

这是机器学习课程的一个课设,具体的课设要求如下:
1.熟悉机器学习的完整流程,包括:问题建模,获取数据,特征工程,模型训练,模型调优,线上运行;或者分为三大块:数据准备与预处理,模型选择与训练,模型验证与参数调优。
2.绘制机器学习算法分类归纳思维导图,按照有监督学习、无监督学习、半监督学习和强化学习进行绘制,对学过的算法进行归纳总结。
3.自行选择学习任务,按照机器学习流程,分别设计分类、预测、聚类系统,每个系统务必选择不同的算法进行训练,采用多种方法进行模型验证与参数调优,选择适合的多个指标对模型进行评估,采用可视化方法对结果进行分析。
(1)分类算法:
k-近邻算法、贝叶斯分类器、决策树分类、BP神经网络、AdaBoost、GBDT、随机森林、逻辑回归等
(2)预测:贝叶斯网络、马尔科夫模型、线性回归、XGBoost、岭回归、多项式回归、决策树回归、深度神经网络预测
(3)聚类:K-means、层次聚类BIRCH、密度聚类DBSCAN算法、高斯混合聚类GMM、密度聚类的OPTICS算法、基于网格的聚类(STING、CLIQUE)、Mean Shift聚类算法
其中:蓝色标注的算法要求必须在问题中使用,红色标注的为选用(至少选一种,多选加分),黑色的可不用,如用则有加分
4.要求
(1)所选用算法可直接调用Python中的相关库函数实现,但要对其源码进行分析,厘清算法结构及各部分功能。也可自行编写相关算法,并与库函数进行对比实验
(2)数据集的选择要分为小数据集、中等规模数据集、大规模数据集,数据集类型应有结构化、半结构化以及非结构化数据集。
(3)同一类算法中要实现各个算法在不同数据集、不同指标的比较
(4)算法设计中要有较详细的注释说明,对每个模块给出详细解释、功能注释等
首先需要下载相关的python库:sklearn库 (这是最主要的库,里面包含了机器学习所涉及的很多算法)、matplotlib库(主要是用来画图,实现可视化)、numpy库、pandas库等等
1.测试集、训练集的划分:
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
def readData(FileName,usecols1,usecols2):
#读取数据
data=pd.read_excel(FileName,usecols=usecols1)#特征数据
kinds=pd.read_excel(FileName,usecols=usecols2) #类别数据
#数据类型处理
data=np.array(data)
kinds=np.array(kinds)
k=[ ]
for i in kinds:
k.extend(i)
kinds=np.array(k)
return data,kinds
data,kinds=readData("iris.xlsx",[1,2,3,4],[6])#这里的鸢尾花数据是以excel表存储的,也可以直接调用sklearn库里的数据集
train_x,test_x,train_y, test_y = train_test_split(data,kinds, test_size=0.3)#划分训练集和测试集
2.分类算法:
首先构建分类算法模型,之后用训练集去训练模型,然后用测试集去测试训练好的模型的性能,以k-近邻算法为例:
from sklearn import neighbors
#构建KNN模型
n_neighborts=15
weights="distance"
knn_clf =neighbors.KNeighborsClassifier(n_neighborts , weights=weights)
#训练模型
knn_clf.fit(train_x,train_y)
#测试模型
knn_pred=knn_clf.predict(test_x)
#print(knn_pre)
评估模型
print("模型精度:{:.2f}".format(np.mean(knn_pred==test_y)))
print("模型精度:{:.2f}".format(knn_clf.score(test_x,test_y)))
当然还可以使用其他的分类算法:
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier, GradientBoostingClassifier #AdaBoost算法,随机森林,GBDT算法
