主客体分类器退化为简单的视觉分类器,简单地基于视觉特征f s , f o f_s,f_o f s ,f o 进行预测;
- 通过迭代步骤估计三个条件概率:s ( i + 1 ) = P ( s ∣ f s , p ( i ) , o ( i ) ) ( 5.1 ) s_{(i+1)}=P(s|f_s,p_{(i)},o_{(i)})(5.1)s (i +1 )=P (s ∣f s ,p (i ),o (i ))(5 .1 )o ( i + 1 ) = P ( o ∣ f o , s ( i ) , p ( i ) ) ( 5.2 ) o_{(i+1)}=P(o|f_o,s_{(i)},p_{(i)})(5.2)o (i +1 )=P (o ∣f o ,s (i ),p (i ))(5 .2 )p ( i + 1 ) = P ( p ∣ f r , s ( i + 1 ) , o ( i + 1 ) ) ( 5.3 ) p_{(i+1)}=P(p|f_r,s_{(i+1)},o_{(i+1)})(5.3)p (i +1 )=P (p ∣f r ,s (i +1 ),o (i +1 ))(5 .3 )即主客体的预测都是从前一步提炼出来的,再用来提炼谓词。该方法比单步推理具有更强的收敛性和改进性;
- 在N次迭代后,可以生成关系三元组。主客体、谓语预测取概率大于阈值δ = 0.2 \delta=0.2 δ=0 .2的值。
(2)从时间窗口预测初始化
- 初始化条件变量:( e s ( t ) , e o ( t ) ) (e_s^{(t)},e_o^{(t)})(e s (t ),e o (t ))
- 使用上一个时间窗口中的实体来构建相应的链接图:如果实体与e s ( t ) e_s^{(t)}e s (t )充分重叠(I 0 U > 0.7 I0U>0.7 I 0 U >0 .7),则表示为E s ( t − 1 ) E_s^{(t-1)}E s (t −1 ),和e s ( t ) e_s^{(t)}e s (t )相连。每条连接边都由相应的IoU值赋予一个权重。同样的,E o ( t − 1 ) E_o^{(t-1)}E o (t −1 )和e o ( t ) e_o^{(t)}e o (t )相连。一对e s ( t − 1 ) ∈ E s ( t − 1 ) e_s^{(t-1)}\in E_s^{(t-1)}e s (t −1 )∈E s (t −1 ),e o ( t − 1 ) ∈ E o ( t − 1 ) e_o^{(t-1)}\in E_o^{(t-1)}e o (t −1 )∈E o (t −1 )将被视为一个节点连接到关系节点( e s ( t ) , e o ( t ) ) , r ( t ) (e_s^{(t)},e_o^{(t)}),r^{(t)}(e s (t ),e o (t )),r (t )。关系节点标记为R ( t − 1 ) R^{(t-1)}R (t −1 ),这些连接边的权值由相应的主体或客体的IoU赋值,以较小者为准。
- 传播节点的预测概率给对应节点E s ( t − 1 ) , E o ( t − 1 ) , R ( t − 1 ) E_s^{(t-1)},E_o^{(t-1)},R^{(t-1)}E s (t −1 ),E o (t −1 ),R (t −1 ),通过基于边权的加权平均来聚合概率。
