

目录
聚类分析(Cluster Analysis)是研究事物分类的基本方法,基于我们所研究的指标或数据之间存在着不同程度的相似性或者相异性。聚类分析采用定量数学方法,根据样品或指标的数值特征对样品进行分类,从而辨别出各样品之间的亲疏关系。聚类分析是一种使用简单但是很常用的分析方法,往往被用来经验性类型的探索,而不是用来检验实现所定的假设,聚类分析分成两个宽泛的类别,包括划分聚类分析和层次聚类分析。
9.1划分聚类分析
划聚类分析的基本思想是将观测到的样本划分到一系列事先设定好的不重合的分组中去,划分聚类分析方法在计算上相比层次聚类分析方法药相对简单而且计算速度更快一些,但是它也有自己的缺点,它要求实现指定样本聚类多的精确数目,这与聚类分析探索性的本质是不相适应的。划分聚类分析包括两种:一种是K各平均数的聚类分析方法,此方法的操作流程是通过迭代过程将观测案例分配到具有最接近的平均数的组,然后找出这些聚类;另一种是K个中位数聚类分析方法,此方法的操作流程是通过迭代过程将观测案例分配到具有最接近的中位数的组然后找出这些聚类。
数据(案例9.1)是我国2006年各地区能源消耗的情况。根据不同省市的能源消耗情况,对其进行划分聚类分析,以便了解我国不同地区的能源消耗情况。变量分别是地区、单位地区生产总值煤消耗量/吨、单位地区生产总值电消耗量/千瓦/时、单位工业增加值煤消耗量/吨。
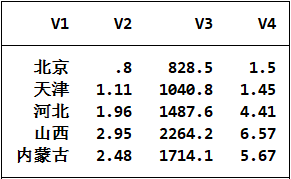

1.数标准化处理
egen zv2=std(V2) #本命令旨在对V2进行标准化处理
egen zv3=std(V3) #本命令旨在对V3进行标准化处理
egen zv4=std(V4) #本命令旨在对V4进行标准化处理
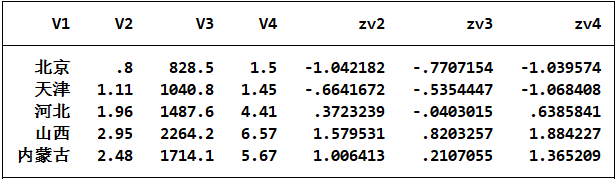
分析过程前三条命令时对数据进行一个标准化处理,选择的标准化处理方式是使变量的平均数为0而且标准差等于1。之所以这样做是因为我们进行聚类分析的变量都是以可比的单位进行的测度,他们具有极为不同的方差,我们对数据进行标准化处理可以避免使结果收到具有最大方差变量的影响。
sum zv2 zv3 zv4 #本命令旨在对zv2\zv3\zv4变量进行描述性统计
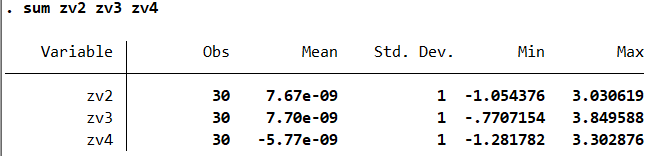
