

实体对齐(Entity Alignment)、知识图谱融合论文方法总结整理
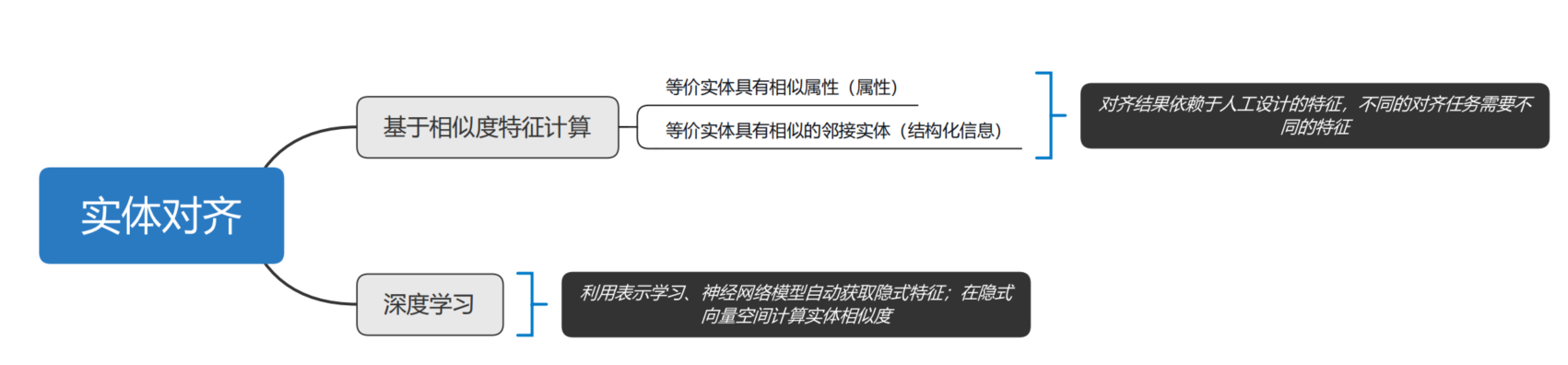
传统的实体对齐方法主要通过属性相似度匹配的方式实现,利用有监督学习的机器学习模型,如:决策树、支持向量机、集成学习等。依赖实体的属性信息,通过属性相似度,进行跨平台实体对齐关系的推断。基于知识表示学习的方法通过将知识图谱中的实体和关系都映射低维空间向量,直接用数学表达式来计算各个实体之间相似度,例如transe方法等。
年份模型主要思想博文代码论文2019SUM LSTM N-gram提出两个KG之间的实体对齐框架,由谓词对齐模块、嵌入学习模块、实体对齐模块组成,提出一种新的嵌入模型,将实体嵌入和属性嵌入集成在一起,用来学习对于两个KGs的统一嵌入空间,利用知识图中存在的大量属性三元组,生成属性字符嵌入。属性字符嵌入通过基于实体属性计算实体之间的相似度,将两个知识图中的实体嵌入转移到同一空间。我们使用传递性规则来进一步丰富实体的属性数量,以增强属性字符嵌入。
知乎 code
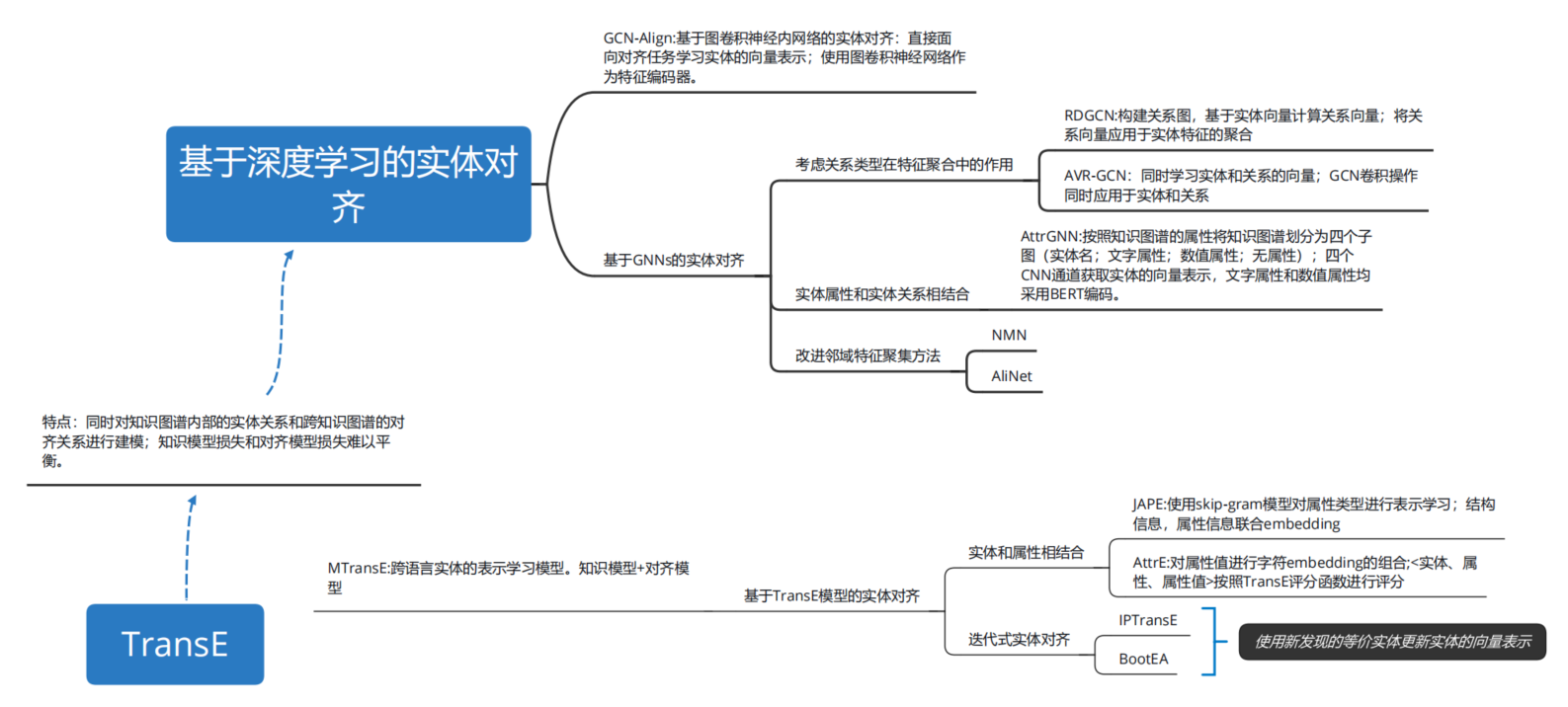
10.Entity Alignment between Knowledge Graphs Using Attribute Embeddings2020COTSAE以前的工作主要集中在通过学习实体在关系三元组和预先对齐的”种子实体”上的嵌入来捕捉实体的结构语义。一些作品也试图结合属性信息来帮助提炼实体嵌入。然而,仍然有许多问题没有被考虑,这极大地限制了属性信息在实体对齐中的利用。不同的KGs可能有许多不同的属性类型,甚至同一个属性可能有不同的数据结构和值粒度。最重要的是,属性可能对实体对齐有各种”贡献”。为了解决这些问题,我们提出了通过联合训练两个嵌入学习组件来结合实体的结构和属性信息的COTSAE。在我们的模型中,我们还提出了一种联合注意方法来协同学习属性类型和值的注意。
code
29.COTSAE: CO-Training of Structure and Attribute Embeddings for Entity Alignment2020JarKA由于KGs的结构通常是稀疏的,因此实体的属性在对齐实体时可能起着重要的作用。然而,跨KGs的属性的异构性阻止了准确地嵌入和比较实体。为了解决这个问题,我们建议对属性之间的交互进行建模,而不是全局嵌入一个具有所有属性的实体。我们进一步提出了一个联合框架来合并从属性和结构推断的比对。
code
33.JarKA: Modeling Attribute Interactions for Cross-lingual Knowledge Alignment2017JAPE提出了一种跨语言实体对齐的联合属性保持嵌入模型。它将两个知识库的结构共同嵌入到一个统一的向量空间中,并通过利用知识库中的属性相关性来进一步完善它。
code
3.Cross-lingual Entity Alignment via Joint Attribute-Preserving Embedding2020AttrGNN使用一个属性值编码器,并将KG划分为子图,以有效地建模各种类型的属性三元组。此外,由于现有环境影响评价数据集的命名偏差,现有环境影响评价方法的性能被高估。为了做出客观的评估,我们提出了一个硬实验设置,在这个设置中,我们选择具有非常不同名称的等价实体对作为测试集。
code
41.Exploring and Evaluating Attributes, Values, and Structures for Entity Alignment2017MTransE提出了基于翻译的多语言知识图嵌入模型MTransE,以提供一个简单而自动化的解决方案。通过在独立的嵌入空间中编码每种语言的实体和关系,MTransE为每个嵌入向量提供了到其他空间中跨语言对应体的转换,同时保留了单语嵌入的功能。
