

原创不易,求分享、求一键三连
业务场景
之前在一家直播团队做过一段时间的营收部门负责人,榜单是直播平台最通用的一种玩法,可以彰显用户的身份,刺激用户之间的pk,从而增加平台的营收,下面介绍几种榜单常见的玩法。
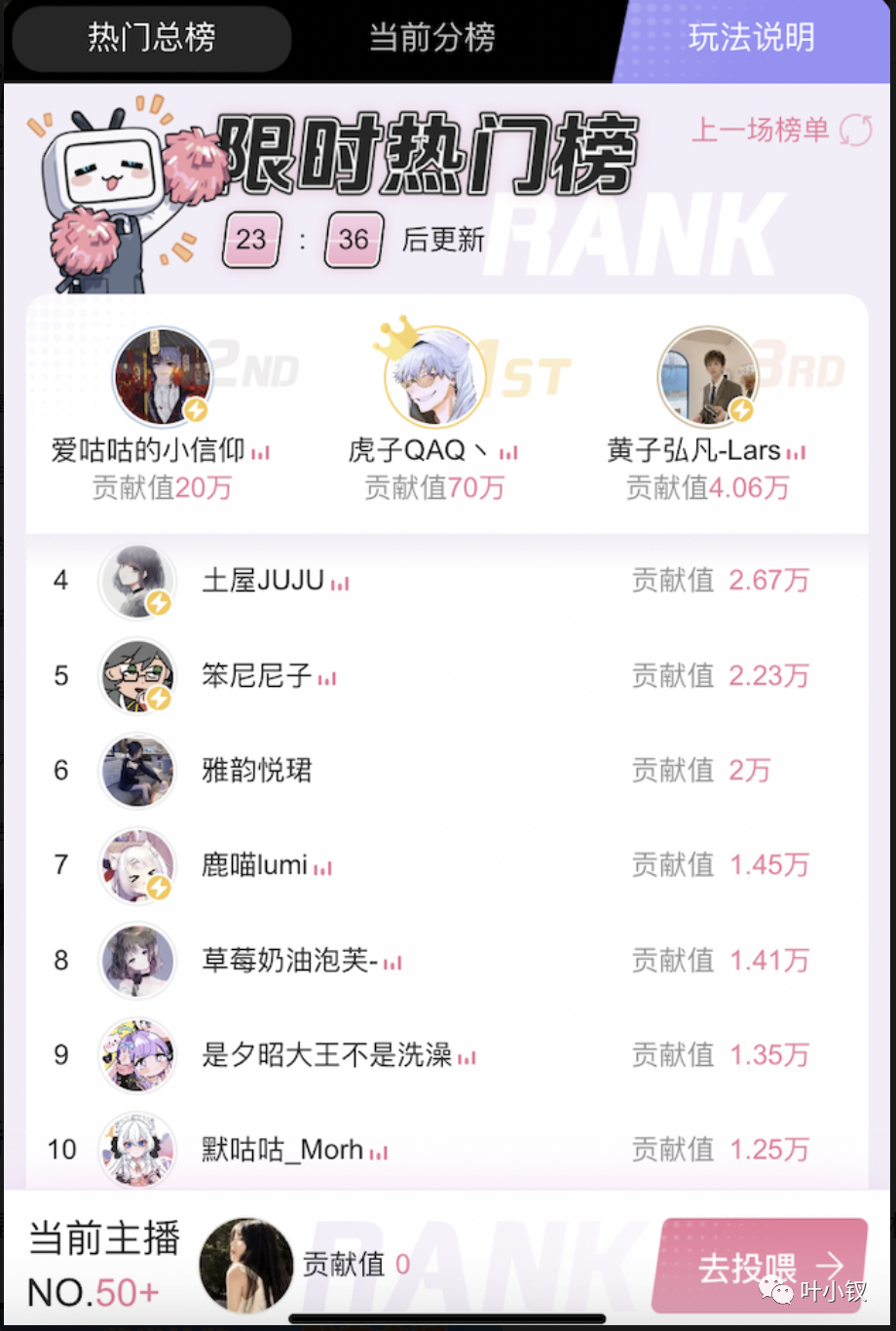
限时热门榜
玩法规则大致是每30分钟,对主播收到打赏值进行排行,其中有2类排行榜,限时热门总榜和限时热门分区榜,这里使用自然30分钟代表每个周期,每天有48个30分钟,分别有1、2、3代表每天第1、2、3个30分钟。

欧皇主播榜
玩法规则大致是主播房间内用户抽到的冰晶城堡数量的排行,页面上有3个榜单,昨日榜、今日榜、总榜。

直播重营收,营收看活动,活动看打榜,所以这种榜单每个月都会以各种形式出现,我们需要设计一套通用的榜单系统,减轻后续工作量,这是背景。
榜单分析
首先我们对业务进行抽象:

我们抽象出一些关键词:
- 用户id(user_id)
- 主播id(master_id)
- 投喂(coin)
- 时间
- 分区
时间有今日、昨日、自然30分钟。从这些榜单中我们可以抽象出统一的一套规则,榜单类型、榜单维度、榜单对象、榜单积分。
榜单规则
- *榜单类型
同一种榜单类型代表的是一类榜单,这一类榜单具备同一套逻辑规则,例如限时热门榜,虽然每30分钟会有一个榜单,但是这些榜单数据的规则是一致的。
限时热门分区榜和限时热门榜的规则是不一样的,热门分区限时榜统计的是分区的主播,限时热门分区榜统计的是全区的主播。
需要注意的是,限时热门分区榜和限时热门榜也可抽象成一类榜单。
- *榜单维度
同一类榜单可能会有多个榜单,例如限时热门榜,每个自然30分钟内都会有一个榜单,每个的榜单都是不同的,或者说是互不影响的。
限时热门分区榜,每个自然30分钟内都会有一个榜单,这里自然30分钟就是一个维度。
限时热门分区榜,每个自然30分钟内*所有分区都会有一个榜单,这里自然30分钟和分区就是一个维度。
欧皇主播日榜,活动时间内主播房间内每日用户抽到的冰晶城堡数量的排行,这里日就是一个维度。
欧皇主播日榜,活动时间内主播房间内用户抽到的冰晶城堡数量的排行,这里只有一个榜单数据,维度为空。
- *榜单对象
榜单对象指的是我们给谁进行排行,这个谁可以是用户,也可以是主播,也可以是其他,例如限时热门榜,这个榜单对象就是主播,我们需要给主播进行排行。
- *榜单对象积分
榜单对象积分比较简单,就是一个进行排序的值,例如限时热门榜,用户消费就是积分。
榜单实现
- *榜单配置
配置可以放在配置文件里面,或者可以通过后台管理系统进行管理,配置如下:
[[rank]]<br>rankname = "master_luck_day"  // 榜单类型<br>title = "欧皇主播日榜" // 榜单名称,实际业务中没有使用到,这里只做一个名称区分<br>top = 100 // 榜单最多展示n条,和业务有关<br>set = 86400 * 2 // redis set的过期时间,见下方说明<br>string_expire = 86400 // redis item的过期时间,见下方说明<br>customsort = 1 // 自定义排序规则,代表相同积分,先到的在前,见下方说明<br>[[rank]]<br>rankname = "master_luck_total"<br>title = "欧皇主播总榜" <br>top = 100  <br>set = 86400 * 30 // 假设活动过期时间是30天<br>string_expire = 86400 <br>customsort = 2
