

Deep embedding network for clustering
网络结构


和普通autoencoder相似,区别在于损失函数上。
; 损失函数
损失函数分为三部分,一个是重构误差,和普通的autoencoder一样,就不赘述了;一个用来保持局部分布不变(Locality-preserving);另外一个使隐层表达变得稀疏(Group Sparsity )。
Locality-preserving

其中,k ( i ) k(i)k (i )是点i i i的k k k个近邻(即knn算出的邻居),S i j S_{ij}S i j 衡量点i 、 j i、j i 、j之间的相似度。所以这个损失的含义就是,计算点i 、 j i、j i 、j在新的向量空间上的差异,S i j S_{ij}S i j 可以等价为权重,计算方式如下:
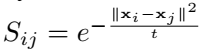
其中,t是超参。
这个损失可以保证每个点与它周围的k的点距离最小化。
; Group Sparsity
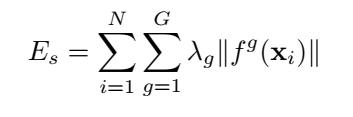
假设隐层向量表达的维度为d d d,数据中有G G G簇,将隐层表达的d d d个维度随机分为G G G份(互不相交),这样对分出的每一份就可以表达为f g ( x i ) f^g(x_i)f g (x i )。
前面的稀疏λ g \lambda_g λg 是权重,对于分出的第g g g组而言,这一组的规模越大,那么权重越大,计算方式如下:

其中,n g n_g n g 代表第g g g组的大小,λ \lambda λ为常数。
可以看出,这个损失是对每个点的每一组的L1范式求和,造成的结果就是组间稀疏性,(论文中使用的词叫做block-diagonalized(块对角化))也就是说隐藏当中只有少量的组的值为非零的(论文中的理想情况是只有1组为非零的,然后这一组的g就对应了第g簇)。
总损失

α , β \alpha, \beta α,β都是超参。
; 预训练
使用了限制玻耳兹曼机来逐层优化,过程如网络架构中展示的一样,很好理解。
Original: https://blog.csdn.net/eternal_city/article/details/121585193
Author: 吾道长存
Title: Deep embedding network for clustering论文笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/550562/
转载文章受原作者版权保护。转载请注明原作者出处!