

聚类数k的确定及聚类方法的python实现[文末]
- 1.引入
- 2.聚类的数目c l u s t e r s = k clusters = k c l u s t e r s =k 的确定
* - 2.1肘部法则(Elbow Method)
- 2.2间隔统计量(Gap Statistic)
- 2.3轮廓系数(Silhouette Coefficient)
- 2.4 Canopy算法
- 3.聚类方法
* - 3.1 K-means聚类
- 3.2 K-means++聚类
- 3.3 高斯混合聚类
– - 3.4 密度聚类(DBSCAN)
– - 3.5 层次聚类(AGNES)
– - 4. 终极武器
* - 4.1 python代码
1.引入
针对不用的方法用不同性质的数据集,这里给出s k l e a r n sklearn s k l e a r n文档中的一幅聚类效果图。相关文档请点击。后文是结合西瓜书以及相关文献整理所得。


; 2.聚类的数目 c l u s t e r s = k clusters = k c l u s t e r s =k 的确定
由于聚类分析是属于 无监督学习范畴,我们不知道原始数据应该分为几类较为准确(或更符合常理)。以下几种方法推荐:
2.1肘部法则(Elbow Method)
随着分类数目k k k的增加,所有类中数据x i x_i x i 与类中心u j u_j u j 的距离和会减小,这是显然的,减小趋势会出现 先快后慢的特点,我们需要做的是选择减小率最大的k 0 k_0 k 0 作为分类数目。Elbow Method的计算公式如下
D k = ∑ j = 1 k ∑ i ∈ C j d i s t ( x i , u j ) , D_k = \sum_{j = 1}^{k}\sum_{i\in C_j} dist(x_i,u_j),D k =j =1 ∑k i ∈C j ∑d i s t (x i ,u j ),
这里d i s t ( ⋅ , ⋅ ) dist(\cdot,\cdot)d i s t (⋅,⋅)表示闵可夫斯基距离
d i s t ( x i , x j ) = ( ∑ u = 1 n ∣ x i u − x j u ∣ p ) 1 p dist(x_i,x_j) = ( \sum_{u = 1}^{n}|x_{iu}-x_{ju}|^p)^{\frac{1}{p}}d i s t (x i ,x j )=(u =1 ∑n ∣x i u −x j u ∣p )p 1
其中p = 2 p =2 p =2时为我们熟悉的欧式距离。如下图中当k = 3 k=3 k =3时为最佳类目。详细数据代码参见文末。

; 2.2间隔统计量(Gap Statistic)
根据肘部法则选择最合适的K值有时并不是那么清晰,因此斯坦福大学的Robert等教授提出了Gap Statistic方法。
Gap Statistic的定义为:
G a p n ( k ) = E n ∗ ( l o g ( D k ) ) − l o g ( D k ) Gap_n(k) = E_n^(log(D_k)) – log(D_k)G a p n (k )=E n ∗(l o g (D k ))−l o g (D k )
这里的E n ∗ ( l o g ( D k ) ) E_n^(log(D_k))E n ∗(l o g (D k ))是指l o g ( D k ) log(D_k)l o g (D k )的期望,通常通过蒙特卡洛(Monte Carlo)模拟产生,我们在样本里所在的矩形区域中(高维的话就是立方体区域)按照均匀分布随机地产生和原始样本数一样多的随机样本,并对这个随机样本做聚类,从而得到一个Dk。如此往复多次,通常20次,我们可以得到20个l o g D k log Dk l o g D k。对这20个数值求平均值,就得到了E n ∗ ( l o g D k ) E_n^(logDk)E n ∗(l o g D k )的近似值。最终可以计算Gap Statisitc。而Gap statistic取得最大值所对应的K就是最佳的k。Gap Statistic的基本思路是:
E n ∗ ( l o g D k ) = ( 1 / B ) ∑ b = 1 B log ( D k b ∗ ) E_n^(logDk) = (1/B)\sum_{b=1}^{B}\log(D^*_{kb})E n ∗(l o g D k )=(1 /B )b =1 ∑B lo g (D k b ∗)