code
- Multilingual Knowledge Graph Embeddings for Cross-lingual Knowledge Alignment2017IPTransE提出了一种基于联合知识嵌入的实体对齐方法。我们的方法根据一个小的对齐实体的种子集,将实体和各种KGs的关系联合编码到一个统一的低维语义空间中。在这个过程中,我们可以根据实体在这个联合语义空间中的语义距离来对齐实体。更具体地说,我们提出了一种迭代和参数共享的方法来提高对准性能。
code
4.Iterative Entity Alignment via Joint Knowledge Embeddings2020NMN提出了一种新的基于采样的实体对齐框架(Neighborhood Matching Network,NMN)。NMN旨在精确的选择出包含最多信息量的邻居节点以及准确的计算出不同实体邻居节点的相似度。
知乎
34.Neighborhood Matching Network for Entity Alignment2018BootEA提出了一个基于Bootstrap的实体对齐方法。该方法迭代地将可能的实体对齐标记为训练数据 把实体对齐转换为分类问题 提出了截断的负采样
知乎 code
- Bootstrapping Entity Alignment with Knowledge Graph Embedding2018KDCoE介绍了一种基于嵌入的方法,该方法利用弱对齐的多语言KG来使用实体描述进行半监督跨语言学习。我们的方法执行两个嵌入模型的联合训练,即多语言KG嵌入模型和多语言文字描述嵌入模型。
code
6.Co-training Embeddings of Knowledge Graphs and Entity Descriptions for Cross-lingual Entity Alignment2018NTAM提出了一种非平移方法,旨在利用概率模型为对齐任务提供更鲁棒的解决方案,通过探索结构属性以及在学习单个网络表示的过程中利用锚将每个网络投影到相同的向量空间。Non-translational Alignment for Multi-relational Networks2018提出了LinkNBed,这是一个深入的关系学习框架,可以跨多个图学习实体和关系表示。LinkNBed: Multi-Graph Representation Learning with Entity Linkage|2018GCN-Align提出了一种通过图形卷积网络进行跨语言KG对齐的新方法。给定一组预先对齐的实体,我们的方法训练GCNs将每种语言的实体嵌入到统一的向量空间中。实体对齐是基于嵌入空间中实体之间的关联来发现的。嵌入可以从实体的结构和属性信息中学习,并且结构嵌入和属性嵌入的结果被组合以获得精确的对齐。
code
Cross-lingual Knowledge Graph Alignment via Graph Convolutional Networks2019SEA提出了一种半监督实体对齐方法,利用标记实体和丰富的未标记实体信息进行对齐。此外,我们通过进行对抗性训练,在意识到程度差异的情况下,改进了知识图嵌入。Semi-Supervised Entity Alignment via Knowledge Graph Embedding with Awareness of Degree Difference2019RSN4EA提出了循环跳过网络,它使用一个跳过机制来弥补实体之间的差距。递归神经网络将递归神经网络与剩余学习相结合,以有效捕捉KGs内部和之间的长期关系依赖。我们设计了一个端到端的框架来支持不同任务的响应网络。我们的实验结果表明,在实体对齐方面,响应面方法优于最先进的基于嵌入的方法,并且在KG完成方面具有竞争力。