from sklearn.linear_model import LogisticRegression #逻辑回归算法
from sklearn.naive_bayes import GaussianNB #贝叶斯分类器
from sklearn import tree #决策树
#不同分类模型的创建
gnb_clf=GaussianNB()
dt_clf=tree.DecisionTreeClassifier( )
adbt_clf=AdaBoostClassifier(tree.DecisionTreeClassifier(max_depth=2,\
min_samples_split=20,min_samples_leaf=5),\
algorithm="SAMME", n_estimators=10, learning_rate=0.8)
gbdt_clf=GradientBoostingClassifier(random_state=2020)
rfc_clf=RandomForestClassifier(n_estimators=10,n_jobs=2)
lr_clf=LogisticRegression(penalty='l2',solver='newton-cg',multi_class='multinomial')
上述模型的评估方法比较单一,可以使用以下评估指标:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
#预测结果一律用y_pred表示
print(round(accuracy_score(test_y, y_pred), 3))#精确率
print(round(precision_score(test_y, y_pred, average="macro"), 3))#召回率
print(round(recall_score(test_y, y_pred, average="micro"), 3))#准确率
print(round(f1_score(test_y, y_pred, average="weighted"), 3))#F1值
最后可以对结果进行可视化
import matplotlib.pyplot as plt
from sklearn import metrics
confusion=[ ]
confusion=metrics.confusion_matrix(test_y,knn_pred)#混淆矩阵
#显示预测结果
def show_pred(st,y_pred):#st表示所用算法,y_pred表示预测结果
fig=plt.figure()
plt.title(st)
plt.scatter(test_x[:, 0], test_x[:, 1], c=y_pred)
fig.tight_layout()
plt.savefig("image/"+st+".png", dpi=55)#存储图像文件
#ROC曲线
def ROC_auc(st,y_pred):
fpr, tpr, thresholds = roc_curve(test_y, y_pred, pos_label=2)#计算真正类率和假正类率
roc_auc = metrics.auc(fpr,tpr)
fig=plt.figure()
plt.plot( fpr,tpr, 'b',label='AUC = %0.2f'% roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.title(st+'--ROC')
plt.legend(loc="lower right")
fig.tight_layout()
plt.savefig("roc_auc/"+st+".png", dpi=55)
#混淆矩阵可视化
def plot_confusion_matrix(confusion,st):#confusion表示混淆矩阵
fig=plt.figure()
plt.title(st)
plt.imshow(confusion, cmap=plt.cm.Blues)
plt.xlabel('Estimate')
plt.ylabel('True value')