其中B B B是采样次数,如下选择最优的k k k:
w = ( 1 / B ) ∑ b = 1 B log ( D k b ∗ ) s k = 1 + B B ( 1 / B ) ∑ b = 1 B log ( D k b ∗ − w ) 2 \begin{aligned} w & = (1/B)\sum_{b=1}^{B}\log(D^{kb})\ s_k & = \sqrt{\frac{1+B}{B}}\sqrt{(1/B)\sum{b=1}^{B}\log(D^{kb} -w)^2} \end{aligned}w s k =(1 /B )b =1 ∑B lo g (D k b ∗)=B 1 +B (1 /B )b =1 ∑B lo g (D k b ∗−w )2
选择满足
G a p k ≥ G a p k + 1 − s k + 1 Gap_k \geq Gap{k+1}-s_{k+1}G a p k ≥G a p k +1 −s k +1
的最小k k k作为最优的聚类数目。
从下图中显然可以看出当k k k取3的时候是最优的。

2.3轮廓系数(Silhouette Coefficient)
轮廓系数是以分类后的紧密程度去评判一个分类器的好坏:即离自己所在类较近,也要离其他类较远,这是显然的一个情况。由于这里需要涉及到另类,故至少分类为 两类。轮廓系数计算公式如下
S ( x i ) = b ( x i ) − a ( x i ) max { a ( x i ) , b ( x i ) } S(x_i) = \frac{b(x_i)-a(x_i)}{\max{a(x_i),b(x_i)}}S (x i )=max {a (x i ),b (x i )}b (x i )−a (x i )为样本数据x i ∈ X k 0 x_i \in \mathcal{X}{k_0}x i ∈X k 0 的单一样本轮廓系数,a ( x i ) a(x_i)a (x i )表示X k 0 \mathcal{X}{k_0}X k 0 所属类中与其他样本的平均距离,
a ( x i ) = 1 ∣ X k 0 ∣ − 1 ∑ j ≠ i , j ∈ X k 0 d i s t ( x i , x j ) a(x_i) = \frac{1}{|\mathcal{X}{k_0}|-1}\sum{j\neq i,j\in \mathcal{X}{k_0}}dist(x_i,x_j)a (x i )=∣X k 0 ∣−1 1 j =i ,j ∈X k 0 ∑d i s t (x i ,x j )
b ( x i ) b(x_i)b (x i )表示x i x_i x i 与其他类的样本平均值的 最小值,
b ( x i ) = min k t { 1 ∣ X k t ∣ ∑ j ∈ X k t d i s t ( x i , x j ) } b(x_i) =\min{k_t} {\frac{1}{|\mathcal{X}{k_t}|}\sum{j\in \mathcal{X}{k_t}}dist(x_i,x_j)}b (x i )=k t min {∣X k t ∣1 j ∈X k t ∑d i s t (x i ,x j )}
聚类总体的轮廓系数S S S为所有样本的轮廓系数的均值,
S = 1 n ∑ i = 1 n S ( x i ) , x i ∈ X S = \frac{1}{n}\sum{i=1}^{n} S(x_i),\quad x_i \in \mathcal{X}S =n 1 i =1 ∑n S (x i ),x i ∈X
如何通过轮廓系数去表达紧密程度呢,变换S ( x i ) S(x_i)S (x i )可得
S ( i ) = { 1 − a ( i ) b ( i ) a ( i ) < b ( i ) 0 a ( i ) = b ( i ) b ( i ) a ( i ) − 1 a ( i ) > b ( i ) S(i)=\left{\begin{array}{cc} 1-\frac{a(i)}{b(i)} & a(i)S (i )=⎩⎪⎨⎪⎧1 −b (i )a (i )0 a (i )b (i )−1 a (i )b (i )