- *榜单接口
这里只展示最常见的3个接口,其它接口请在具体业务场景中添加。
incrScore:增加榜单积分,类似于redis的incr;
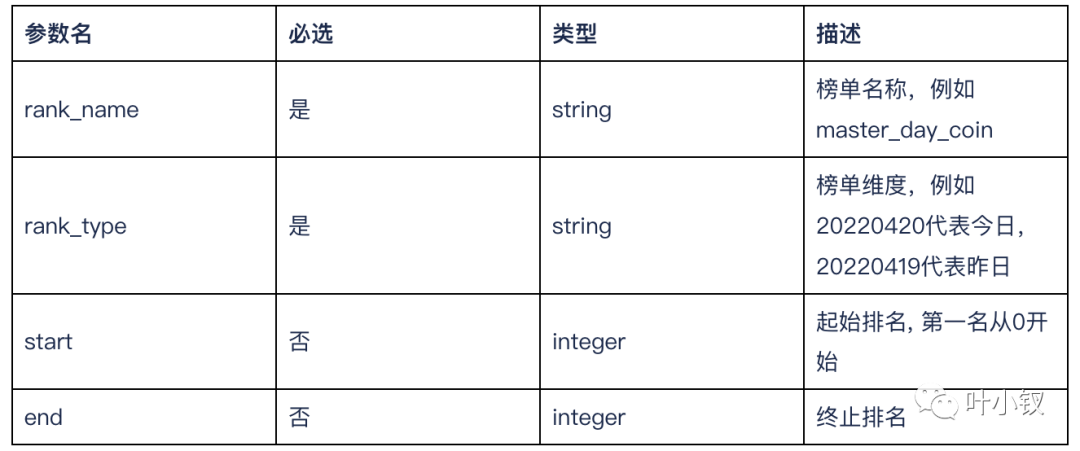
请求参数

返回结果
{<br>    "code": 0,<br>    "errcode": 0,<br>    "message": "ok",<br>    "errmsg": "ok",<br>    "data": {<br>        //  成功或失败,失败可以重试<br>        "status": true<br>    }<br>}
getScore:获取榜单分数及榜单排名;
请求参数

返回结果
{<br>    "code": 0,<br>    "errcode": 0,<br>    "message": "ok",<br>    "errmsg": "ok",<br>    "data": {<br>        //  分数<br>        "score": 0,<br>        //  排名<br>        "rank": 0<br>    }<br>}
topScore:获取榜单排名
请求参数
返回结果
{<br>    "code": 0,<br>    "errcode": 0,<br>    "message": "ok",<br>    "errmsg": "ok",<br>    "data": {<br>        //  排名数据<br>        "data": [<br>            {<br>                //  rank_item<br>                "rank_item": 0,<br>                //  排名<br>                "rank": 0,<br>                //  积分<br>                "score": 0<br>            }<br>        ]<br>    }<br>}
榜单表设计
表设计如下,在实际使用中,需要注意分库分表,索引也根据实际使用到的场景进行添加,这里只展示唯一索引:
CREATE TABLE rank (<br>  id bigint(20) unsigned NOT NULL AUTO_INCREMENT,<br>  rank_name varchar(30) NOT NULL DEFAULT '0' COMMENT '榜单类型',<br>  rank_type varchar(50) NOT NULL DEFAULT '' COMMENT '榜单维度',<br>  rank_item bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '榜单对象',<br>  score bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '积分',<br>  extra_data varchar(50) NOT NULL DEFAULT '扩展数据',<br>  rank