code
Learning to Exploit Long-term Relational Dependencies in Knowledge Graphs2019MuGNN提出了一种新的多通道图神经网络模型,通过多通道鲁棒编码两个知识图来学习面向对齐的知识图嵌入。每个通道通过不同的关系加权方案对KGs进行编码,
code
Multi-Channel Graph Neural Network for Entity Alignment2019GMNN引入了主题实体图,一个实体的局部子图,用它们在KG中的上下文信息来表示实体。从这个角度来看,知识库对齐任务可以表述为一个图匹配问题
code
Cross-lingual Knowledge Graph Alignment via Graph Matching Neural Network|2019MultiKE提出了一个新的框架,它统一了实体的多个视图来学习实体对齐的嵌入。具体来说,我们基于实体名称、关系和属性的视图,使用几种组合策略来嵌入实体。
code
15.Multi-view Knowledge Graph Embedding for Entity Alignment2019RDGCN提出了一种新的关系感知双图卷积网络(RDGCN),通过知识图和它的对偶关系之间的密切交互来整合关系信息,并进一步捕获邻近结构来学习更好的实体表示。
code
Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs2019OTEA提出了一个新的实体排列框架(OTEA),它通过最优传输理论双重优化了实体层损失和群层损失。我们还对对偶平移矩阵施加了正则化,以减轻变换过程中噪声的影响。Improving Cross-lingual Entity Alignment via Optimal Transport2019NAEA结合实体的邻域子图层次信息,提出了一种多语言知识图的邻域感知注意表示方法NAEA。NAEA设计了一种注意机制,通过用加权组合聚集邻居的表示来学习邻居级表示。Neighborhood-Aware Attentional Representation for Multilingual Knowledge Graphs2019AVR-GCN提出了一种矢量关系图卷积网络(VR-GCN)来同时学习多关系网络中图实体和关系的嵌入。卷积过程采用了知识图的角色区分和翻译特性。此后,基于虚拟现实-GCN的虚拟现实-GCN对准框架被开发用于多关系网络对准任务。A Vectorized Relational Graph Convolutional Network for Multi-Relational Network Alignment2019KECG提出了一种基于联合知识嵌入模型和交叉图模型的半监督实体对齐方法。它可以更好地利用种子对齐,在整个图形上传播基于KG的约束。具体来说,对于知识嵌入模型,我们利用the来隐式完成两个KGs以实现一致性,并学习实体之间的关系约束。对于交叉图模型,我们扩展了具有投影约束的图注意网络(GAT)来对图进行鲁棒编码,两个KGs共享同一个GAT来传递结构知识,并通过注意机制忽略不重要的邻居进行对齐。
code
Semi-supervised Entity Alignment via Joint Knowledge bedding Model and Cross-graph Model2019HGCN提出了一种新的实体对齐的联合学习框架。我们方法的核心是基于图卷积网络(GCN)的框架,用于学习实体和关系表示。我们不是依赖预先对齐的关系种子来学习关系表示,而是首先使用GCN学习的实体嵌入来近似它们。然后,我们将关系近似合并到实体中,以迭代学习两者的更好表示。
code