当分类越好时,即a ( x i ) < b ( x i ) a(x_i)的时候,S ( x i ) S(x_i)S (x i )会向1靠,否则,S ( x i ) S(x_i)S (x i )会靠向-1。故S S S越靠向1越能说明分类较好。与2.2相同的数据得到的效果如下,
; 2.4 Canopy算法
之前的三种方法虽然可以选出相对最优的k k k值,但是这些方法都是属于”事后”判断的,而Canopy算法的作用就在于它是通过事先粗聚类的方式,为聚类算法确定初始聚类中心个数和聚类中心点。Canopy聚类最大的特点是 不需要事先指定k值(即clustering的个数),因此具有很大的实际应用价值。Canopy聚类虽然精度较低,但其在速度上有很大优势,因此可以使用Canopy聚类先对数据进行”粗”聚类,得到k k k值,以及大致的k k k个中心点,再使用K-Means进行进一步”细”聚类。具体 步骤如下
- 给定样本列表X = { x 1 , ⋯ , x n } \mathcal{X} = {x_1,\cdots,x_n}X ={x 1 ,⋯,x n }以及初始距离阈值为T 1 , T 2 T_1,\ T_2 T 1 ,T 2 ,且T 1 > T 2 T_1>T_2 T 1 >T 2 (T1、T2可自己定义);
- 从列表X \mathcal{X}X中任取一点P P P,计算P P P到所有聚簇中心点的距离(如果不存在聚簇中心,那么就把点P P P作为一个新的聚簇),并选出与聚类中心 最近的距离D ( P , x j ) D(P,x_j)D (P ,x j ) ;
- 如果距离D < T 1 D,表示该节点属于该聚簇,添加到该聚簇列表中。
- 如果距离D < T 2 D,表示该节点不仅仅属于该聚簇,还表示和当前聚簇中心点非常近,所以将P P P从列表X \mathcal{X}X中删除。
- 如果距离D > T 1 D>T_1 D >T 1 ,那么数据点P P P形成一个新的聚簇。
- 重复步骤2-5,直到列表X \mathcal{X}X为空时结束循环。
效果图如下,该方法要选择一个合适的T 1 , T 2 T_1,\ T_2 T 1 ,T 2 。个人觉得这就是导致Canopy算法之所以不如其他算法火的原因,虽然Canopy算法可以提供一个相对合适的k k k值,但这需要T 1 , T 2 T_1,\ T_2 T 1 ,T 2 取得相对 合适,这里你自己细品。
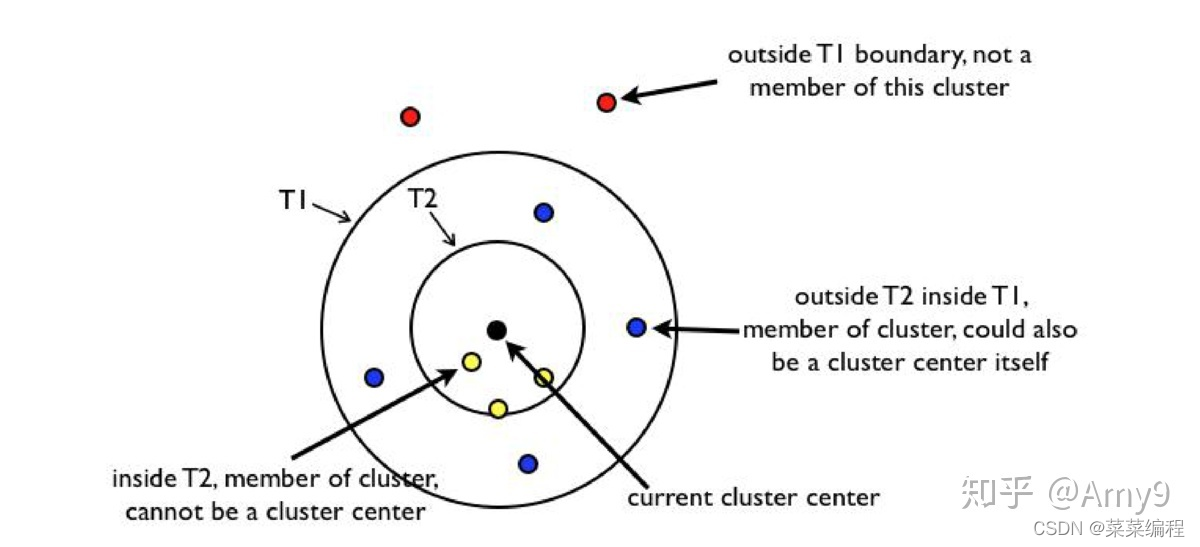
如下是之前数据选择T 1 = 2 3 d i s t ( m i n ( x ) , m a x ( x ) ) , T 2 = 1 2 T 1 T_1 = \frac{2}{3}dist(min(x),max(x)),\ T_2 = \frac{1}{2}T_1 T 1 =3 2 d i s t (m i n (x ),m a x (x )),T 2 =2 1 T 1 ,其中
m i n ( x ) = 每个特征最小值组成的新向量 m a x ( x ) = 每个特征最大值组成的新向量 \begin{aligned} min(x) & =\text{每个特征最小值组成的新向量}\ max(x) & = \text{每个特征最大值组成的新向量} \end{aligned}m i n (x )m a x (x )=每个特征最小值组成的新向量=每个特征最大值组成的新向量
这里你们需要自己去设计,我只是给出一个思路;若需要经常处理,可以将数据样本X \mathcal{X}X归一化后进行操作,来方便T 1 , T 2 T_1,T_2 T 1 ,T 2 的选择。按上述操作得到的效果图如下

3.聚类方法
3.1 K-means聚类
给定样本集合X = { x 1 , ⋯ , x n } \mathcal{X}={x_1,\cdots,x_n}X ={x 1 ,⋯,x n },K-means算法是最小化误差函数
min E = ∑ i = 1 k ∑ x ∈ X i ∥ x − u i ∥ 2 2 \min E = \sum_{i=1}^{k}\sum_{x\in\mathcal{X}_i}\|x-u_i\|_2^2 min E =i =1 ∑k x ∈X i ∑∥x −u i ∥2 2
其中u i u_i u i 是第i i i簇的中心(均值),K-means算法主要分为两步:
- 遍历X \mathcal{X}X,确定每个x x x的类别,
- 更新每一类的簇中心u i u_i u i ,