通过观察分析结果,我们可以看出一共有30个样本进行了参议。每个变量的平均值、方差、最小值、最大值都可清楚观察到。
2.K个平均数的聚类分析
cluster kmeans zv2 zv3 zv4,k(2)
#本命令的含义是对zv2\zv3\zv4进行K个平均数的据类分析,并把样本分为2类
cluster kmeans zv2 zv3 zv4,k(3)
#本命令的含义是对zv2\zv3\zv4进行K个平均数的据类分析,并把样本分为3类
cluster kmeans zv2 zv3 zv4,k(4)
#本命令的含义是对zv2\zv3\zv4进行K个平均数的据类分析,并把样本分为4类
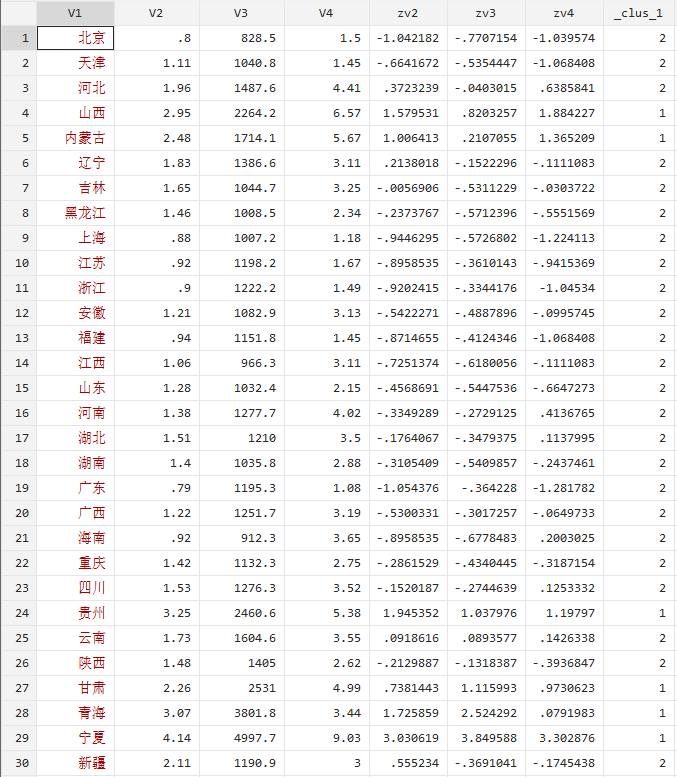
这个_clus_1便是把样本分为两类的命令展示,我们可以看到所有的而观测样本被分为了两类:其中,山西、内蒙古、甘肃、青海、宁夏被分到第一类,其他省市的被分到第二类。我们可以看到第一类的特征是单位地区生产煤总值消耗量、单位地区生产总值电消耗量以及单位工业增加煤消耗量都相对较高,我们可以把第一类归为高耗能省市,第二类为低耗能省市。后面的分为3类和四类结果不再过多赘述。分类多了的划我们很难看出各个类别的特征,这时我们可以对数据进行排序操作:sort _clus_3
3.K个中位数的聚类分析
cluster kmedians zv2 zv3 zv4,k(2)
cluster kmedians zv2 zv3 zv4,k(3)
cluster kmedians zv2 zv3 zv4,k(4)
sort _clus_6
结果不再过多赘述
案例延伸
1.采用其他相异性指标
在上面的实例中,聚类分析试用的相异性指标是系统默认选项,也就是欧氏距离。除此之外,还有其他给予连续变量观测的相异性指标可以试用,包括欧氏距离的平方、绝对值距离、最大值距离、相关系数相似度量等。例如,设定聚类数为2,然后试用K各平均数的聚类分析方法,采用欧氏距离的平方这以相异性指标。
cluster kmeans zv2 zv3 zv4 ,k(2) measure(L2squared)
结果解读与前面类似,这里不再赘述。可以发现这两种测量方法下的聚类分析结果差别很大的。给予连续变量观测量的相异性指标与对应命令如下。
基于连续变量观测量的相异性指标对应命令
欧氏距离L2欧氏距离的平方L2squared绝对值距离L1最大值距离Linfinity相关系数相似度两cirrelation