int(11) unsigned NOT NULL DEFAULT '0' COMMENT '排名',<br>  custom_sort varchar(200) NOT NULL DEFAULT '' COMMENT '自定义排序',<br>  PRIMARY KEY (id),<br>  UNIQUE KEY uk_rank_id_rank_type_rank_item (rank_id,rank_type,rank_item)<br>) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='通用榜单表'<br>CREATE TABLE rank_log (<br>  id bigint(20) unsigned NOT NULL AUTO_INCREMENT,<br>  rank_name varchar(30) NOT NULL DEFAULT '0' COMMENT '榜单id',<br>  rank_type varchar(50) NOT NULL DEFAULT '' COMMENT '子榜id',<br>  rank_item bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '对象id',<br>  msg_id varchar(150) NOT NULL DEFAULT '' COMMENT '消息',<br>  change_score bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '变化的积分',<br>  after_score bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '变化后的积分',<br>  PRIMARY KEY (id),<br>  UNIQUE KEY uk_rank_name_rank_type_rank_item_msg_id (rank_name,rank_type,rank_item,msg_id),<br>) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='榜单更新日志表'
更新榜单积分时,同时会更新榜单日志表,通过事务更新,保持数据一致性,通过msg_id保证幂等,接口如果调用失败,可以重试,类似于用户花钱时,会更新钱包数据同时会记录流水数据。调用incr接口时,会执行下面的sql,这2条sql在同一事务中执行。
insert into rank(rank_name,rank_type,rank_item,score) values(params.rank_name,params.rank_type,params.rank_item,params.score) insert on dumplicate update score = params.score;<br>insert into rank_log(rank_name,rank_type,rank_item,score,msg_id) values(params.rank_name,params.rank_type,params.rank_item,params.score,params.msg_id);
需要注意的是数据库会保存全量排行榜数据。
事务说明
使用事务更新是否有必要?能否直接通过缓存做幂等?