- 若u i u_i u i 没有改变则退出,否则循环2-3。
不足的地方在于初始的簇中心是X \mathcal{X}X中任选的k k k个数据点,使得最小化过程中容易陷入局部最小值中而停止更新簇中心,故有下面的K-means++ 算法。
3.2 K-means++聚类
与K-means不同的地方在于我们不任取簇中心,如果仅仅是完全随机的选择,有可能导致算法收敛很慢,或出现局部最小的情况;K-Means++算法就是对K-Means随机初始化质心的方法的优化。参考了前辈们的一些优化,修改了其中的一些表示错误
- 从样本数据X \mathcal{X}X中随机选择一个样本作为第一个簇中心u 1 u_1 u 1 ,
- f o r j = 2 , 3 , ⋯ , k for\ j=2,3,\cdots,k f o r j =2 ,3 ,⋯,k
- 遍历X \mathcal{X}X,计算每一个样本x x x到
已选择的簇中心的’距离’D ( x ) D(x)D (x ),计算方法如下
D ( x ) = min 1 ≤ r ≤ j − 1 ∥ x − u r ∥ 2 2 D(x) = \min_{1\leq r\leq j-1} \|x-u_r\|_2^2 D (x )=1 ≤r ≤j −1 min ∥x −u r ∥2 2 - 从中选择’距离’相对较远的样本点作为新的簇中心u i u_i u i ,即
u j = a r g max i D ( x i ) u_j =arg \max_{i} D(x_i)u j =a r g i max D (x i )
这么做的好处是使得初始各个簇中心离得相对的远,避免出现局部极小的情况出现。下图就是由于初始簇中心不好,陷入局部极小的情况中,红色点为停止迭代后的簇中心。(数据仅为展示效果而随机生成)

若采用Kmeans++选取初始簇中心,得到的结果如下图所示,显然可以避免局部极小的情况出现。

; 3.3 高斯混合聚类
高斯混合模型是一个假设所有的数据点都是生成于有限个带有未知参数的高斯分布所混合的概率模型。 我们可以将这种混合模型看作是 k-means 聚类算法的一种扩展使用 (注:kmeans必须要求cluster的模型是圆形的,不能是椭圆的) ,它包含了数据的协方差结构以及隐高斯模型的中心信息。
若采用sklearn中自带的GaussianMixture模块来实现,可以用其自带的 BIC(Bayesian Information Criterion,贝叶斯信息准则)来评估数据中聚类的数量。
3.3.1 BIC准则和AIC准则
AIC信息准则(Akaike information criterion)可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
A I C = − 2 ln L + 2 k AIC = -2\ln L+2k A I C =−2 ln L +2 k
其中k k k为参数数量,L L L是似然函数。找出最小AIC值对应的模型作为选择对象。
BIC准则(Bayesian Information Criterions)主要加大了惩罚项,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。
B I C = k ln n − 2 ln L BIC = k\ln n -2\ln L B I C =k ln n −2 ln L
其中n n n为样本数量,两者中的L L L 均为模型的拟合程度。这一块的内容有兴趣的同学可以另行学习。
3.3.2 高斯混合聚类的推导
注:本节阅读需要有概率论和最优化相关的基础。
假设所有数据点符合一个高斯分布,其密度函数
p ( x ∣ μ , Σ ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 exp ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x|\mu,\Sigma) = \frac{1}{(2\pi)^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}} } \exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))p (x ∣μ,Σ)=(2 π)2 n ∣Σ∣2 1 1 exp (−2 1 (x −μ)T Σ−1 (x −μ))
