
这一节主要总结一下语音助手中对于潜在技能与未召回话术挖掘相关的内容,主要分为以下几点:1、为什么要做潜在技能的挖掘;2、如何挖掘。
为什么要做潜在技能的挖掘
随着语音助手日活的逐渐增多,用户需求的场景也逐渐增多,产品在定义场景时,除了基于用户群体分析以及竞品分析外,也可以基于大数据挖掘的方式来快速发现用户需求最多的场景。这也叫做热门话题挖掘,比如通过日志分析,可以发现用户在春节期间对于购买火车票的需求突然增多,此时可以快速响应搭建对应的场景能力。
除此之外,也可以用此技术来发现之前定义的场景没有覆盖到的话术类型。比如日程场景中,有些用户定日程时可能会表述:”晚上8点在305举行活动”,这种直接”时间+动作”的定日程的表述方法是我们之前定义场景时没有覆盖到的,通过该话术的挖掘,可以有效提升日程场景的日活和留存。
长尾技能有以下几个特点:
- 待挖掘池子大,每日query量级在400w左右,经过策略粗筛后仍有50w左右。
- 噪声多,池子中存在大量无效数据,包括误收音、杂音、无意义话术等。
- 意图数量多且比较杂,在池子中能够挖掘到的有效意图,每日可到上千个,并且不重复。
如何挖掘
由于是未经定义过的场景,或者已经定义过但是没有覆盖的话术表述,所以通过已有的分类模型或者意图模型,是很难直接有效挖掘到的,所以在这里一般会采用 聚类的方式来做。既然涉及到聚类,就涉及到以下几个问题:1、编码选择。2、聚类方法。3、特征缩放与距离选择。4、聚类稳定性。5、评价指标。
1、编码选择
顾名思义,编码选择就是选择query的编码类型,常见的方式有:TF-IDF,腾讯词向量,bert向量等。经过我们的实验,发现经过领域适应的bert输出的向量用于聚类是效果最好的,在ARI(调整的兰德系数)指标上可以高出TF-IDF 20个点左右。在使用时,可以将bert对query的编码向量进行平均,得到固定长度的向量当做句向量使用。
2、聚类方法
聚类方法可以选择常见的k-means,层次聚类,dbscan等,这里我们选用的为k-means,主要是由于层次聚类这些性能和内存占用上比较高,导致效率很低,这里不再展开对比这些聚类方法的差异了。使用k-means时,可以使用手肘法来确定k的值。
3、评价指标
在聚类中,用于衡量聚类效果好坏的评价指标,一般有:兰德系数、调整的兰德系数、轮廓系数等。
3.1 兰德指数RI与调整兰德指数ARI
Rand Index计算样本预测值与真实值之间的相似度,RI取值范围是[0,1],值越大意味着聚类结果与真实情况越吻合。
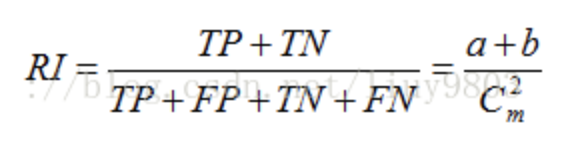

其中C表示实际类别信息,K表示聚类结果,a表示在C与K中都是同类别的元素对数,b表示在C与K中都是不同类别的元素对数,由于每个样本对仅能出现在一个集合中,因此有TP+FP+TN+FN=C2m=m(m-1)/2表示数据集中可以组成的样本对数。
对于随机结果,RI并不能保证分数接近0,因此具有更高区分度的Adjusted Rand Index被提出,取值范围是[-1,1],值越大表示聚类结果和真实情况越吻合。
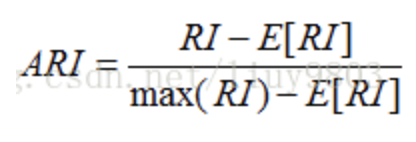
3.2 轮廓系数

其中兰德系数&调整的兰德系数的优点是可解释,可以评价不同query表示的句向量,但是缺点在于需要提前知道类别标签。轮廓系数的优点是不需要知道类别标签,缺点是对于簇结构为凸的数据轮廓系数较高,对于簇结构非凸的轮廓系数较低,这就导致轮廓系数不能在不同的算法之间比较优劣,如统一数据下,可能KMeans的结果就比DBSCAN要好。
在这个任务中,我们使用的是调整的兰德系数(ARI),主要是经过试验,该指标对于该任务中query的区分度最好。
4、特征缩放与聚类选择
有了评价指标,下面则需要距离的表示方法,一般来讲衡量两个向量之间的距离主要是余弦距离和欧氏距离。关于这两者的解释引用一下知乎中的内容:

了解了两种聚类的衡量方式,下面来看下特征缩放相关的内容。这里主要用的时归一化和l2正则化,关于为什么要进行归一化,可以看下何凯明大神的一篇论文: <你可能不需要BERT-flow:一个线性变换媲美BERT-flow>,归一化是一种特征缩放技术,改变样本特征的分布空间,是一种线性变化,其并不会改变样本的特征分布类型,比如之前是正太分布,则经过归一化之后其还是正太分布。归一化之后,可以将不同量纲之间的特征放到同一个空间,同时起到加速算法收敛的作用。
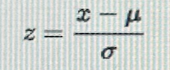
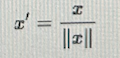
在本任务中,我们使用的是标准化+l2正则化+欧氏距离,其效果最好。
5、聚类稳定性
对于同一批数据,多次聚类之后如何找到聚类稳定的簇,这么做的目的主要是去除噪声数据,提高聚类结果的质量,它基于一个假设:边界越明显的数据,聚类一致性越强,而噪声数据在多次聚类中会被分到不同的簇中。
主要从两个角度衡量聚类的稳定性:1、多次聚类某个中心频繁出现;2、某两个pair多次被预测为同一个类别。具体做法为:分别进行两次聚类,1、两次聚类中心靠近聚类达到一定范围的认为属于一个聚类中心(超参数),统计其中心出现的次数;2、限制某个聚类类别的样本数量,丢弃数量太少的类别(超参数);3、两次聚类的ARI的指标均大于某个值(超参数)。将融合后的结果再统计ARI指标来评估融合后效果。
经过这些方法,可以验证经过多次融合后,算法的稳定性会越来越强,聚类结果的有效数据也会变多。
引用:
Original: https://blog.csdn.net/mingzheng114/article/details/122753621
Author: Turned_MZ
Title: 语音助手——潜在技能与未召回话术挖掘
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/550416/
转载文章受原作者版权保护。转载请注明原作者出处!