确实在一般情况下使用缓存做幂等(set key … nx px),然后辅以日志查询就足够了,使用流水日志对一致性更好,同时查询问题更加方便,但是对 数据库的压力更大,可以根据实际业务场景选用合适的技术方案。
榜单缓存设计
在一般业务中,榜单只需要展示topn的排名数据,例如top10,top100等,并且在有一定体量的公司中,数据库都不能直接对外,必须在数据库上层加一层缓存。
- *榜单排名数据
榜单排名数据使用的是zset实现,zset的key为榜单名称+子榜id, zset的member为对象id,score为榜单积分。更新榜单时,做如下操作:
_rankListKey = "rank:list:%d:%s"<br>rankListKey := fmt.Sprintf(_rankListKey, params.RankName, params.RankType)<br>// 下面的redis操作可以使用一些优化手段,例如pipline,此处为示例<br>redis.zAdd(_rankListKey, score, rank_item) // score代表的是该榜单对象当前的积分<br>redis.Expire(_rankListKey,  config.set_expire) // config.set_expire为配置set的的过期时间<br>redis.zrembyscore(_rankListKey,0,last_rank_score - 1) //last_rank_score代表的是第top名的积分,删除0到最后一名之间的数据,保证数据只有top个
zset的过期时间大于榜单更新最大时间,如下所示:
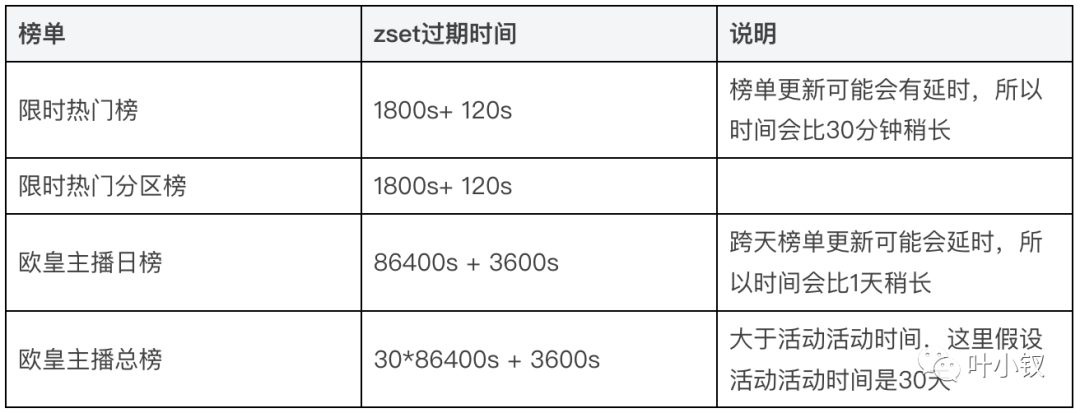
需要注意的是,zset的member数量是需要限制的,不然可能会有大key和热key的问题。
- *榜单积分数据
业务场景中需要展示某个主播具体的有多少积分。榜单排名数据使用的是string实现, key为榜单类型+榜单维度+榜单对象,value为榜单积分。
此处可能会有人会有疑惑,为啥会需要需要榜单积分缓存?