Jointly Learning Entity and Relation Representations for Entity Alignment2019MMEA几乎所有的方法都是基于TransE或其变体的,许多研究已经证明它们不适合编码多映射关系,如1-N、N-1和N-N关系,因此这些方法获得的比对精度较低。为了解决这个问题,我们提出了一个新的基于嵌入的框架。通过在嵌入上定义基于点产品的函数,我们的模型可以更好地捕捉1-1和多映射关系的语义。我们通过一小组预排列的种子来校准不同KGs的嵌入。我们还提出了一种加权负采样策略,以在训练过程中产生有价值的负样本,并最终将预测视为一个双向问题。Modeling Multi-mapping relations for Precise Cross-lingual Entity Alignment2019HMAN跨语言实体对齐的任务是将源语言中的实体与目标语言中的实体进行匹配。在这项工作中,我们研究了基于嵌入的方法来将多语言KGs中的实体编码到相同的向量空间中,其中等价的实体彼此接近。具体来说,我们应用图卷积网络(GCNs)来组合实体的多方面信息,包括实体的拓扑连接、关系和属性,以学习实体嵌入。为了利用用不同语言表达的实体的字面描述,我们提出了两种使用预训练的多语言BERT模型来弥补跨语言的差距。我们进一步提出了两个策略来整合基于GCN和基于贝尔的模块,以提高性能。
code
Aligning Cross-lingual Entities with Multi-Aspect Information2020MRAEA现有的基于翻译的实体对齐方法将跨语言知识和单语知识联合建模为一个统一的优化问题。另一方面,基于图神经网络(GNN)的方法要么忽略节点微分,要么通过实体或三重实例表示关系。它们都不能对嵌入在关系中的元语义进行建模,也不能对n对n和多图等复杂关系进行建模。为了应对这些挑战,我们提出了一种新的元关系感知实体对齐(MRAEA),通过关注节点的传入和传出邻居及其连接关系的元语义来直接建模跨语言实体嵌入。此外,我们还提出了一种简单有效的双向迭代策略,在训练过程中添加新的对齐种子。
code
MRAEA: An Efficient and Robust Entity Alignment Approach for Cross-lingual Knowledge Graph2019AliNet提出了一种新的KG对齐网络,即AliNet,旨在以端到端的方式缓解邻域结构的非同构。由于模式的异构性,对应实体的直接邻居通常是不相似的,AliNet引入了远邻居来扩展它们的邻域结构之间的重叠。它采用一种注意力机制来突出有益的远方邻居并减少噪音。然后,它使用选通机制控制直接和远距离邻域信息的聚集。我们还提出了一个关系损失来改进实体表示。
code
Knowledge Graph Alignment Network with Gated Multi-hop Neighborhood Aggregation|2020本文介绍了两种协调推理方法,即由易到难解码策略和联合实体对齐算法。具体来说,由易到难策略首先从预测结果中检索模型可靠的比对,然后将它们作为额外的知识纳入,以解决剩余的模型不确定的比对。为了实现这一点,我们进一步提出了一个基于当前最先进基线的增强校准模型。此外,为了解决多对一问题,我们建议联合预测实体对齐,以便一对一约束可以自然地纳入对齐预测。Coordinated Reasoning for Cross-Lingual Knowledge Graph Alignment2020CEAFF提出了一个集体环境评估框架。我们首先使用三个有代表性的特征,即结构、语义和字符串信号,它们适用于捕捉异构KGs中实体之间相似性的不同方面。为了做出集体进化算法决策,我们将进化算法表述为经典的稳定匹配问题,并通过延迟接受算法得到进一步有效的解决。Collective Embedding-based Entity Alignment via Adaptive Features2020提出了一个两阶段的神经架构,用于学习和细化图之间的结构对应关系。首先,我们使用由图神经网络计算的局部节点嵌入来获得节点之间的软对应的初始排序。其次,我们使用同步消息传递网络来迭代地重新排列软对应关系,以在图之间的局部邻域中达到匹配一致。我们从理论和经验上表明,我们的消息传递方案为相应的邻域计算了一个有充分根据的一致性度量,然后用于指导迭代的重新排序过程。
