

数据挖掘重点
- 1、第一章
- 2、第二章
- 3、第三章
* - 3.1ID3算法
- 3.2 C4.5算法
- 3.3 CART算法 ==(基尼系数)==
- 3.4 贝叶斯 定理
- 3.6 K-最近邻(KNN)
- 4、第四章 聚类分析
* - 4.1 K-means算法
- 4.2、==DBSCAN==:==(必考)==
- 4.3一趟聚类算法
- 5、第五章 关联规则
* - 5.1 支持度与置信度
- 5.2 用Aprior算法寻找强关联规则和频繁项集
- 5.3 项集个数计算
- 6、第六章 离群点挖掘
* - 6.1、异常点:
- 6.2、K-最近邻算法:
1、第一章
1、区分分类还是聚类:
聚类:以图搜图、谷歌搜图
分类:垃圾邮件检测;扑克牌按花色、大小分组;
判断核心关键:数据集有没有标签,有是分类,没有是聚类。
2、什么是数据挖掘:
数据挖掘可以从技术和商业两个层面上来定义,从 技术层面上看,数据挖掘是从大量应用数据中挖取潜在有用的信息;从商业层面上看,数据挖掘是一种商业信息处理技术,用于提取辅助商业决策的关键性数据
3、数据挖掘所得到的信息具有的3个特点:
事先未知、有效和实用
4、数据挖掘是不是要把数据的特点展示出来,人们再利用特点来分析数据背后隐藏的规律?
(X) 不是把特点展现出来,而是用机器自动地挖掘数据背后隐藏的规律,来帮助我们、指导我们做出决策。
2、第二章
1、距离公式:
欧氏距离公式:
(最熟悉的就是两点之间的距离公式)


本质:分量差的平方和
曼哈顿距离:
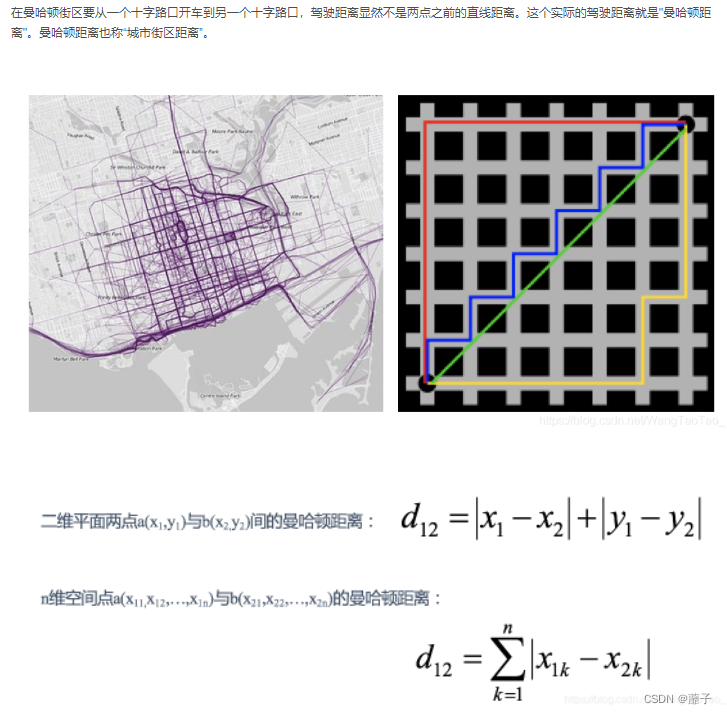
曼哈顿距离就是分量差的绝对值的和
2、相似系数、相关系数:
1、相关系数:

相关系数是被标准化的余弦相似度
!!注意均值!!
补充: 余弦相似度:

2、相似系数:

; 3、第三章
3.1ID3算法
1、算根节点是谁?
信息增益最大的为根节点
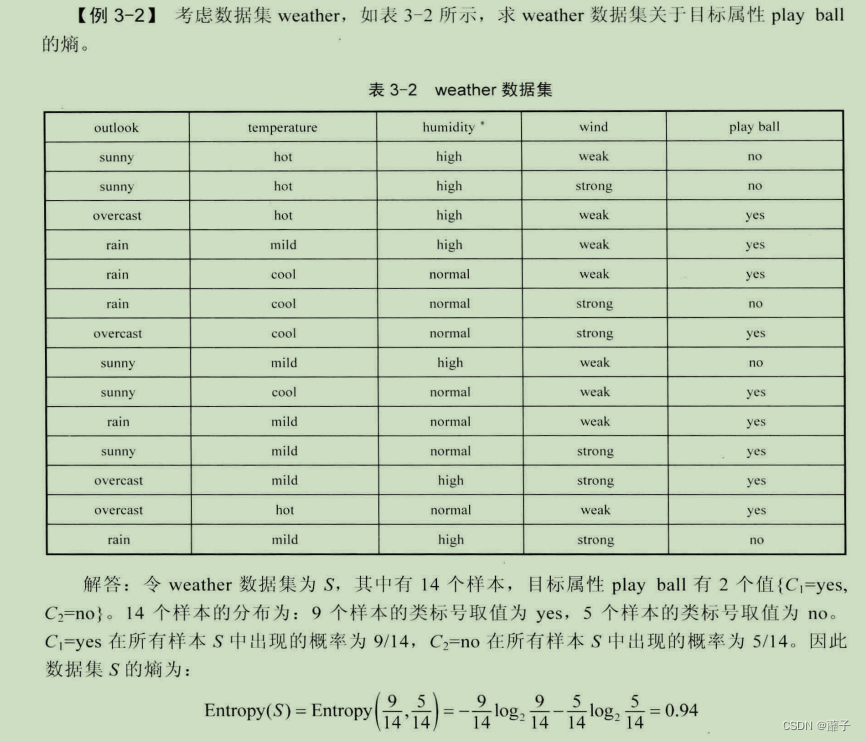
2、掌握熵、信息增益、按照信息增益划分结点(表3-2例题)?
答:
比如表3-2中就选play ball属性作为根节点
Q2:
2.1 几个重要概念
信息熵(也叫熵)

例题:
信息增益

例子:

3、ID3 分类算法使用信息增益作为属性的选择标准。
2、优缺点:

; 3.2 C4.5算法
1、C4.5算法的 划分标准是信息增益率,
2、信息增益率=信息增益/分裂信息

例子:


3、增益信息和分裂信息的关系,是不是一个大另一个也大,一个小另一个也小?为什么满足这样的关系?
不是。信息增益变大,分裂信息就会变小,反之亦然。
信息增益是拿之前的熵减去之后的熵,所以肯定是个正数。这个正数越大越好,因为越大代表这次分裂使系统的混乱程度降低的越多。
分裂信息:类别本身的熵,越大代表系统越混乱。
4、优缺点:

3.3 CART算法 (基尼系数)
Gini系数

而按照t属性划分后的Gini系数为:
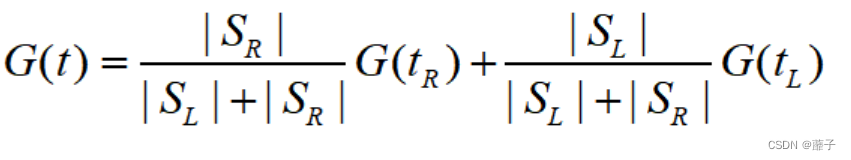
例子请点击右方超链接:Gini系数的计算
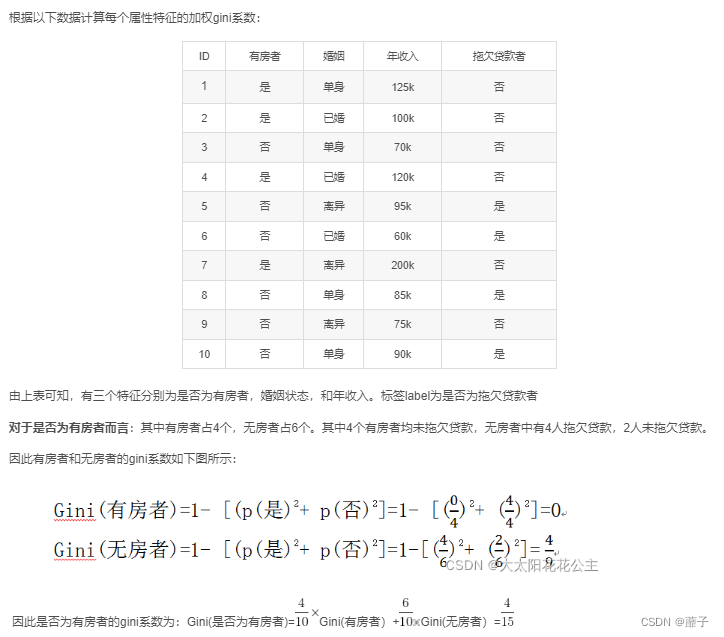
Gini系数增益:
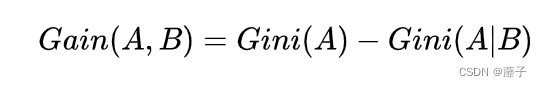
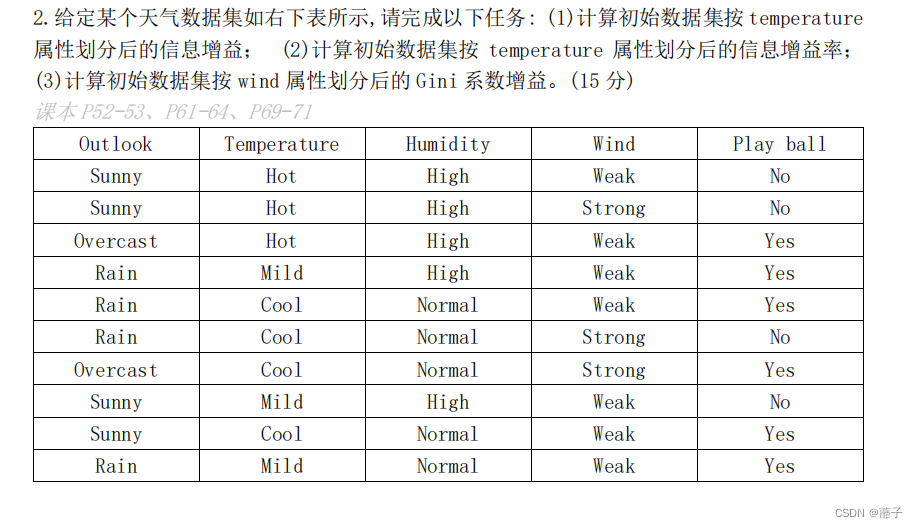
往年真题:
第(3)问:

; 3.4 贝叶斯 定理
注意:贝叶斯定理不能算分母。
往年真题(2016-2017学年):
请写出贝叶斯公式,请给出朴素贝叶斯分类方法的步骤。(7分)

(2)朴素贝叶斯步骤

3.6 K-最近邻(KNN)
用于分类的优缺点:

; 4、第四章 聚类分析
4.1 K-means算法
1、流程分析:

2、优缺点:
优点: 描述容易、实现简单、快速
缺点:
(1)簇的个数 k 难以确定;
(2)聚类结果对初始簇中心的选择较敏感;
(3)对噪音和异常数据敏感;
(4)不能用于发现非凸形状的簇,或具有各种不同大小的簇。
; 4.2、DBSCAN:(必考)
1、流程

2、DBSACN能否区分核心点、噪声点、边界点?(√)
3、DBSACN能判断哪些情况?
DBSCAN能判断任意形状的簇。
4、DBSCAN能否对噪声点和离群点进行区分?