- zset限制member数量大小;
- 业务场景需要展示超过topn的积分,如上第2张图;
_rankItemKey = "rank:item:%d:%s:%d"<br>rankItemKey := fmt.Sprintf(_rankItemKey, params.RankName, params.RankType, params.RankItem)<br>score, err := redis.get(rankItemKey)<br>if err == redis.ErrNil {<br>    // 回源数据库,查询积分,得到rscore<br>    redis.set(rankItemKey, rank_item, rscore + params.score, config.string_expire)    // config.string_expire为配置的的过期时间<br>    err = nil<br>    return nil<br>} else if err != nil {<br>    // 返回错误,业务可以重试<br>    return err<br>}<br>redis.incr(rankItemKey, params.rank_item,params.score) 
榜单积分缓存数据量会比榜单排名缓存多很多,过期时间可以根据redis服务容量进行配置,可以在榜单更新时间内失效。
最后给一个流程图:
榜单更新流程

榜单实现案例
- 限时热门榜/限时热门分区榜实现
当用户在直播间消费时,增加榜单数据,参数入下:

- 欧皇主播日榜/欧皇主播总榜实现
当用户在直播间抽奖抽到指定道具时,增加榜单数据,参数如下:

进阶场景
近7日榜的实现
主播近七日收到用户打赏之和的排行,这里近七日是一个滑动窗口概念,例如20200420代表的是20200414 ~20200420这7日。
- *业务分析
榜单维度,可以用日期来标识,例如20200420代表的是20200414 ~20200420这7日 榜单对象,主播 榜单积分,主播近7日收到的积分之和
- *方案1
存在两种榜单数据,一个是七日的榜单数据(实际使用),一个是每日的榜单数据(辅助使用)。
每日凌晨启动定时任务将前6日的日榜数据加到近7日的榜单数据中,数据是从数据库中获取,获取的是全量数据,当凌晨用户投喂时,会实时更新七日榜单的数据,也就是说脚本积分数据和实时积分数据是同时在跑的,理论上,当脚本跑完时,数据会是正确的。
这种方案好处是简单,可以快速实现,坏处需要定时任务,且数据不是平滑更新的,定时任务执行期间数据不准确。
- *方案2