则定义如下的 高斯混合分布
p M ( x ) = ∑ i = 1 k α i p ( x ∣ μ i , Σ i ) p_{\mathcal{M}}(x) = \sum_{i=1}^{k}\alpha_ip(x|\mu_i,\Sigma_i)p M (x )=i =1 ∑k αi p (x ∣μi ,Σi )
其中α i > 0 \alpha_i>0 αi >0为第i i i个混合系数,且有∑ i = 1 k α i = 1 \sum_{i=1}^k \alpha_i=1 ∑i =1 k αi =1。这里故共有3 k 3k 3 k个参数,α i , μ i , Σ i \alpha_i,\ \mu_i,\Sigma_i αi ,μi ,Σi 。设z j ∈ { 1 , 2 , ⋯ , k } z_j\in{1,2,\cdots,k}z j ∈{1 ,2 ,⋯,k }表示生成样本x j x_j x j 的高斯混合成分, 先验分布有p ( z j = i ) = α i p(z_j = i) = \alpha_i p (z j =i )=αi ,其 后验分布为
p M ( z j = i ∣ x j ) = p ( z j = i ) p M ( x j ∣ z j = i ) p M ( x j ) = α i p M ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l p ( x j ∣ u l , Σ l ) . \begin{aligned} p_{\mathcal{M}}(z_j = i|x_j) & = \frac{p(z_j = i)p_{\mathcal{M}}(x_j|z_j = i) }{p_{\mathcal{M}}(x_j)} \ & = \frac{\alpha_i p_{\mathcal{M}}(x_j|\mu_i,\Sigma_i) }{\sum_{l=1}^{k}\alpha_lp(x_j|\,u_l,\Sigma_l)} \end{aligned}.p M (z j =i ∣x j )=p M (x j )p (z j =i )p M (x j ∣z j =i )=∑l =1 k αl p (x j ∣u l ,Σl )αi p M (x j ∣μi ,Σi ).
简写为γ j i , i = 1 , ⋯ , k \gamma_{ji},i = 1,\cdots,k γj i ,i =1 ,⋯,k。每个样本x j x_j x j 所属的类为λ j \lambda_j λj
λ j = arg max i ∈ { 1 , ⋯ , k } γ j i \lambda_j = \arg \max_{i\in{1,\cdots,k}} \gamma_{ji}λj =ar g i ∈{1 ,⋯,k }max γj i
采用极大似然估计求解参数α i , μ i , Σ i \alpha_i,\ \mu_i,\Sigma_i αi ,μi ,Σi ,这一块的内容可以查看 概率论或 最优化理论,其对数似然函数
max L = ln ( ∏ j = 1 n p M ( x j ) ) = ∑ j = 1 n ln ( ∑ i = 1 k α i p ( x ∣ μ i , Σ i ) ) s . t . ∑ i = 1 k α i = 1 , α i > 0 \begin{aligned} \max L & = \ln \left( \prod_{j=1}^n p_{\mathcal{M}}(x_j) \right)\ & = \sum_{j=1}^n \ln \left( \sum_{i=1}^{k}\alpha_ip(x|\mu_i,\Sigma_i) \right)\ s.t. &\quad \sum_{i=1}^k \alpha_i =1,\quad \alpha_i>0 \end{aligned}max L s .t .=ln (j =1 ∏n p M (x j ))=j =1 ∑n ln (i =1 ∑k αi p (x ∣μi ,Σi ))i =1 ∑k αi =1 ,αi >0
这类问题利用拉格朗日乘子法可得
L L = L + λ ( ∑ i = 1 k α i − 1 ) LL = L+\lambda\left( \sum_{i=1}^k \alpha_i -1 \right)L L =L +λ(i =1 ∑k αi −1 )
