

文章目录
一、embedding
首先,我们得知道什么是embedding?他有什么优点?他为什么要被开发出来?传统的one-hot编码不可以吗?接下来让我们一一进行解决
1、什么是embedding?
① 维基百科的 官方回答:


② 自己的理解:
(这个结合了一下n篇大佬的博客思路进行理解的)
首先,embedding在pytorch或者tf中会被经常使用,m代表的是单词的数目,n代表的是词语嵌入的维度。 其次,词嵌入(word embedding)是一个大矩阵,一行代表的是一个单词。
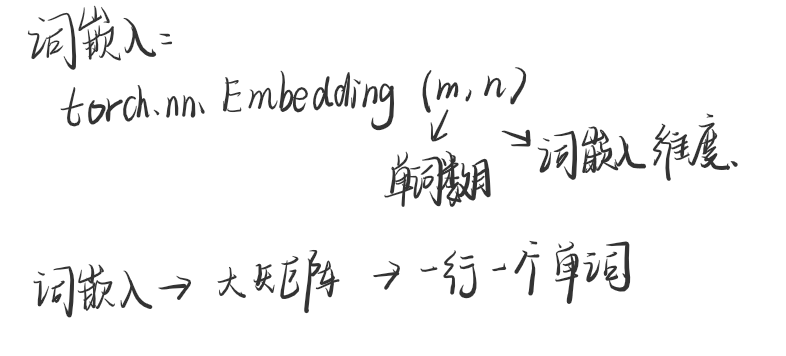
最后举一个例子,这个例子是大佬博客一样的例子,我感觉特别容易理解和领悟,现在分享给大家。
例子:因为皇帝和公主一定有血缘关系,所以为1,皇帝和王妃没有直系血缘关系,但是他俩在一起,所以为0.6;公主15岁结婚出宫,所以她与宫殿的关系是0.25,王妃15岁嫁入宫里,所以她与宫的关系是0.75;公主和王妃都是女的,所以说和女的关系是1。然后假设,每一个字都是占一个二字短语的一半比例,便有了下面这张转换图。

根据上方的图,我们假设皇宫为特征①,宫里为特征②,女性为特征③,就会得到下方的关系式子
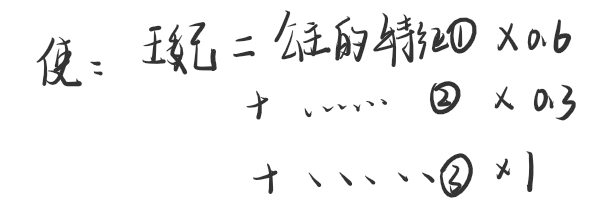
以上就解释了何为embedding。
2、embedding为什么会出现?
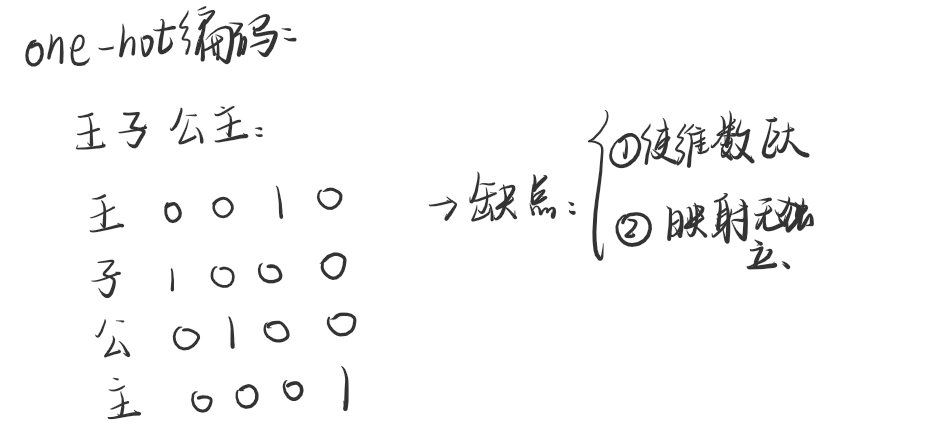
在embedding没有出现之前,我们大部分都使用的是one-hot编码,可是这种编码有什么问题呢?
首先,每一个独立的词语都设定独立的数值,会导致最后得到的矩阵格外的稀疏,太占据空间位置了。
其次,俩个独立的词语之间很难建立联系,导致这种矩阵每一行的关系相关度不是很高。
所以,我们就提出了embedding这个模型,使得 矩阵变得紧密并且 词之间有一定的相互联系。
; 二、知识图谱
这一块不准备细讲,因为网上资源还是很多的,这里就贴一个手写图,然后稍微解释一下,我们经常看见的知识图谱图片那些。