方案2没有使用每日的辅助榜单数据,每次更新数据时会同步更新今日的七日榜和后6天的七日榜,例如今天是2022-04-20,如果增加1积分,会同时更新20220420七日榜、20220422七日榜、20220423七日榜、20220424七日榜、20220425七日榜、20220426七日榜。
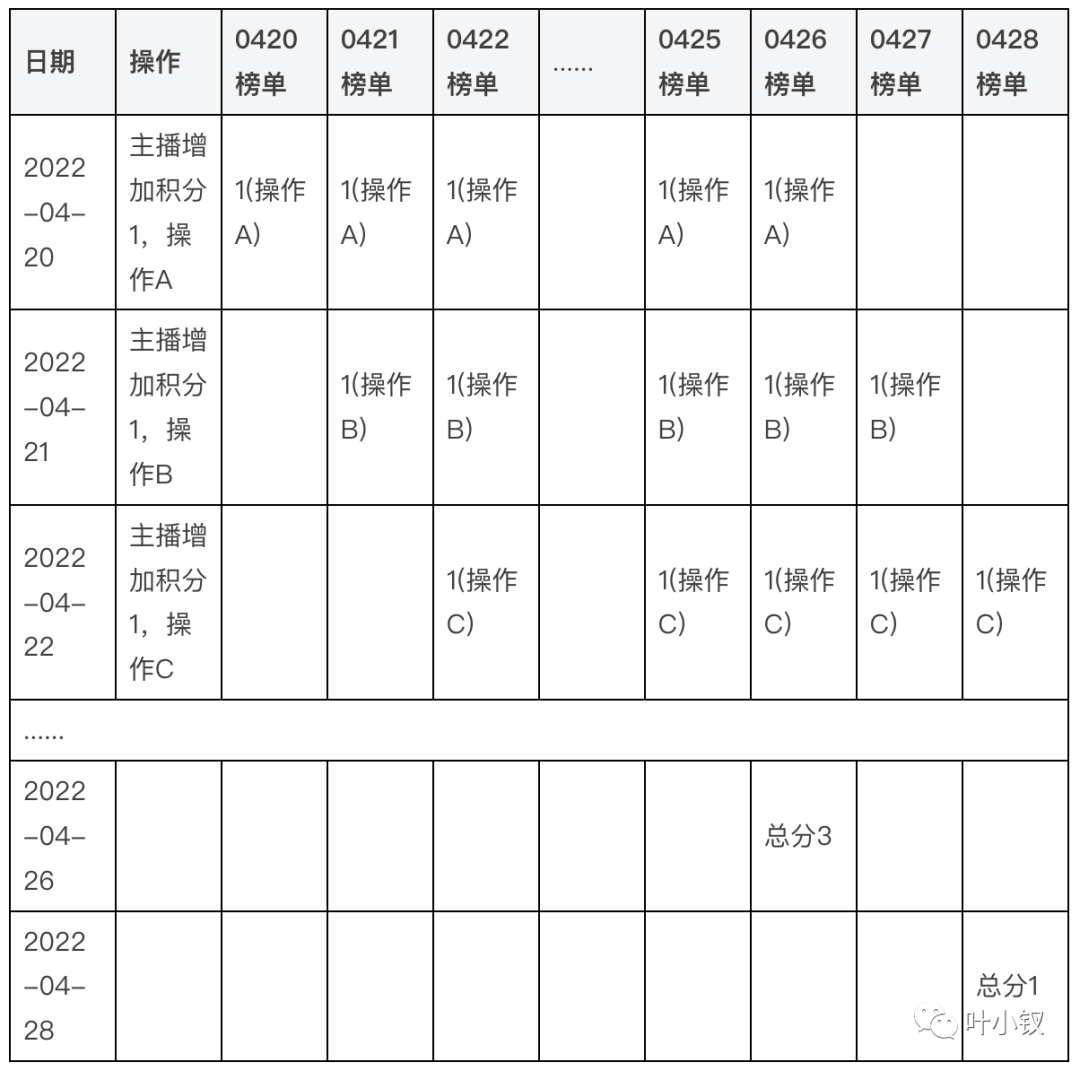
当到了26日时,主播1的20220426七日榜的积分会为3;当到了27日时,主播1的20220427七日榜的积分会为2;当到了28日时,主播1的20220428七日榜的积分会为1;当到了29日时,主播1的20220429七日榜的积分会为0。
这种方案好处是没有定时任务,数据是平滑更新的,坏处是接口请求会放大,同时会更新很多条数据,基本无法支持近30天的场景,且业务调用较为复杂。
- *方案3
更新数据时更新今日的七日榜数据,同时更新明天的七日榜数据(如果没有脚本相当于是今日的日榜数据),并且记录每日的数据,每日中午会将前5日每日的数据加到明日的7日榜中。

我们一起看一下20220423七日榜的数据的正确性,20220423七日榜在2022-04-22增加积分1,在2022-04-22中午,将2022-04-17 ~ 2022-04-21这5天日榜的数据共2分加到了20220423七日榜中,在2022-04-23主播1增加1积分增加了积分1,主播积分为4。
这个方案的好处是数据是平滑更新的,可以实现任意时间阶段的连续榜单,且调用简单,连续榜的逻辑已是在服务内部实现,坏处是实现较为复杂。
榜单积分相同如何排序?
zset存在一个问题,就是相同积分时,zset会按照member的字典序进行排序,有些业务场景,可能会对相同积分的也需要进行排序,例如相同积分,先到在前。榜单配置中增加有customsort字段, 1代表按时间正序排序, 2代表按时间倒序排序。
数据库存在custom_sort字段,如果按照时间正序排序,为负数的时间戳,如果按照时间倒序排序,为正数的时间戳。
每次更新积分数据后,搜索数据库与该对象积分相同的数据(最多top条,根据配置,下面用1000来说明),sql语句为:
select item_id from rank where rank_name = params.rank_name and rank_type = params.rank_type and score = cur_score order by custom_sort desc limit 1000 
然后将score积分加上一个小数,从0.999至0,将相同的数据添加至zset之中,从而实现相同积分排序。
如何实现排名变化趋势?