2.设置聚类变量的名称
cluster kmeans zv2 zv3 zv4 ,k(2) measure(L1) name(abs)
3.设置观测样本为初始聚类中心
可以根据拟聚类数,设置前几个观测样本为初始聚类中心进行聚类。
例如,设定聚类数为3,然后试用K个平均数的聚类分析方法,采用绝对值距离的相异性指标,把产生的聚类变量取名为abcd,设置前几个观测样本为初始聚类中心进行聚类。
cluster kmeans zv2 zv3 zv4,k(3) measure(L1) name(abcd) start(firstk)
4.排除作为初始聚类中心的观测样本
cluster kmeans zv2 zv3 zv4,k(3) measure(L1) name(abcd) start(firstk,exclude)
9.2层次聚类分析
层次聚类分析方法与划分聚类分析方法的原理不同,它的基本思想是根据一定的标准使得最相近的样本聚合到一起,然后逐步放松标准使得次相近的样本聚合到一起,最总实现完全聚类,即把素有的观测样本会寄到一个组的一种聚类方法。与划分聚类分析方法响笔,层次聚类分析方法的计算过程更加复杂,计算速度相对较慢,但是它不要求事先指定需要分类的数量,这一点是符合聚类分析探索性的本质特点的,所以这种聚类分析方法应用页非常广泛。
数据(案例9.2)党的十八大报告指出要千方百计增加居民收入,要提高居民收入在国民收入中的比重,要提高劳动报酬在初次分配中的比重。下图是我国2005年各地城镇居民平均每人全年家庭收入来源统计表。按照相关统计口径,各城镇居民收入来源分为工薪收入、经营净收入、财产性收入、转移性收入4个方面。试用层次聚类分析方法对全国各地区的收入来源结构进行分类,并进行简要的论述分析。变量分别为年份、工薪收入、经营净收入、财产性收入、转移性收入。
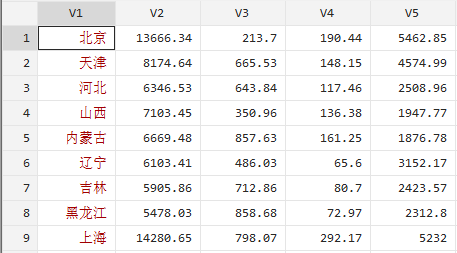
层次聚类分析的方法有很多种,包括最短联结法聚类分析,最长联结法聚类分析、平均联结法聚类分析、加权平均联结法聚类分析、中位数联结法聚类分析、重心联结法聚类分析、ward联结法聚类分析等。
1.最短联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析