fig.tight_layout()
plt.savefig("mat/"+st+".png", dpi=55)
show_pred("KNN",knn_pred)
plot_confusion_matrix(metrics,"KNN")
ROC_auc("KNN",knn_pred)
在以上代码中,可视化的结果都被保存在了文件夹里,如果想要直接显示直接使用plt.show()就可以了,以下就是对上述结果可视化结果的截图
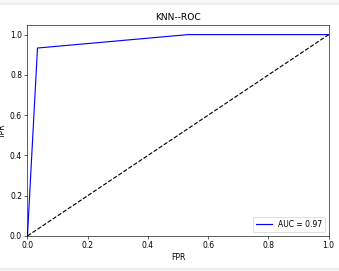

ROC曲线
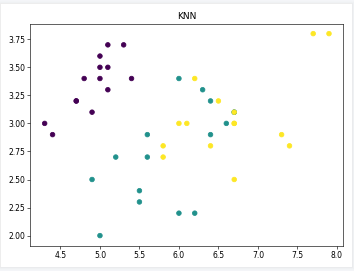
预测结果可视化
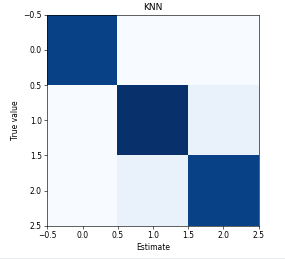
混淆矩阵
3.聚类算法:
各种聚类算法代码:
from sklearn.cluster import KMeans, Birch, DBSCAN, OPTICS, MeanShift
from sklearn.mixture import GaussianMixture
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.metrics import homogeneity_completeness_v_measure
#K-means聚类
kmeans_clt=KMeans(n_clusters=self.k,random_state=1)
kmeans_pred=kmeans_clt.fit_predict(data)
#层次聚类BIRCH
bir_clt = Birch(n_clusters=k)#k表示聚类次数
bir_pred = bir_clt.fit_predict(data)
密度聚类DBSCAN算法
dbs_clt =DBSCAN( eps=0.6,min_samples=2).fit(data)
dbs_pred = dbs_clt.fit_predict(data)
高斯混合聚类
gmm_clf = GaussianMixture(n_components=self.k,n_init=3)
gmm_pred = gmm_clf.fit_predict(data)
密度聚类的OPTICS算法
opt_clf = OPTICS()
opt_pred = opt_clf.fit_predict(data)
Mean Shift聚类算法
ms_clf= MeanShift(bandwidth=0.6, bin_seeding=True)
ms_clf.fit(data)
ms_pred = ms_clf.fit_predict(data)
模型评估参数:
import numpy as np
from sklearn import metrics
from sklearn.metrics import accuracy_score
计算纯度
def purity_score(y_true, y_pred):
y_voted_labels = np.zeros(y_true.shape)
labels = np.unique(y_true)
ordered_labels = np.arange(labels.shape[0])
for k in range(labels.shape[0]):
y_true[y_true == labels[k]] = ordered_labels[k]
labels = np.unique(y_true)
bins = np.concatenate((labels, [np.max(labels) + 1]), axis=0)
for cluster in np.unique(y_pred):
hist, _ = np.histogram(y_true[y_pred == cluster], bins=bins)
winner = np.argmax(hist)
y_voted_labels[y_pred == cluster] = winner
return accuracy_score(y_true, y_voted_labels)
hcv = homogeneity_completeness_v_measure(self.kinds, y_pred)