三、L0,L1,L2

参考文献中有一篇知乎的详细解释这三者的关系,主要是解释L2诞生的原因,他写的非常的详细,我就不在此文中进行赘述了。
; 四、transE的理解
前面的部分我们属于一个基础知识的回顾,其实也就是我这种小白才需要进行查看,我在很多论文解读的文章里面都没有发现他们对论文的代码进行推导或者深入的研究,我猜想一个是因为他的算法确实很简单,其次就是这个方法有一点点点老了,大家觉得研究没有必要性。
话不多说,开始。
首先,这篇论文主要讲的是TransE的形成,也就是这个算法提出的第一篇鼻祖文章。那我们来看一下,transE到底是什么?它又是怎样去进行算法实现的?
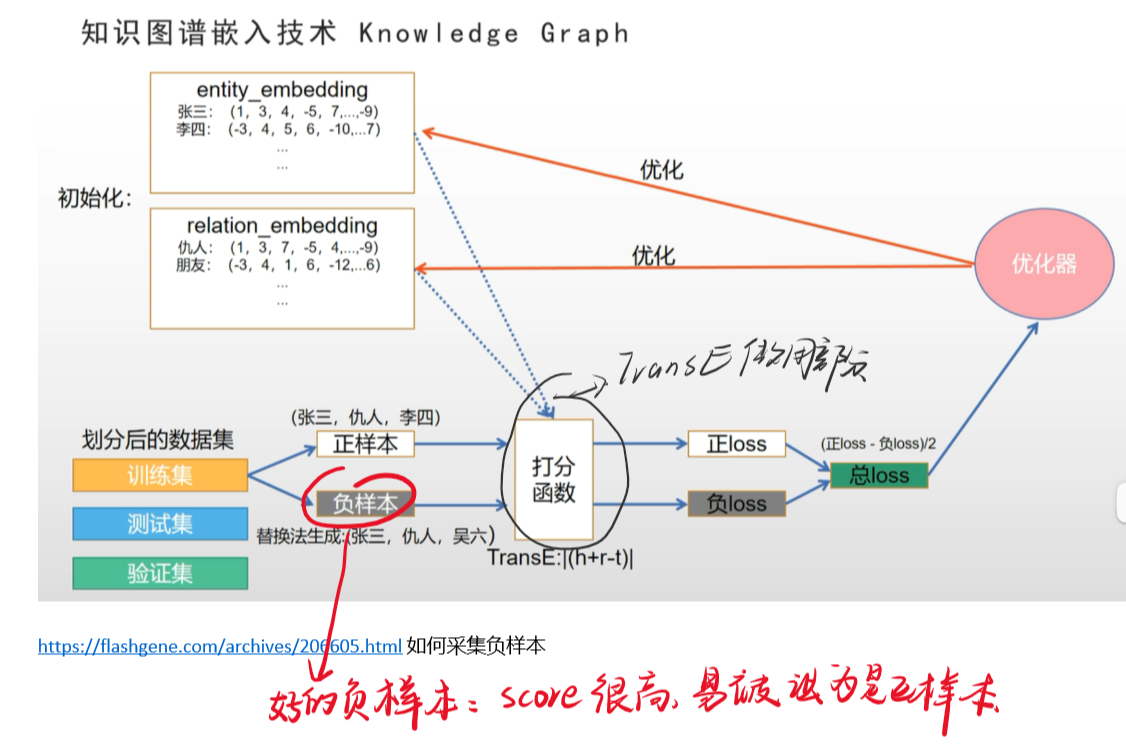
我们知道, 知识图谱是由实体和关系组成,一般实体和关系都是 以矩阵的形式存在与出现的,实体矩阵(n×d)中,一行代表的就是一个实体的词向量,n代表的是实体的数量,d代表的是实体的维度;同理关系矩阵也是一样的。下面举了一个简单易懂的例子:


transE在知识图谱嵌入技术中优化的是哪一部分的内容?
下面这一张图可以很清楚的展示,正样本与负样本一起通过一个打分函数,得到正负loss,然后将总loss计算出来放入优化器中优化,再修改实体和关系的embedding矩阵,然后再进入打分函数进行操作。
然而我们的transE运用的地方就是在 打分函数这一块,具体如何运用的,请看后文详细讲解部分。
在论文中频繁的出现 (h,l,t)这个三元组,它是理解transE的核心部分。这三元组中每一个都有自己特定的意义,h代表的是头实体,l代表的是关系,t代表的是尾实体,h和t一起构成实体集合。
正常的三元组应该是h、l、t之间的关系是对应的,没有差错的。
论文中还有一种 损坏三元组(corrupted triplets),它是头部实体或者尾部实体被随机替换形成的新的三元组,但是需要注意的是,头部和尾部不能同时替换。(原因:损坏三元组就是我们所说的负样本,如果头尾都进行替换,万一替换成为一个正确的三元组,那就失去了负样本的意义)
在论文中,h,l,t表示的都是向量,所以三元组的关系就是下方这个图片中的 对应关系:
(图片中写的是r,问题不大,因为relation也是关系的意思)