上图我们可以看到每个新变量的参与对象是多少(obs=31)、平均值、标准差、最大值和最小值。
cluster singlelinkage zv2-zv5 #旨在对变量进行最短联结法聚类分析进行分析
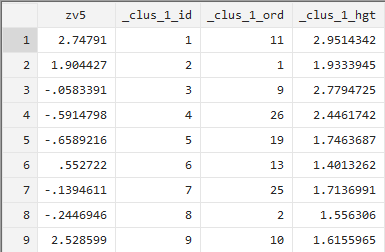
执行上述命令后,我们可以看到层次聚类分析方法产生的聚类变量是与划分聚类分析方法不同得。它包括三个部分:_clus_1_id、_clus_1_ord、_clus_1_hgt。其中_clus_1_id表示的是系统对该观测样本的初始编号;_clus_1_ord表示的是系统对该观测样本进行聚类分析处理后的编号;_clus_1_hgt表示的是系统对该观测样本进行聚类计算后的值。
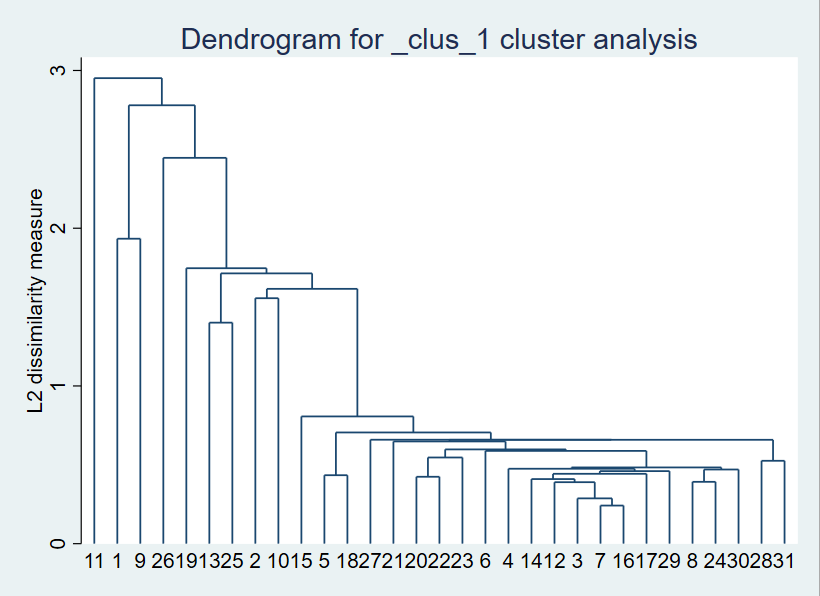
cluster dendrogram #旨在产生聚类分析树状图来描述层次聚类分析的结果
2.最长联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析
cluster completelinkage zv2-zv5 #旨在用最长联结法聚类分析进行分析
cluster dendrogram #旨在产生聚类分析树状图来描述层次聚类分析的结果。
3.平均联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析
cluster averagelinkage zv2-zv5 #旨在用平均联结法聚类分析进行分析
cluster dendrogram #旨在产生聚类分析树状图来描述层次聚类分析的结果。
4.加权平均联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析
cluster waveragelinkage zv2-zv5 #旨在用加权联结法聚类分析进行分析
cluster dendrogram #旨在产生聚类分析树状图来描述层次聚类分析的结果。
5.中位数联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析
cluster medianlinkage zv2-zv5 #旨在用中位数联结法聚类分析进行分析
cluster dendrogram #旨在产生聚类分析树状图来描述层次聚类分析的结果。