然后求偏导令∂ L L ∂ μ i = 0 , ∂ L L ∂ Σ i = 0 , ∂ L L ∂ α i = 0 \frac{\partial LL}{\partial \mu_i} = 0,\ \frac{\partial LL}{\partial \Sigma_i} = 0,\ \frac{\partial LL}{\partial \alpha_i} = 0 ∂μi ∂L L =0 ,∂Σi ∂L L =0 ,∂αi ∂L L =0,这里是 高数中的内容,自己可以尝试推,可得
μ i = ∑ j = 1 n γ j i x j ∑ j = 1 n γ j i , Σ i = ∑ j = 1 n γ j i ( x j − μ i ) ( x j − μ i ) T ∑ j = 1 n γ j i , α i = 1 n ∑ j = 1 n γ j i , λ = − n . \begin{aligned} \mu_i &= \frac{\sum_{j=1}^n \gamma_{ji} x_j }{\sum_{j=1}^n\gamma_{ji}},\ \Sigma_i & = \frac{\sum_{j=1}^n\gamma_{ji}(x_j-\mu_i)(x_j-\mu_i)^T}{\sum_{j=1}^n\gamma_{ji}},\ \alpha_i & = \frac{1}{n}\sum_{j=1}^n\gamma_{ji},\ \lambda & = -n. \end{aligned}μi Σi αi λ=∑j =1 n γj i ∑j =1 n γj i x j ,=∑j =1 n γj i ∑j =1 n γj i (x j −μi )(x j −μi )T ,=n 1 j =1 ∑n γj i ,=−n .
3.3.3 高斯混合聚类的步骤
- 初始化参数α i , μ i , Σ i \alpha_i,\mu_i,\Sigma_i αi ,μi ,Σi
- 遍历样本x j x_j x j ,计算样本x j x_j x j 有第i i i个高斯混合成分生成的 后验概率γ j i \gamma_{ji}γj i ,
- 遍历类,根据上式更新参数α i , μ i , Σ i \alpha_i,\mu_i,\Sigma_i αi ,μi ,Σi ,
- 若参数收敛,则停止,否则继续2-3,
- 根据x j x_j x j 的后验分布,确定x j x_j x j 的所属类λ j = arg max i γ j i \lambda_j = \arg \max_{i} \gamma_{ji}λj =ar g max i γj i .
下面是官方给出的利用BIC准则得到效果图,m o d e l = f u l l model = full m o d e l =f u l l时k = 2 k=2 k =2时最好的,f u l l full f u l l的意思是返回k k k个协方差矩阵,椭圆各轴不等,斜向。

; 3.4 密度聚类(DBSCAN)
相对于之前的Kmeans或之前的kmeans++采用 闵可夫斯基距离(Minkowski distance),密度聚类采用的是 密度稠密的方法。数学类的同学可以比较熟悉 邻域这个名词来说明某些紧密的程度。 优点是不需要事先给定聚类数目。
3.4.1 前提回顾
DBSCAN是基于一组邻域(ϵ , M i n P t s \epsilon,MinPts ϵ,M i n P t s),ϵ \epsilon ϵ在一维下表示长度为2 ϵ 2\epsilon 2 ϵ的线段,二维下表示半径ϵ \epsilon ϵ的圆,三维下表示半径ϵ \epsilon ϵ的球……后者表示最小样本数,下面引出相关的几个概念
- ϵ \epsilon ϵ-邻域:样本x j x_j x j 的ϵ \epsilon ϵ-邻域为与x j x_j x j 的距离小于ϵ \epsilon ϵ的样本集,N ϵ ( x j ) N_{\epsilon}(x_j)N ϵ(x j )
- 核心对象:若ϵ \epsilon ϵ-邻域内
足够密集的x j x_j x j ,N ϵ ( x j ) ≥ M i n P t s N_{\epsilon}(x_j)\geq MinPts N ϵ(x j )≥M i n P t s - 密度直达:x i x_i x i 在x j x_j x j 的ϵ \epsilon ϵ-邻域内,x i x_i x i 由x j x_j x j 密度直达,
