

最近我们被客户要求撰写关于聚类的研究报告,包括一些图形和统计输出。
目标
对”NCI60″(癌细胞系微阵列)数据使用聚类方法,目的是找出观察结果是否聚类为不同类型的癌症。K_means 和层次聚类的比较。
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
,时长06:05
#数据信息
dim(nata)


nci.labs[1:4]
 
 
table(ncibs)
 

 
ncbs
 

scale # 标准化变量(均值零和标准差一)。
全链接、平均链接和单链接之间的比较。
plot(hclust,ylab = "",cex=".5",col="blue") #使用全链接对观察结果进行层次聚类。

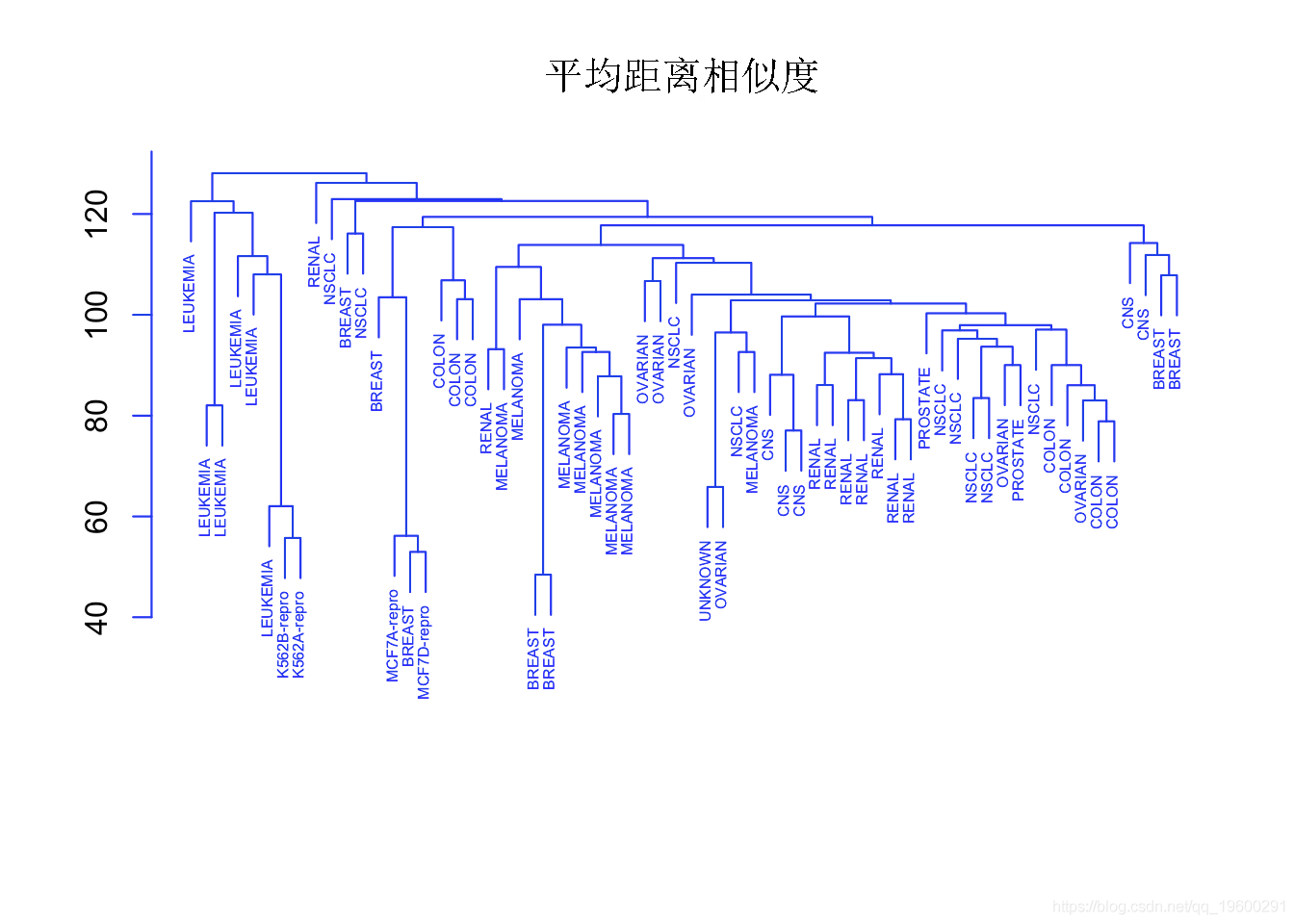
plot(hclust,cex=".5",col="blue") #使用平均链接对观察进行层次聚类。
<a id="cb12-1">;</a>
par(mfrow=c(1,1))
plot(hclust,col="blue") #使用单链接对观察进行层次聚类。