有些榜单场景会有主播今日的排名会和逐日昨日的排名进行比较,看是上升、下降还是不变?
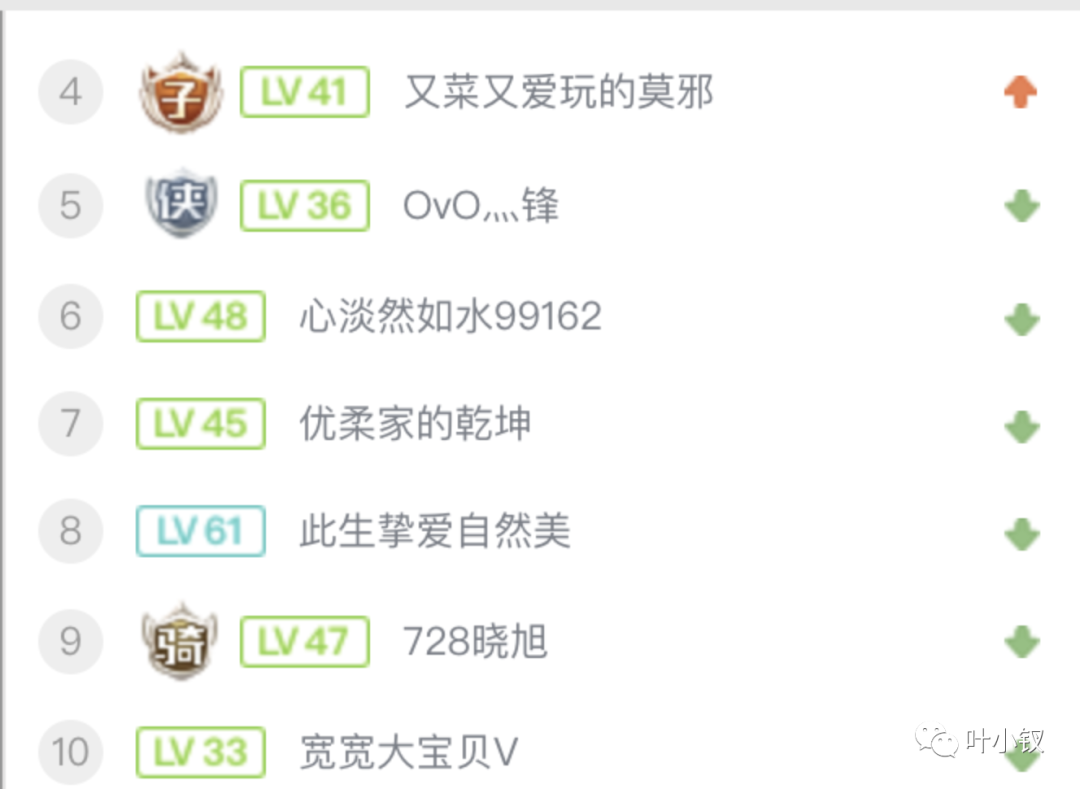
例如主播今日投喂榜需要实现排名变化趋势,可以每天零点执行脚本,获取榜单上一个周期的排行数据,也就是昨日的topn排名的主播排行信息,写到今日的榜单数据中,并且将昨日排名数据,写到今日的排行数据中,字段使用extra_data,当获取榜单排行时,可以获取到extra_data数据,当前排名和昨日排名数据进行比较即可得到变化趋势,若没有获取到extra_data数据,即昨日没有上排行榜,变化趋势为向上。
这个方案有个小问题,就是不够平滑,但该功能实时性要求较小,可以忽略。extra_data怎么使用缓存、怎么平滑展示数据留个大家去思考。
以上就是一个实际业务场景,以及面对这个业务场景时候如何提升开发效率的case。
好了,今天的分享就到这,喜欢的同学可以四连支持:

想要更多交流可以加群讨论:

Original: https://www.cnblogs.com/yexiaochai/p/16221926.html
Author: 叶小钗
Title: 大流量、业务效率?从一个榜单开始
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/554274/
转载文章受原作者版权保护。转载请注明原作者出处!