注:可密度直达但不一定是核心对象,需要较为密集才是。 - 密度可达:虽然不在ϵ \epsilon ϵ-邻域内(密度直达),但可以通过一系列密度直达的样本{p m p_m p m }相联系
- 密度相连:若x i x_i x i 与x k x_k x k 密度可达,x j x_j x j 与x k x_k x k 密度可达,则称x i x_i x i 与x j x_j x j 密度相连。

大白话说明:想象成一个楼梯样本,每一台阶即一个样本,ϵ \epsilon ϵ为相邻两个台阶的距离,若M I n P t s = 3 MInPts=3 M I n P t s =3,则除了楼底和楼顶两个台阶,皆为核心对象;这是因为中间台阶与其上下两个台阶都与该台阶ϵ \epsilon ϵ相邻。相邻台阶为密度直达,任意两个台阶都密度可达,前密度相连。
; 3.4.2 目睹聚类的步骤
显然,该方法的思想就是将密度可达的样本归为一类。主要是以核心对象出发,可以思考一下:从核心对象出发,由密度可达中可以找到最大的X \mathcal{X}X的样本集。算法流程如下
- 找到样本集X \mathcal{X}X中的所有核心对象Ω \Omega Ω,
- 取Ω \Omega Ω一核心对象ω \omega ω,找到在X \mathcal{X}X中与ω \omega ω密度可达的所有样本构成类C k C_k C k
- 令X = X \ C k , Ω = Ω \ C k , k = k + 1 \mathcal{X} = \mathcal{X} \backslash C_k,\quad \Omega = \Omega\backslash C_k,\quad k = k+1 X =X \C k ,Ω=Ω\C k ,k =k +1
-
直到Ω = ∅ \Omega = \empty Ω=∅,否则重复2-3.
-
将X \mathcal{X}X中剩余的样本标记为噪声样本。
3.4.3 月牙数据聚类据结果
这里采用月牙数据,选择 $\epsilon = 0.11, MinPts = 10$,得到下图的聚类结果,黑色点为噪声样本,分布在各类区域的周围,这也很容易从 密度可达的定义中得到解释。样本数据具体细节看代码中设置。

; 3.4.4 DBSCAN算法的优缺点
优点:可以看出当数据”缠绕”在一起时,当用kmeans聚类往往得到不实际的效果,自己可以试一试,要么需要先通过坐标变换后再用Kmeans,但一般情况下坐标变换我们不是轻易能找到的,DBSCAN算法可以减少我们试错的时间而得较高精确的结果。
缺点:从中我们可以发现DBSCAN密度聚类虽然不需要额外指定聚类簇数目k k k,但需要合理的参数ϵ \epsilon ϵ和M i n P t s MinPts M i n P t s,也需要根据实际情况去设置。
3.5 层次聚类(AGNES)
这里先给出层次聚类在四种策略下处理各种各样数据时的分类效果。

; 3.5.1 聚类簇间距离
AGNES算法是一种自底向上聚合策略的层次聚类算法,先将数据中每个样本数据自己看做一个簇,随后根据距离最小找出最小距离的合并为一个簇, 直至到达预设的聚类簇个数。
d m i n ( C i , C j ) = min x ∈ C i , z ∈ C j d i s t ( x , z ) d m a x ( C i , C j ) = max x ∈ C i , z ∈ C j d i s t ( x , z ) d a v g ( C i , C j ) = 1 ∣ C i ∣ ∣ C j ∣ ∑ x ∈ C i ∑ z ∈ C j d i s t ( x , z ) \begin{aligned} d_{min}(C_i,C_j) & = \min_{x\in C_i, z\in C_j}dist(x,z)\ d_{max}(C_i,C_j) & = \max_{x\in C_i, z\in C_j}dist(x,z)\ d_{avg}(C_i,C_j) & = \frac{1}{|C_i||C_j|}\sum_{x\in C_i}\sum_{z\in C_j} dist(x,z) \end{aligned}d m i n (C i ,C j )d m a x (C i ,C j )d a v g (C i ,C j )=x ∈C i ,z ∈C j min d i s t (x ,z )=x ∈C i ,z ∈C j max d i s t (x ,z )=∣C i ∣∣C j ∣1 x ∈C i ∑z ∈C j ∑d i s t (x ,z )