code
DEEP GRAPH MATCHING CONSENSUS2020CG-MuAlign提出了一种用于多类型实体对齐的集合图神经网络,称为CGMuAlign。与以前的工作不同,CG-MuAlign联合对齐多种类型的实体,共同利用邻域信息,并推广到未标记的实体类型。具体来说,我们提出了一种新的集体聚集函数,该函数通过交叉图和自我关注来缓解知识图的不完全性,通过小批量训练和有效的邻域采样策略来提高效率。
code
Collective Multi-type Entity Alignment Between Knowledge Graphs2020NMN提出了邻域匹配网络(NMN),一个新的实体对齐框架,以解决结构异质性的挑战。NMN估计实体之间的相似性,以捕捉拓扑结构和邻域差异。它提供了两个创新组件,用于更好地学习实体对齐的表示。它首先使用一种新颖的图形采样方法为每个实体提取一个有区别的邻域。然后,它采用交叉图邻域匹配模块来联合编码给定实体对的邻域差异。这种策略允许NMN有效地构建匹配定向的实体表示,同时忽略对对齐任务有负面影响的噪声邻居。
code
Neighborhood Matching Network for Entity Alignment2020BERT-INT为了同时利用图的结构和边信息,如名称、描述和属性,大多数的工作都是通过图的神经网络将边信息,特别是名称,通过链接的实体进行传播。然而,由于不同知识图的异构性,聚集不同的邻居会影响对齐精度。这项工作提出了一个只利用辅助信息的交互模型。我们不是聚集邻居,而是计算邻居之间的交互,这可以捕获邻居的细粒度匹配。类似地,属性的交互也被建模。
code
BERT-INT: A BERT-based Interaction Model For Knowledge Graph Alignment2020SSP为了学习实体表示,大多数进化算法依赖于基于翻译的方法来获取实体的局部关系语义,或者依赖于图卷积网络来利用全局KG结构。然后,基于它们的距离来识别对齐的实体。在本文中,我们建议联合利用全局KG结构和实体特定的关系三元组来实现更好的实体对齐。Global Structure and Local Semantics-Preserved Embeddings for Entity Alignment2020DAT现有的EA解决方案主要依靠结构信息来对齐实体,通常是通过KG嵌入。然而,在现实生活中,只有少数实体紧密相连,其余大多数拥有相当稀疏的邻域结构。我们称后者为长尾实体,并观察到这种现象可以说限制了结构信息在进化分析中的使用。为了缓解这个问题,我们重新审视和研究了传统的EA管道,以追求优雅的性能。
code
Degree-Aware Alignment for Entities in Tail2020RREEA提出了一种新的基于神经网络的方法——关系反射实体对齐(RREA)。RREA利用关系反射转换,以更有效的方式为每个实体获取关系特定的嵌入。
code
Relational Reflection Entity Alignment2020REA提出的REA(鲁棒实体对齐)方法由两部分组成:噪声检测和噪声感知实体对齐。噪声检测是根据对抗训练原理设计的。噪声感知实体对齐是以基于图形神经网络的知识图形编码器为核心设计的。为了相互促进这两个组成部分的性能,我们提出了一个统一的强化训练策略来将它们结合起来。
