

Grid-based methods:其原理是将数据空间划分为网格单元,将数据对象映射到网格单元中,并计算每个单元的密度。根据预设阈值来判断每个网格单元是不是高密度单元,由邻近的稠密单元组成”类”。
1.将数据空间划分为网格单元
2.依照设置的阈值,判定网格单元是否稠密
3.合并相邻稠密的网格单元为一类
优点:执行效率高,因为其速度与数据对象的个数无关,而只依赖于数据空间中每个维上单元的个数。
缺点:对参数敏感、无法处理不规则分布的数据、维数灾难等。

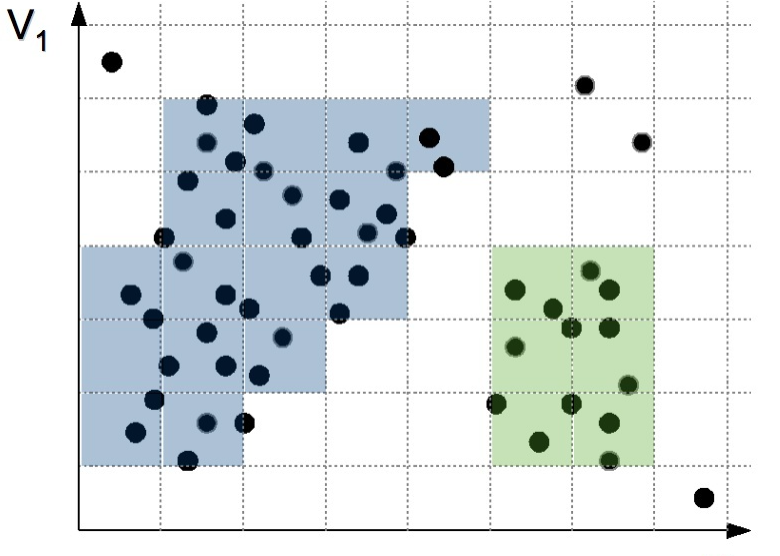
鉴于基于划分和层次聚类方法都无法发现非凸面形状的簇,真正能有效发现任意形状簇的算法是基于密度的算法,但基于密度的算法一般时间复杂度较高,1996年到2000年间,研究数据挖掘的学者们提出了大量基于网格的聚类算法,网格方法可以有效减少算法的计算复杂度,且同样对密度参数敏感。
典型算法:
STING(Statistical Information Grid ):基于网格多分辨率,将空间划分为方形单元,对应不同分辨率
CLIQUE(Clustering In Quest):结合网格和密度聚类的思想,子空间聚类处理大规模高维度数据
WaveCluster:用小波分析使簇的边界变得更加清晰
补充:Model-based methods:主要是指基于概率模型的方法和基于神经网络模型的方法,尤其以基于概率模型的方法居多。这里的概率模型主要指概率生成模型(generative Model),同一”类”的数据属于同一种概率分布。这中方法的优点就是对”类”的划分不那么坚硬,而是以概率形式表现,每一类的特征也可以用参数来表达;但缺点就是 执行效率不高,特别是分布数量很多并且数据量很少的时候。其中最典型、也最常用的方法就是高斯混合模型(GMM,Gaussian Mixture Models)。基于神经网络模型的方法主要就是指SOM(Self Organized Maps)了,
Original: https://blog.csdn.net/m0_65392155/article/details/123017914
Author: corina_qin
Title: 机器学习 – 聚类 基于网格的聚类算法(学习笔记)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549744/
转载文章受原作者版权保护。转载请注明原作者出处!