- 在迭代推理中,将聚合概率赋给初始条件变量。s ( 0 ) = ∑ e s ( t − 1 ) e x p ( I o U ( e s ( t − 1 ) , e s ( t ) ) ) ∑ e ′ s ( t − 1 ) e x p ( I o U ( e ′ s ( t − 1 ) , e ′ s ( t ) ) ) s ( N ) ( e s ( t − 1 ) ) ( 6 ) s_{(0)}=\sum {e_s^{(t-1)}} \frac{exp(IoU(e_s^{(t-1)},e_s^{(t)}))}{ \sum{{e’}s^{(t-1)}}exp(IoU({e’}_s^{(t-1)},{e’}_s^{(t)})) }s{(N)}(e_s^{(t-1)}) (6)s (0 )=e s (t −1 )∑∑e ′s (t −1 )e x p (I o U (e ′s (t −1 ),e ′s (t )))e x p (I o U (e s (t −1 ),e s (t )))s (N )(e s (t −1 ))(6 )其中s ( N ) ( e s ( t − 1 ) ) s_{(N)}(e_s^{(t-1)})s (N )(e s (t −1 ))是e s ( t − 1 ) e_s^{(t-1)}e s (t −1 )估计的主体概率。
- 然而,如果给定的对( e s ( t ) , e o ( t ) ) (e_s^{(t)},e_o^{(t)})(e s (t ),e o (t ))在上一个时间窗口没有任何关联的预测,则还是使用(4)进行初始化。
视频迭代关系推理过程如下所示:

; 2. VIDVRD-II架构
三个改进:1)轻量级对象tracklet提案;2)训练实体对抽样策略;3)迭代关系推理。
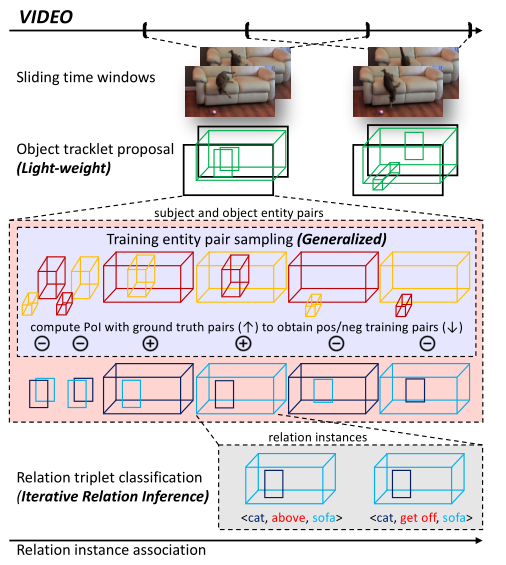
(1)滑动窗口
- 对于任意长度的视频,应用大小为30帧、跨度为15帧的滑动时间窗口进行后续处理。
- 每个给定的时间窗口中,将生成目标轨迹建议作为被检测的实体,并预测每一对对象的关系三元组。
(2) 对象Tracklet提议
- 由于在本文体系结构中,模型被视为一个通用的对象检测器,所以只使用输出的边界框和相应的区域特征进行后续处理。
- 然后使用轻量级的Seq-NMS生成一个紧凑的对象轨迹集。
- 简单地使用由包围框组成的平均区域特征作为每个轨迹的视觉特征,因为本文不关注复杂的视觉特征提取。
(3) 关系三元组分类
- 对于每一对物体轨迹,为关系特征f r f_r f r 形成主客实体对,提取和迭代关系推理N=3步。
- 为了模型能够感知主客体之间的相对时间距离,对关系特征编码时空相对位置。
- 即:计算起始主客体边界框之间的相对位置特征:f r P B = [ x s − x o x o , y s − y o y o , l o g w s w o , l o g h s h o , l o g w s h s w o h o , t s − t o 30 ] f_r^{PB}=[\frac{x_s-x_o}{x_o},\frac{y_s-y_o}{y_o},log\frac{w_s}{w_o},log\frac{h_s}{h_o},log\frac{w_sh_s}{w_oh_o},\frac{t_s-t_o}{30}]f r P B =[x o x s −x o ,y o y s −y o ,l o g w o w s ,l o g h o h s ,l o g w o h o w s h s ,3 0 t s −t o ]其中( x s , y s , w s , h s , t s ) (x_s,y_s,w_s,h_s,t_s)(x s ,y s ,w s ,h s ,t s )是主体起始边界框坐标及其在时间窗口中的帧ID,同( x o , y o , w o , h o , t o ) (x_o,y_o,w_o,h_o,t_o)(x o ,y o ,w o ,h o ,t o )。
- 计算结束主客体边界框之间的相对位置特征f r P E f_r^{PE}f r P E 也是如此。
- 为了得到最终关系特征f r f_r f r ,使用二层前馈网络(FFN)融合了主客体的视觉特征f s , f o f_s,f_o f s ,f o 和f r P B , f r P E f_r^{PB},f_r^{PE}f r P B ,f r P E 。
- 使用focal loss来减轻训练数据中类别分布不平衡的影响。
(4)训练实体对抽样
- 注意,生成的对象轨迹并不保证与时间窗口在时间上对齐(即开始和结束在同一帧),之前的工作通常忽略了这一点,并简单地假设tracklet扩展到整个时间窗口。
- 将每个实体对与真实情况进行比较。如果该对和真实框相当接近,将其作为该真实框的正训练样本,并使用对应的关系三元组作为训练目标。
- 为每个轨迹w.r.t和真实情况计算相交比例(PoI):P o I ( τ , τ g t ) = I n t e r s e c t i o n ( τ , τ g t ) V o l u m e ( τ ) PoI(\tau,\tau^{gt})=\frac{Intersection(\tau,\tau^{gt})}{Volume(\tau)}P o I (τ,τg t )=V o l u m e (τ)I n t e r s e c t i o n (τ,τg t )。
- 要求P o I ( τ s , τ s g t ) PoI(\tau_s,\tau_s^{gt})P o I (τs ,τs g t )和P o I ( τ o , τ o g t ) PoI(\tau_o,\tau_o^{gt})P o I (τo ,τo g t )都大于阈值ρ = 0.9 \rho=0.9 ρ=0 .9。
(5) 关联关系实例
我们按照VIDVRD中提出的方法,执行简单的贪婪关系关联,以跨时间窗口关联检测到的关系实例。
实验数据
1. 与非迭代推理相比
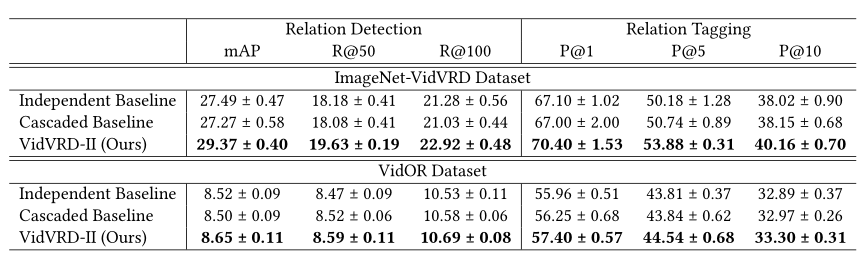
- 对于ImageNet-VidVRD,本文方法在P@1和P@5下分别比独立基线提高了3.30%和3.70%。
- 对于VidOR,本文方法也比P@1上的独立基线提高了1.44%。
- 这些对比结果表明迭代关系推理在识别视频中的视觉关系方面是有效的。
; 2. 消融实验
(1)迭代次数
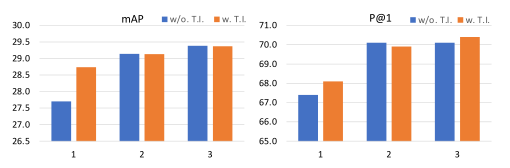
使用时间初始化(橙色条),不使用时间初始化(蓝色条)。
我们发现两步推理比一步推理有明显的改进,并且在3步之内收敛。这表明了执行多个推理步骤以基于其他两个关系三元组来细化每个组件的重要性。