6.重心联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析
cluster centroidlinkage zv2-zv5 #旨在用重心联结法聚类分析进行分析
重心聚类分析是无法绘制树状图的。
7.Ward联结法聚类分析
egen zv2=std(V2) #旨在对V2变量进行标准化处理
egen zv3=std(V3)
egen zv4=std(V4)
egen zv5=std(V5)
sum zv2 zv3 zv4 zv5 #对新生成的标准化变量进行描述性统计分析
cluster wardslinkage zv2-zv5 #旨在用ward联结法聚类分析进行分析
cluster dendrogram #旨在产生聚类分析树状图来描述层次聚类分析的结果。
案例延伸
在上面各种层次聚类分析中,如果样本比较多,可能图中就显得比较乱,可以试用产生聚类变量的方法对样本进行有拟分类数的聚类。例如把所有样本分成四类和两类。聚类分析完后输入下面的命令。
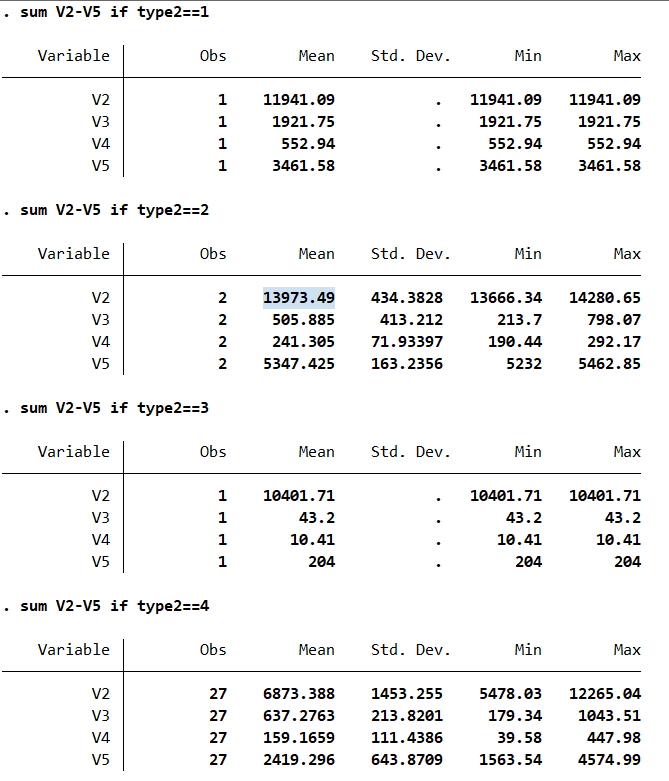
cluster gen type1=group(4) #本命令的含义是产生聚类变量type1,使用层次聚类分析方法,把样本分为四类。
cluster gen type2=group(2) #本命令的含义是产生聚类变量type2,使用层次聚类分析方法,把样本分为2类。
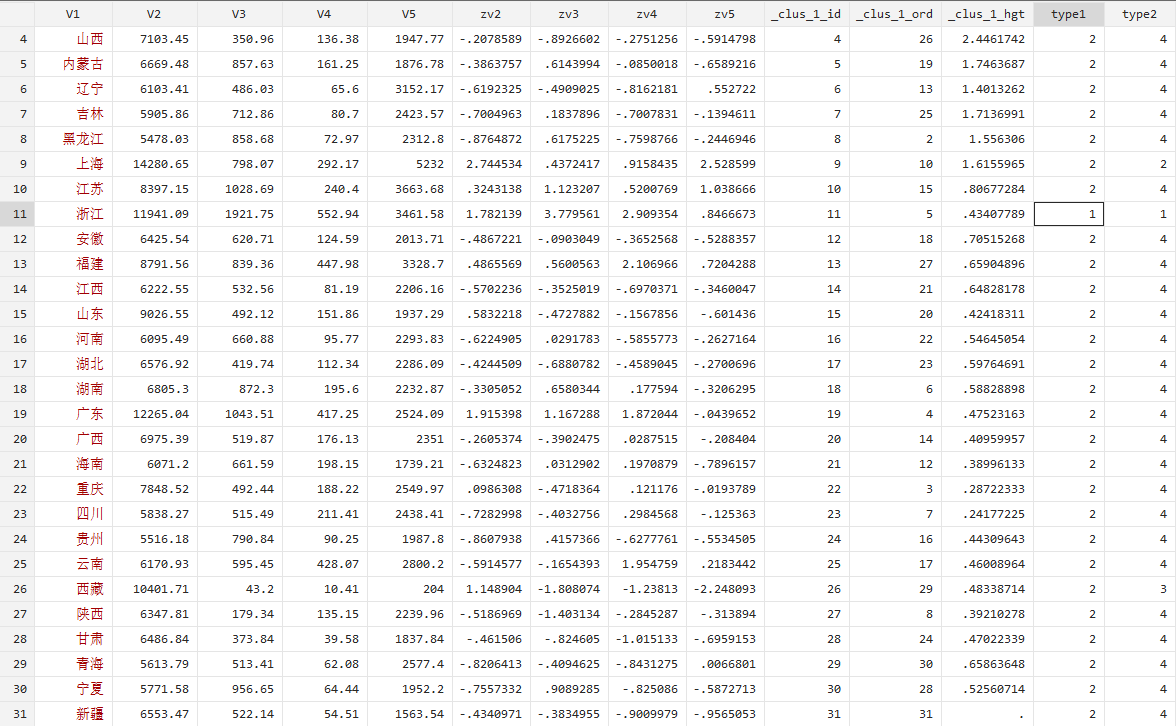
我们可以看到所有观测样本被分为了4类(type2);其中,浙江省被分到第1类,上海、北京为第2类,西藏为第3类,其他省份为第4类。可以发现第1类的特征是经营收入(V3)、财产性收(V4)入高;第2类的特征是工薪收入(V2)、转移性收入高(V5);第3类的特征是收入水平普遍较低;第4类的特征是所有收入都在中间水平。
其他联合不再过多赘述,自行解读。
Original: https://blog.csdn.net/qq_45112156/article/details/118389163
Author: 查尔斯-狩乃
Title: 第9章 Stata聚类分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/550890/
转载文章受原作者版权保护。转载请注明原作者出处!