依次分别称为”单链接”(single-linkage),”全链接”(full-linkage),”均链接”(average-linkage)。而Ward-linkega是采用离差平方和E S S ESS E S S来归并类别的,
E S S ( C i ) = ∑ x ∈ C i x 2 − 1 ∣ C i ∣ ( ∑ x ∈ C i x ) 2 ESS(C_i) = \sum_{x\in C_i} x^2-\frac{1}{|C_i|}\left( \sum_{x\in C_i} x \right)^2 E S S (C i )=x ∈C i ∑x 2 −∣C i ∣1 (x ∈C i ∑x )2
其实这就是∣ C i ∣ V a r ( C i ) |C_i|Var(C_i)∣C i ∣V a r (C i ),总的离差平方和
E S S K = ∑ i = 1 K E S S ( C i ) ESS_K = \sum_{i=1}^{K}ESS(C_i)E S S K =i =1 ∑K E S S (C i )
ward-linkega是要求每次合并后ESS的增量最小,这怎么讲呢?首先有(这是显然的)
E S S ( C i ∪ C j ) > E S S ( C i ) + E S S ( C j ) ESS(C_i\cup C_j) >ESS(C_i)+ESS(C_j)E S S (C i ∪C j )>E S S (C i )+E S S (C j )
我们要找出使得E S S ( C i ∪ C j ) − ( E S S ( C i ) + E S S ( C j ) ) ESS(C_i\cup C_j) -\left(ESS(C_i)+ESS(C_j) \right)E S S (C i ∪C j )−(E S S (C i )+E S S (C j ))最小的两个簇C i C_i C i 和C j C_j C j 合并为一类。
当前三种距离时,我们是找出 距离最近的两个簇C i C_i C i 和C j C_j C j 进行合并。由于这是一个组合问题,在最初的时候(n n n为样本量)有n ( n − 1 ) 2 \frac{n(n-1)}{2}2 n (n −1 )中组合,有一些快速方法去提高这个效率,这里不做赘述。
3.5.2 层次聚类的步骤
- X \mathcal{X}X中每个样本归为一类C i , i = 1 , 2 , ⋯ , n C_i,i = 1,2,\cdots,n C i ,i =1 ,2 ,⋯,n,计算距离矩阵M ∈ R n × n M\in\mathbf{R}^{n\times n}M ∈R n ×n,
- 找到距离最近的两个类C i ∗ C_{i^}C i ∗和C j ∗ C_{j^}C j ∗并合并,记为C i ∗ C_{i^*}C i ∗
- 将第j ∗ j^j ∗类后的类重新编号为j ∗ − 1 j^-1 j ∗−1,
- 部分更新距离矩阵M M M;
- 当类别数= k =k =k时停止,否则继续2-4。
3.5.3 层次聚类的效果
层次聚类理解较为简单,但是算法效率低下,下面给出一个环形数据的聚类结果,

; 4. 终极武器
还是得加强算法的理解以及程序的上手,好好理解。本人能力有限,如果文中有不对的地方,感谢指出,如果对您有帮助,请动动您可爱的小手,点个小小的赞,感谢。

4.1 python代码
由于采用jupyter编写,其中有数据图可以直接参看,故放在压缩包中,一定会给你惊喜的!百度网盘链接如下
链接:https://pan.baidu.com/s/1bpz-dwVN54U1Ma7WzQWDnw
提取码:mqsq
Original: https://blog.csdn.net/qq_45153782/article/details/124438407
Author: 菜菜编程
Title: 聚类数k的确定(间隔统计量,轮廓系数,Canopy算法)及Kmeans++聚类,高斯混合聚类,密度聚类,层次聚类的原理及python实现(文末附有相关代码)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549740/
转载文章受原作者版权保护。转载请注明原作者出处!