P129例题( 要做题)
注意 DBS代表什么、核心点阈值用哪几个字母表示?
DBS:Density-Based Spatial(基于密度的聚类算法)
核心点阈值:MinPts
4.3一趟聚类算法
优点:
1、能处理大规模数据,超过系统内存的数据,不能一次性读取,也能对其进行处理
2、高效,参数选择简单,对噪声不敏感
缺点:
1、对输入顺序敏感
2、不能用于发现非凸形状的簇,或具有各种不同大小的簇
5、第五章 关联规则
5.1 支持度与置信度


小题:
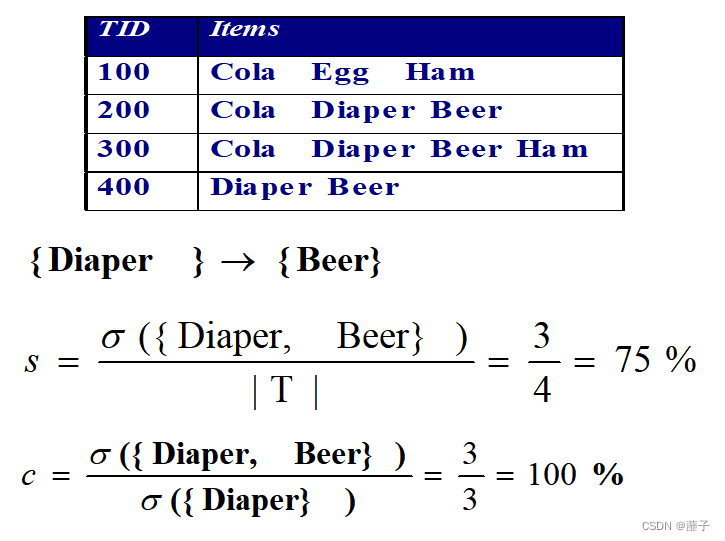
1、支持度关于关联规则的前件和后件是对称的,置信度不对称
2、支持度和置信度的计算
; 5.2 用Aprior算法寻找强关联规则和频繁项集
强关联规则的定义:
大于最小支持度阈值和最小置信度阈值的关联规则称为强关联规则。
Aprior算法寻找频繁项集:

例子:求下列表的频繁三项集。(P156)
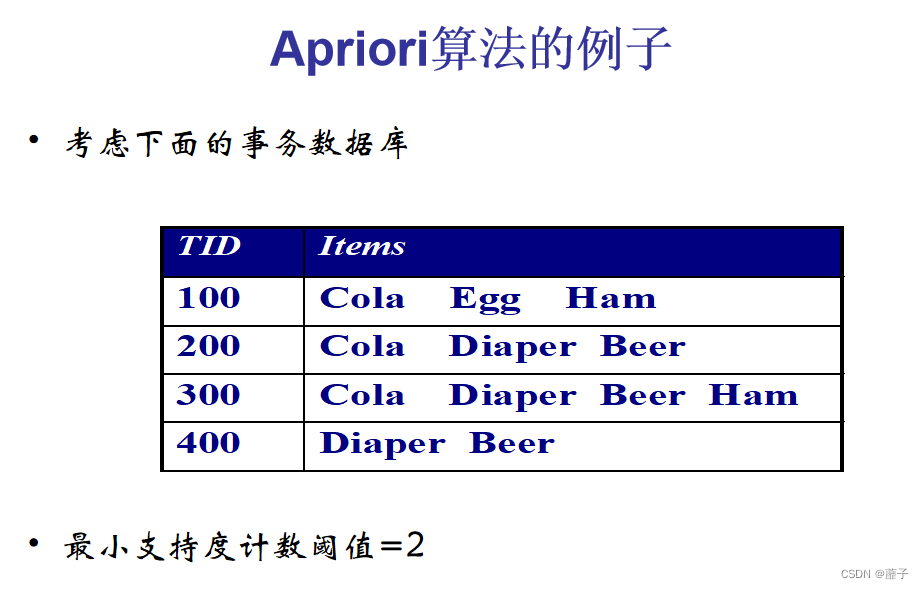

往年真题:
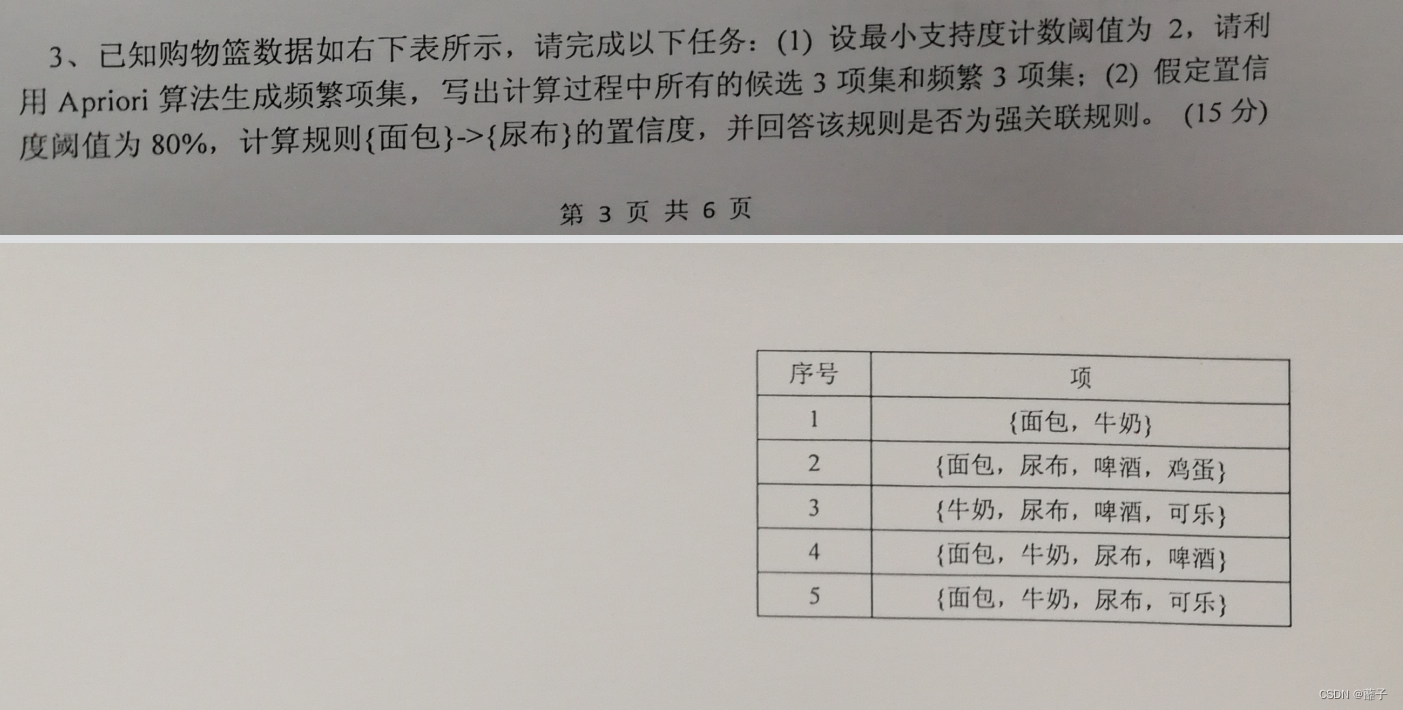
5.3 项集个数计算
1、给定k个项,一共有2k-1 个项集。
2、频繁k项集有2k-2个调候选关联规则(除去L->ᴓ和ᴓ->L)
6、第六章 离群点挖掘
6.1、异常点:
1、合理的离群点允许存在。
离群点的定义:
离群点是在数据集中偏离大部分数据的数据,使人怀疑这些数据的偏离并非由随机因素产生,而是产生于完全不同的机制。
合理离群点的产生原因:

2、异常点与噪声点的生成机制不同:
噪声点是被篡改的点。
; 6.2、K-最近邻算法:
1、OF1离群因子的计算

可能存在有k个点距离相同的情况。
比如前k=2,但是最近的3个点的距离是3,8,8
则OF1=(3+8+8)/ 3
例题:
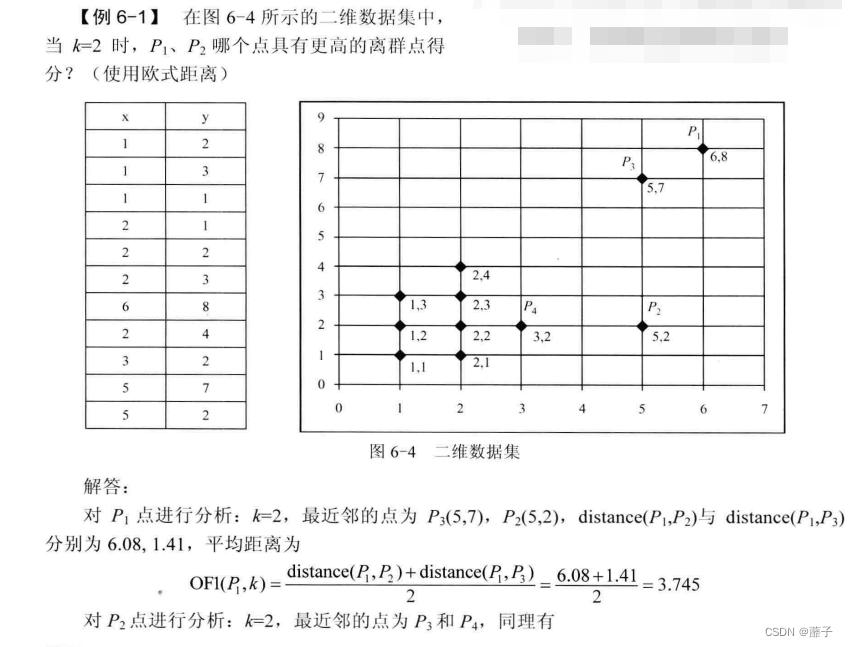

2、OF3计算点到簇的距离

有质心就用,没有就自己算。
例题:

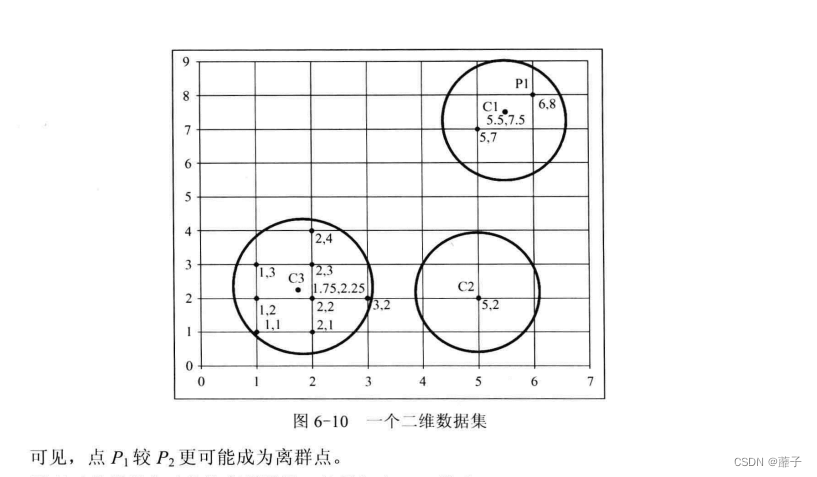
3、判断哪个点更有可能是离群点
OF1越大,越有可能是离群点
OF3越大,越有可能是离群点
Original: https://blog.csdn.net/m0_51290571/article/details/125220492
Author: 蘼子
Title: 【期末划重点】数据挖掘
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549902/
转载文章受原作者版权保护。转载请注明原作者出处!