观察结果
单链接聚类倾向于产生拖尾的聚类:非常大的聚类,单个观测值一个接一个地附在其中。
另一方面,全链接和平均链接往往会产生更加平衡和有吸引力的聚类。
由于这个原因,全链接和平均链接比单链接层次聚类更受欢迎。单一癌症类型中的细胞系确实倾向于聚在一起,尽管聚类并不完美。
 
table(hrs,ncbs)
 

我们可以看到一个清晰的模式,即所有白血病细胞系都属于聚类 3,其中乳腺癌细胞分布在三个不同的聚类中。
 
plot(hcu)
abline
 
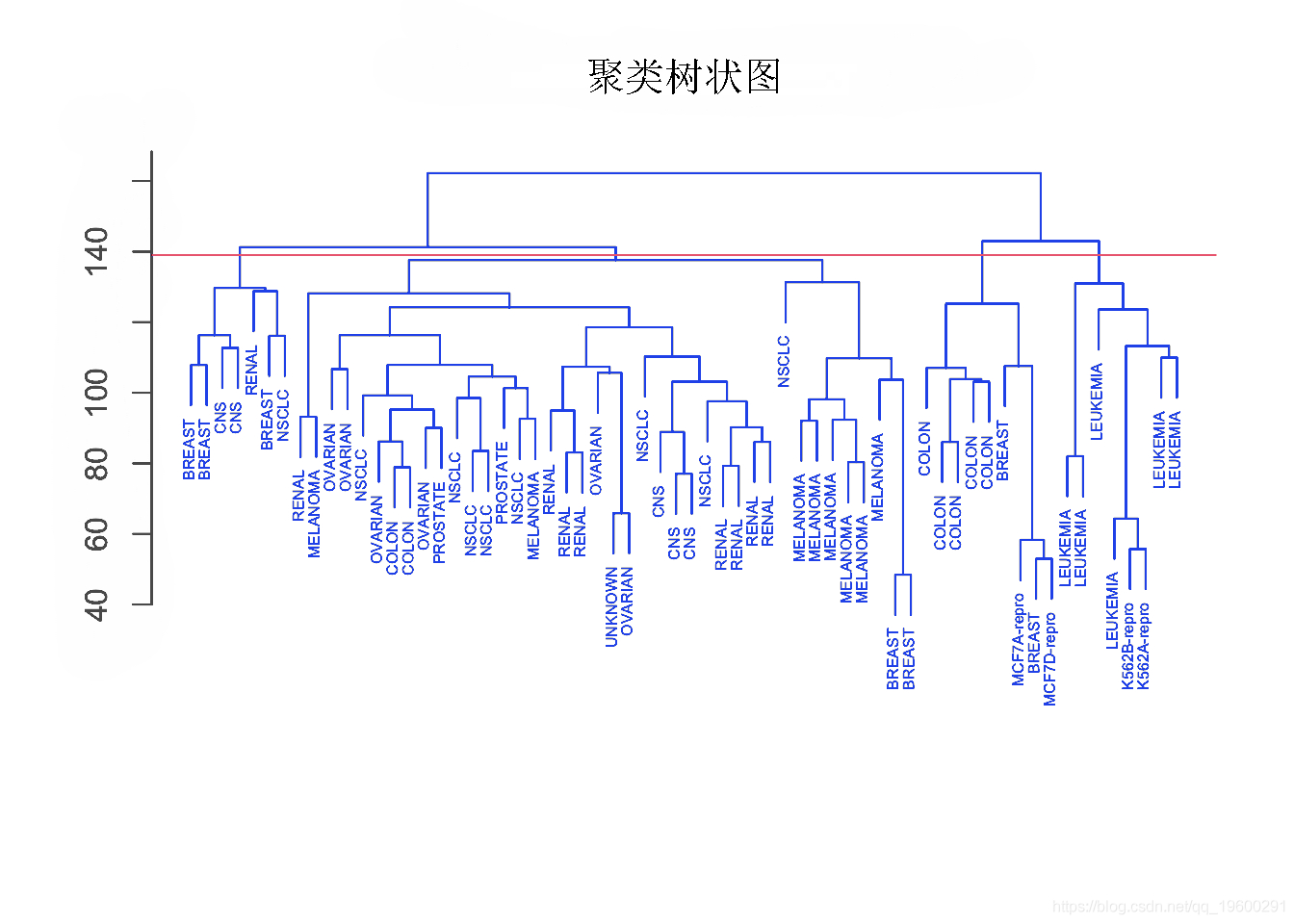
参数 h=139 在高度 139 处绘制一条水平线。这是 4 个不同聚类的划分结果。
 
out
 

 
kout=kmea
table
 

我们看到,获得层次聚类和 K-means 聚类的四个聚类产生了不同的结果。K-means 聚类中的簇 2 与层次聚类中的簇 3 相同。另一方面,其他集群不同。
结论
层次聚类在 NCI60 数据集中能比 K-means聚类得到更好的聚类。

Original: https://blog.csdn.net/qq_19600291/article/details/122735124
Author: 拓端研究室
Title: 拓端tecdat|R语言K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/550360/
转载文章受原作者版权保护。转载请注明原作者出处!