round(metrics.silhouette_score(kinds,y_perd))#轮廓系数
round(purity_score(kinds, y_pred), 3)
round(metrics.adjusted_rand_score(kinds, y_pred), 3) #调整兰德系数
round(sklearn.metrics.f1_score(kinds, y_pred, average='micro'), 3) #f-score
round(metrics.mutual_info_score(kinds, y_pred), 3) #互信息
round(hcv[0], 3) #同质性
round(hcv[1], 3) #完整性
round(hcv[2], 3) #调和平均
结果可视化代码:
#聚类结果展示
def show_pred(data st, y_pred):
plt.title(st)
plt.scatter(data[:, 0], data[:, 1], c=y_pred)
plt.savefig("image/"+st+".png", dpi=55)
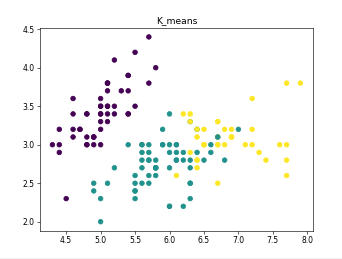
4.预测算法:
各种预测算法代码:
import xgboost
import sklearn.pipeline as pl
import sklearn.preprocessing as sp
import sklearn.linear_model as lm
from hmmlearn.hmm import GaussianHMM
from sklearn import linear_model
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import MultinomialNB
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression,BayesianRidge
from sklearn.tree import DecisionTreeRegressor
贝叶斯网络
byes_fct = MultinomialNB()
byes_fct.fit(train_x, train_y)
byes_pred = byes_fct.predict(test_x)
马尔科夫模型
mar_fct= GaussianHMM(n_components=k,tol=0.01, covariance_type='diag', n_iter=1000)
#k表示类别数目
mar_fct.fit(train_x)
mar_pred = mar_fct.predict(test_x)
多项式回归
数据标准化
ss = StandardScaler()
train_x = ss.fit_transform(train_x) # 训练并转换
test_x = ss.transform(test_x)
poly_fct = PolynomialFeatures(degree=k)
quead_x=poly_fct.fit_transform(train_x)
test_x=poly_fct.fit_transform(test_x)
lr = LinearRegression()
lr.fit(quead_x,train_y)
poly_pred =lr.predict(test_x)
决策树回归
dt_fct = DecisionTreeRegressor(max_depth=5)
dt_fct.fit(train_x, train_y)
dt_pred = dt_fct.predict(test_x)
线性回归
数据标准化
ss = StandardScaler()
train_x = ss.fit_transform(train_x) # 训练并转换
test_x = ss.transform(test_x)
lr_fct = LinearRegression()
lr_fct.fit(train_x, train_y)
lr_pred = lr_fct.predict(test_x)
岭回归
ridge_fct = linear_model.RidgeCV()
ridge_fct.fit(train_x, train_y)