根据上面的讲解,我们似乎已经大概晓得了什么是三元组,但是好像还是有点不是特别的清楚,下面给大家举个例子。
图片部分文字说明:假设,有一个学生叫做小明,他大学毕业于湖北师范大学,那么他的h代表的就是小明,l代表的是毕业,t代表的是湖北师范大学,这就是构成了一个三元组。

transE的算法实现:

解释:
1、什么是L2范数?||W||是个什么数学公式?
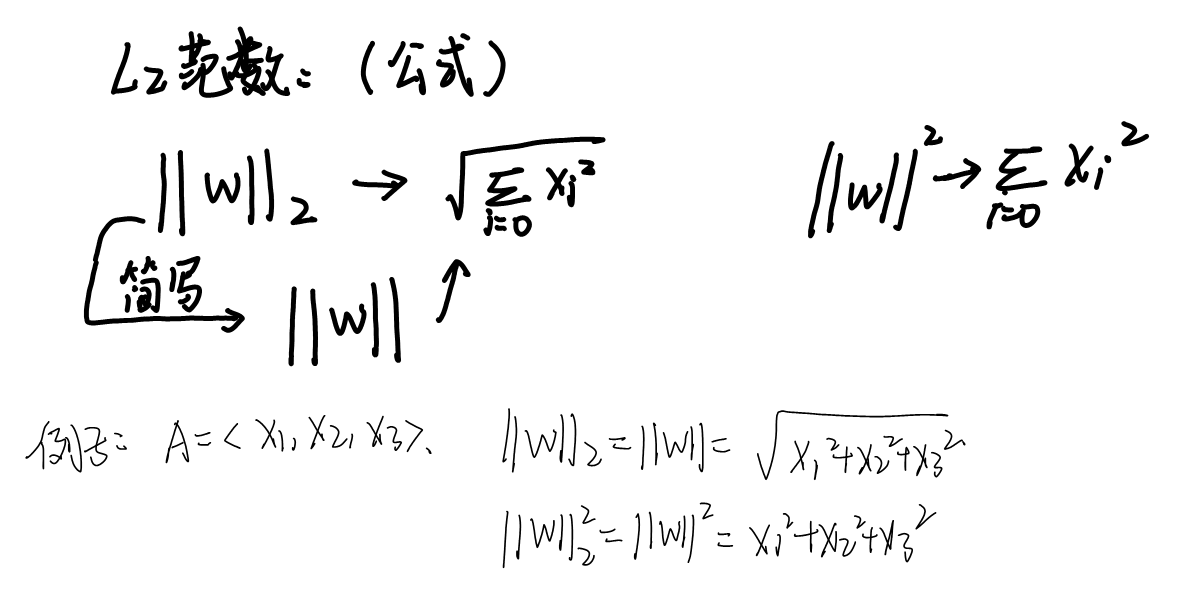
一般我们会采用L1范数或者L2范数进行归一化,在本论文中采用的是 L2范数(||e||)
2、每一行代码逐个解释;



论文中的代码的loss function,分数之间差距越大越好。对于错误的三元组,越大越好;对于正确的三元组,越小越好。

理想中的transE模型:
例子:从总实体中抽取 小明,从关系中抽取 大学毕业,我们理想化的结果是 湖北师范大学,这就是理想的transE模型(也就暴露出它的一个问题所在,后面会有所解释)

刚刚我们提到了transE的一个弊端,现在我们来详细解释这个弊端是什么?
先告诉结论: transE它适用于在一对一的关系中,但是对于多对一或者一对多关系,就会出现失效。
举一个简单的例子:
(该例子是B站UP主视频里面的一个例子)
现在有一个头实体head:张艺谋;一个关系实体label:导演;有三个尾实体tail:分别是英雄,十面埋伏,金陵十三钗。
现在我们根据论文中的意思:h+l-t → 0,也就是h+l → t,最后导致我们三个tail实体无限的趋近于相同。可是我们明显的知道,这三个实体并不是完全相同的。
所以这就就transE在一对多或者多对一的关系上的一个弊端,后来的科学家根据这些弊端研究出transH,transD等等,最后形成了 Trans系列算法。

五、参考文献
3、transE算法解析①
transE算法解析②
transE算法解析③
5、实际应用代码资源(这个好像要c币,我下载了以后还在运行代码,感觉没什么错误)
Original: https://blog.csdn.net/weixin_42198265/article/details/123931210
Author: Bessie_Lee
Title: 【论文研读】 Translating Embeddings for Modeling Multi-relational Data论文理解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/554973/
转载文章受原作者版权保护。转载请注明原作者出处!