

聚类算法是在没有给定划分类别的情况下,根据数据相似度进行样本分组的一种方法,是一种无监督学习方法。聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度将他们划分为若干组,划分的原则是组内样本最小而组间距离最大化。
常用的聚类方法有:


常见的聚类分析算法有:

这里主要介绍一下最常用的K-Means聚类算法
一、K-Means聚类算法简介
K-Means算法是典型的基于距离的非层次聚类算法,在最小化误差函数的基础上将数据划分为预定的类数k,采用距离作为相似性评价指标,即认为两个对象的距离越近,其相似度就越大。
1.算法过程
(1)从n个样本数据中随机选取k个对象作为初始聚类中心;
(2)分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中;
(3)所欲对象分配完后,重新计算k个聚类的中心;
(4)与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转至步骤(2),否则转至步骤(5);
(5)当质心不发生变化时,停止并输出聚类结果。
2.聚类算法的优缺点
2.1 优点
- 容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
- 处理大数据集的时候,该算法可以保证较好的伸缩性;
- 当簇近似高斯分布的时候,效果非常不错;
- 算法复杂度低。
2.2 缺点
- K 值需要人为设定,不同 K 值得到的结果不一样;
- 对初始的簇中心敏感,不同选取方式会得到不同结果;
- 对异常值敏感;
- 样本只能归为一类,不适合多分类任务;
- 不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。
聚类的结果可能依赖于初始聚类中心的随机选择,使得结果严重偏离全局最优分类。因此,在实践中为了得到较好的结果,通常选择不同的初始聚类中心,多次运行k-means算法。在计算k个聚类中心的时候,对于连续数据,聚类中心取该簇的均值但是当样本的某些属性是分类变量时,均值可能无定义,此时可以使用k-众数方法。
3.相似性的度量
对于连续属性,要先对各属性值进行零-均值规范,再进行距离的计算。度量样本之间的相似性最常用的是欧几里得距离、曼哈顿距离和闵可夫斯基距离。

4.目标函数
使用误差平方和SSE作为度量聚类质量的目标函数。
簇
的聚类中心的计算公式
其中 k表示聚类簇的个数,
表示第i个簇,x代表样本,表示簇的聚类中心,n表示数据集中样本的个数,表示第i个簇中样本的个数。
二、用Python实现K-Means聚类算法
1、导入数据并进行标准化
import pandas as pd
inputfile = './Python数据分析与挖掘实战(第2版)/chapter5/demo/data/consumption_data.xls'
data = pd.read_excel(inputfile,index_col = 'Id')
data
数据如下:
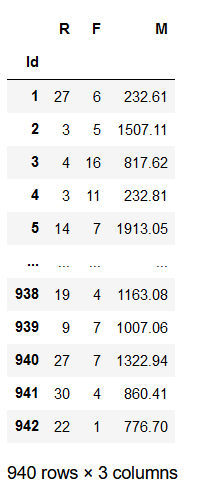
该数据集表示餐饮客户的消费行为特征
k = 3 #聚类的类别
iteration = 500 #聚类最大循环次数
data_zs = 1.0*(data-data.mean())/data.std() #数据标准化
data_zs
2.构建kmeans模型
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration, random_state = 1234) #分类为k,并发数为4
model.fit(data_zs)
<strong>n_clusters: </strong>簇的个数,即你想聚成几类
<strong>init:</strong> 初始簇中心的获取方法
<strong>n_init:</strong> 获取初始簇中心的更迭次数,为了弥补初始质心的影响,算法默认会初始 10 个质心,实现算法,然后返回最好的结果。
<strong>max_iter:</strong> 最大迭代次数(因为kmeans算法的实现需要迭代)
<strong>tol:</strong> 容忍度,即kmeans运行准则收敛的条件
<strong>precompute_distances:</strong>是否需要提前计算距离,这个参数会在空间和时间之间做权衡,如果是 True 会把整个距离矩阵都放到内存中,auto 会默认在数据样本大于featurs * samples 的数量大于 12e6 的时候 False , False 时核心实现的方法是利用Cpython 来实现的
<strong>verbose:</strong> 冗长模式(不太懂是啥意思,反正一般不去改默认值)
<strong>random_state:</strong> 随机生成簇中心的状态条件。
<strong>copy_x: </strong>对是否修改数据的一个标记,如果 True ,即复制了就不会修改数据。 bool 在scikit - learn 很多接口中都会有这个参数的,就是是否对输入数据继续copy 操作,以便不修改用户的输入数据。这个要理解Python 的内存机制才会比较清楚。
<strong>n_jobs:</strong> 并行设置
<strong>algorithm:</strong> kmeans的实现算法,有: 'auto' , ‘full ', ‘elkan' , 其中 ‘full'表示用EM方式实现
虽然有很多参数,但是都已经给出了默认值。所以我们一般不需要去传入这些参数,参数的。可以根据实际需要来调用。
参考:https://www.jb51.net/article/129821.htm
3.结果展示
#简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各类别数目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
r = pd.concat([r2,r1],axis =1) #得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + ['类别数目'] #重命名表头
print(r)
得到结果如下,显示了每个特征在每个簇下的中心位置。

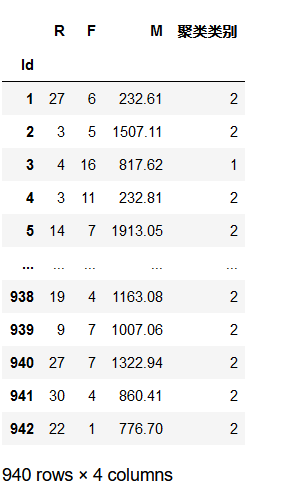
详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_,index =data.index)],axis =1)
r.columns = list(data.columns) + ['聚类类别']
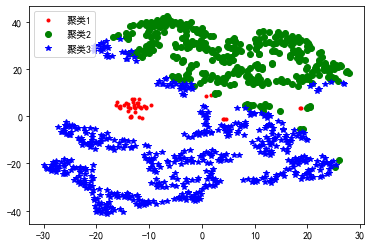
我们还可以用聚类结果可视化工具——TSNE将数据进行降维并在二维或者三维空间展示出来。
使用TSNE进行数据降维并展示聚类结果
from sklearn.manifold import TSNE
tsne = TSNE()
tsne.fit_transform(data_zs) # 进行数据降维
tsne.embedding_可以获得降维后的数据
print('tsne.embedding_: \n', tsne.embedding_)
tsn = pd.DataFrame(tsne.embedding_, index=data.index) # 转换数据格式
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
不同类别用不同颜色和样式绘图
color_style = ['r.', 'go', 'b*']
for i in range(k):
d = tsn[r[u'聚类类别'] == i]
# dataframe格式的数据经过切片之后可以通过d[i]来得到第i列数据
plt.plot(d[0], d[1], color_style[i], label='聚类' + str(i+1))
plt.legend()
plt.show()
结果如下:

Original: https://blog.csdn.net/weixin_41168304/article/details/122747347
Author: 阿丢是丢心心
Title: 【Python数据分析】数据挖掘建模——聚类分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549756/
转载文章受原作者版权保护。转载请注明原作者出处!