ridge_pred = ridge_fct.predict(test_x)
XGBoost
bst_fct = xgboost.XGBClassifier(early_stopping_rounds=50,max_depth=10)
bst_fct.fit(train_x, train_y)
bst_pred = bst_fct.predict(test_x)
模型评估参数:
import numpy as np
import pandas as pd
from sklearn import metrics
贝叶斯,线性
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
def smape(y_true, y_pred):
return 2.0 * np.mean(np.abs(y_pred - y_true) / (np.abs(y_pred) + np.abs(y_true))) * 100
round(metrics.mean_squared_error(test_y, y_pred), 3)
round(np.sqrt(metrics.mean_squared_error(test_y, y_pred)), 3)
round(metrics.mean_absolute_error(test_y, y_pred), 3)
round(mape(test_y, y_pred), 3)
round(smape(test_y, y_pred), 3)
结果可视化代码:
import numpy as np
import pandas as pd
def show_pred(k,test_x,test_y,st,y_pred):
fig=plt.figure()
plt.title(st)
plt.plot(test_x[:,0], test_y, 'ro', label='test data')
plt.plot(test_x[:,0], y_pred, 'bo', label='predict data')
#plt.ylim(0, k+1)
plt.legend()
fig.tight_layout()
plt.savefig("image/"+st+".png", dpi=55)
def proportion(test_y,st,y_pred): #比例展示
fig=plt.figure()
plt.title(st)
tp=0
fn=0
for i in range(len(test_y)):
if(int(y_pred[i]+0.5)==test_y[i] ):
tp+=1
else:
fn+=1
fn=fn/len(y_pred)
tp=tp/len(y_pred)
x=["test data = predict data","test data!= predict data"]
y=[tp,fn]
plt.bar(x,y,color="steelblue",alpha=0.5)
plt.plot(x,y,"r",marker="*",ms=10,label='a')
plt.ylabel('Rate')
fig.tight_layout()
plt.savefig("mat/"+st+".png", dpi=55)
有了这些主要的代码之后就可以多使用几个数据集,自己设计界面,做成一个数据分析的系统
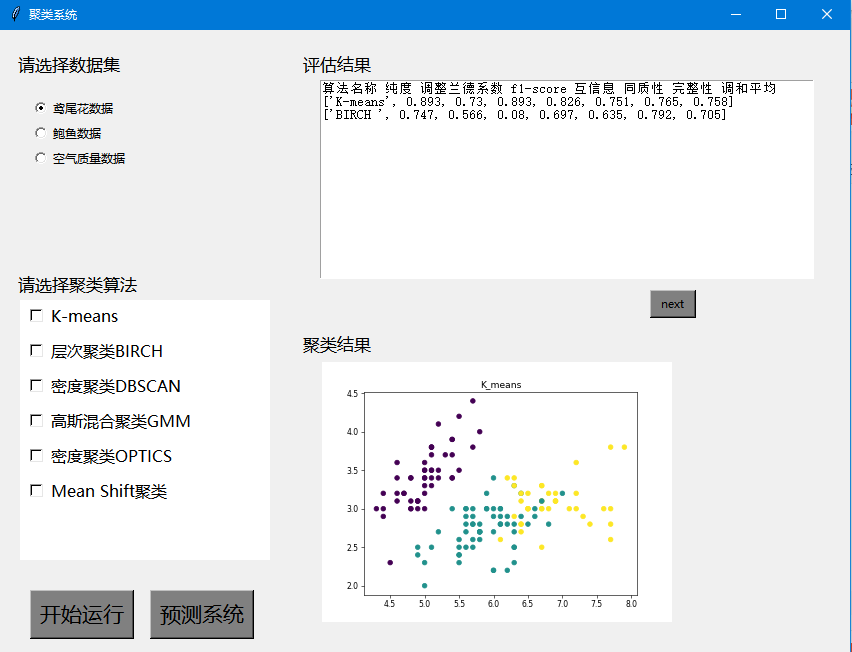
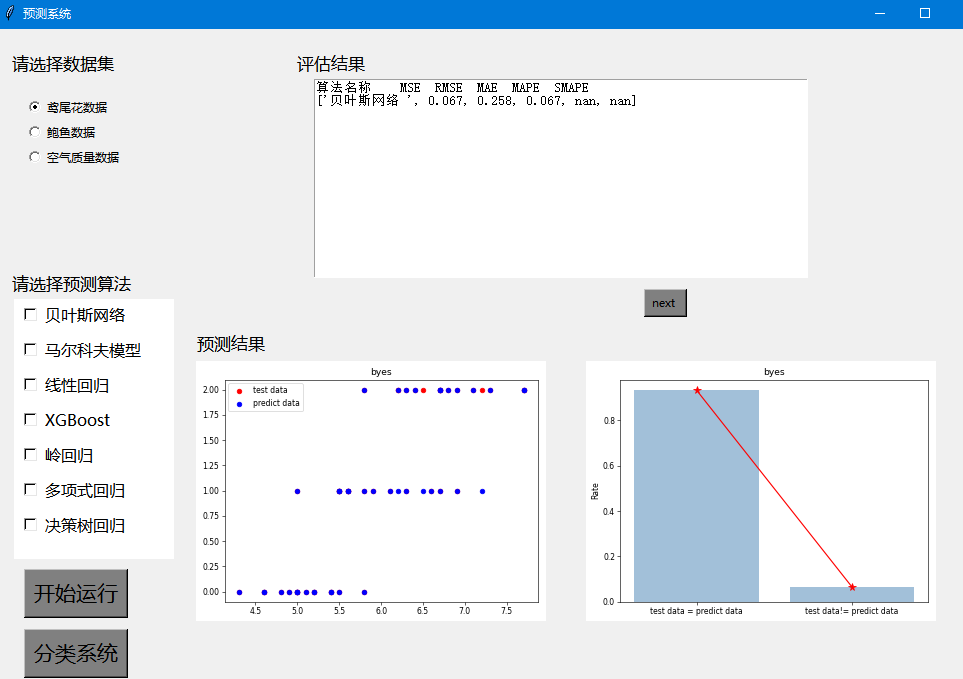
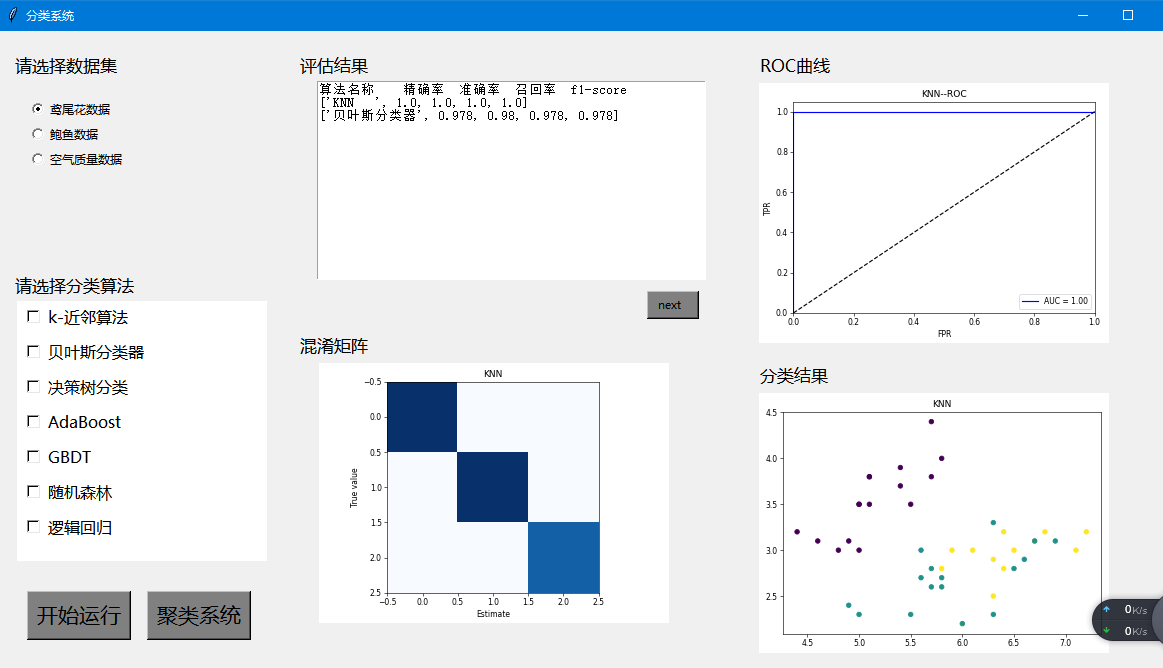
以上就是我自己做的系统截图,具体代码可以参考以下内容:
https://download.csdn.net/download/clown0004/85636871?spm=1001.2014.3001.5501
Original: https://blog.csdn.net/clown0004/article/details/125354575
Author: clown0004
Title: 机器学习-分类聚类预测系统
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549792/
转载文章受原作者版权保护。转载请注明原作者出处!