; (2) 时间初始化
有时间初始化的1步推理比没有时间初始化的推理有显著的改进。但是,对于具有更多迭代步骤的推理,不能观察到这种改进。这表明该组件的主要作用是用更好的信息启动迭代推理,但不能提供长期的好处。
(3) 新的训练权重方法的作用
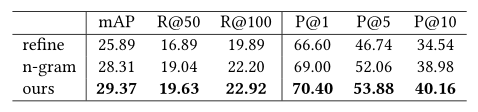
两种标准训练方法refine和n-gram,以及本文新的训练方法来学习依赖知识。
; (4) 学习权重中的权重衰减
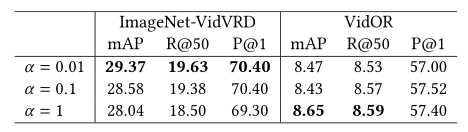
对于ImageNet-VidVRD选择α = 0.01 \alpha=0.01 α=0 .0 1,对于VidOR选择α = 1 \alpha=1 α=1。
(5)训练实体对抽样中的PoI阈值
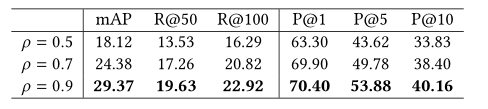
如果我们使用较小的阈值(通常是以前大多数作品采用的0.5),则会出现显著的性能下降。这些较小的阈值(即正训练对)所采样的轨迹可能不能充分代表视频中真实实体的运动轨迹。这可能是因为一个小的阈值将包括许多不准确的轨迹与真实情况重叠,但在一些重要帧偏离,这可能会导致模型错误推断运动轨迹的大小或方向的变化,这可能有非常不同的语义含义。
; 性能对比
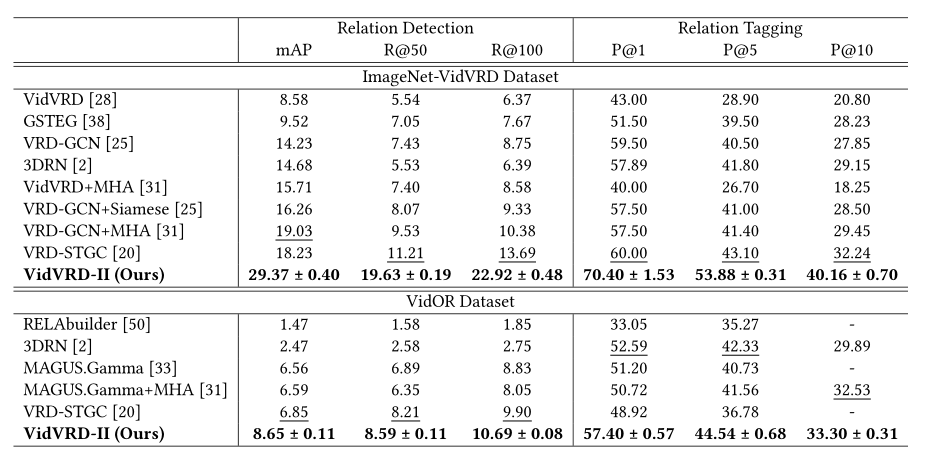
- VidVRD-II在两个数据集上同时实现了具有竞争力的性能。
- 在ImageNet-VidVRD上,VidVRD-II比所有比较的方法都有显著的优势。如此大的改进来自于提出的迭代关系推理和对VidVRD-II架构的改进。
- 在VidOR上,VRD-STGC和3DRN仅在一组评价指标下达到了最先进的性能,即:分别是关系检测或关系标记。然而,VidVRDII通过实现所有指标的最佳性能,证明了其优越性。
总结
- 本文提出通过 迭代关系推理(VidVRD-II) 来检测视频中的视觉关系。
- VidVRD-II方法中,模型探索了关系三元组中三个组件之间的依赖关系,并在推理过程中以迭代的方式细化它们的分类得分。
- 为了更好地从训练数据中学习依赖性知识,还引入了一种新的训练方法。
- 实验证明了所提出的迭代关系推理和训练方法的有效性,并显示了VidVRD-II在基准数据集上的最新性能。值得一提的是,ImageNet-VidVRD的改进是非常大的。
- 定性分析也表明,VidVRD-II可以检测出视频中许多有趣的视觉关系,这在以往的工作中是很少观察到的。
- 未来的工作包括探索使用预先训练的模型、知识图或它们的组合来学习更全面的依赖知识。这将把当前的技术推进到更一般化的领域和学习设置。探索视频关系在高级视频语言任务中的使用也很有趣,比如视频字幕、VQA和多媒体检索。
Original: https://blog.csdn.net/wawaqing2333/article/details/122227857
Author: 娃娃亲�
Title: 论文阅读:Video Visual Relation Detection via Iterative Inference
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/555272/
转载文章受原作者版权保护。转载请注明原作者出处!