code
REA: Robust Cross-lingual Entity Alignment Between Knowledge Graphs2020HyperKA用低维双曲线嵌入来探索知识关联。我们提出了一种双曲关系图神经网络,通过双曲变换来嵌入和获取知识关联。
code
Knowledge Association with Hyperbolic Knowledge Graph Embeddings2020EPEA出了一种新的方法,直接学习实体对的嵌入KG对齐。我们的方法首先生成一个两个KGs的成对连通图(PCG),其节点是实体平面,边对应关系对;然后,它学习PCG的节点(实体对)嵌入,用于预测实体的等价关系。为了得到理想的嵌入,使用卷积神经网络从实体对的属性中生成实体对的相似特征;利用图神经网络传播相似特征,得到实体模型的最终嵌入。Knowledge Graph Alignment with Entity-Pair Embedding2020EVA通过利用实体的视觉相似性来创建初始种子字典(视觉中枢),提供了一个完全无监督的解决方案。
code
Visual Pivoting for (Unsupervised) Entity Alignment2020RNM提出了一种新的基于关系感知的邻域匹配模型——RNM实体对齐模型。具体来说,我们建议利用邻域匹配来增强实体对齐。除了在匹配邻域时比较邻居节点,我们还试图从连通关系中挖掘有用的信息。此外,设计了一个迭代框架,以半监督的方式利用实体对齐和关系对齐之间的积极交互。Relation-Aware Neighborhood Matching Model for Entity Alignment2021JEANS提出了一个附带监督的模型,JEANS,它在一个共享的嵌入方案中联合表示多语言KGs和文本语料库,并寻求通过来自文本的附带监督信号来改善实体对齐。JEANS首先部署一个实体基础过程,将每个KG与单语文本语料库相结合。然后,进行两个学习过程:(1)嵌入学习过程,将每种语言的KG和文本编码在一个嵌入空间中,以及(2)基于自学习的对齐学习过程,迭代地诱导实体匹配和嵌入之间的词汇匹配。Cross-lingual Entity Alignment with Incidental Supervision2020提出了一种新的KG采样算法,利用该算法,我们生成了一组具有各种异质性和分布的专用基准数据集,以进行现实的评估。我们开发了一个开源库,包括12种代表性的基于嵌入的实体对齐方法,并对这些方法进行了广泛的评估,以了解它们的优势和局限性。
code
A Benchmarking Study of Embedding-based Entity Alignment for Knowledge Graphs2020本文中,我们通过对最先进的环境分析方法进行全面的评估和详细的分析来填补这一空白。我们首先提出一个包含所有当前方法的通用e a框架,然后将现有方法分为三大类。接下来,我们根据这些解决方案的有效性、效率和健壮性,在广泛的用例上明智地评估它们An Experimental Study of State-of-the-Art Entity Alignment Approaches2020报告了我们在将基于图卷积网络(GCN)的模型应用于这项任务时的经验。GCN的变体被用于多种最先进的方法,因此了解基于GCN的模型的细节和局限性非常重要。Knowledge Graph Entity Alignment with Graph Convolutional Networks: Lessons Learned2020们评估了那些在工业环境中的最先进的方法,其中探索了不同大小和不同偏差的种子映射的影响。除了来自DBpedia和Wikidata的流行基准之外,我们还贡献并评估了一个新的工业基准,该基准是从医学应用部署中的两个异构知识图(KGs)中提取的。
code
An Industry Evaluation of Embedding-based Entity Alignment2019KAGAN提出了一个无监督的框架,将不同知识图的实体和关系嵌入与一个对抗性的学习框架相结合。此外,正则化项最大化了不同知识图嵌入之间的互信息,用于减轻学习对齐函数时的模式崩溃问题。通过利用有限数量的对齐三元组作为指导,这样的框架可以进一步与现有的监督方法无缝集成。Weakly-supervised Knowledge Graph Alignment with Adversarial Learning2021提出了一个新的框架来标记知识图数据集中的实体对齐。为人类贴标机选择信息实例的不同策略构成了我们框架的核心。我们说明了实体对齐的标注与将类别标注指定给单个实例有何不同,以及这些差异如何影响标注效率。基于这些考虑,我们提出并评估了不同的主动和被动学习策略。我们的一个主要发现是,被动学习方法可以有效地预先计算,并且更容易部署,可以实现与主动学习策略相当的性能。Active Learning for Entity Alignment2020(EM-GCN提出一个新的框架,即广义多关系图卷积网络(GEM-GCN)来解决这些限制,该框架结合了基于图的信念传播中的GCNs的能力和高级知识库嵌入方法的优势,并超越了这些限制。Generalized Multi-Relational Graph Convolution Network2021选择了一个具有代表性的基准数据集样本,并描述了它们的属性。我们还研究了实体表示的不同初始化,因为它们是模型性能的决定性因素。此外,我们为适当的评估设置使用共享的训练/验证/测试分割来评估所有数据集上的所有方法。
code
A Critical Assessment of State-of-the-Art in Entity Alignment
实体对齐数据集整理—更新中
名称-下载地址-DBpe-dia(DBP)LinkedGeoData(LGD)Geonames(GEO)YAGODBP15K
下载地址
DBP100K
下载地址
DWY100K
下载地址
实体对齐评价指标—更新中
名称-意义-hits@10(H@10))对于一对关系及实体,我们将头实体或尾实体替换成任意一种其他的实体(共n-1个,保持另一个实体以及关系不变,只变其中一个实体),这样我们得到了(n-1)个新的关系三元组,然后我们对这些三元组计算实体关系距离,将这n-1个三元组按照距离从小到大排列。在这个排好序的n-1元素中,我们从第一个开始遍历,看从第一个到第十个是否能够遇到真实的实体,如果遇到了就将(hit@10 +1),表示我们的算法能够正确表示三元组关系的能力(在hit@10里 不要求第一个才是对的,能做到前十的能力就可以了)Mean Rank(MR)计算在测试集里,平均到第多少个才能匹配到正确的结果,值越小代表效果越好。Mean Reciprocal Rank(MRR)平均倒数排名,是一个国际上通用的对搜索算法进行评价的机制,即第一个结果匹配,分数为1,第二个匹配分数为0.5,第n个匹配分数为1/n,如果没有匹配的句子分数为0。最终的分数为所有得分之和。值越大代表效果越好。
推荐阅读

Original: https://blog.csdn.net/bjxxkjdxcdd/article/details/115056940
Author: BISTU_CD
Title: 实体对齐(Entity Alignment)相关论文与数据集整理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/555216/
转载文章受原作者版权保护。转载请注明原作者出处!